某办公楼里,Kim每天戴着VR头盔重复折衣服、开微波炉几百次
旁边的机器人每天学他的动作
这些数据会被送到机器人公司做AI训练
Kim拿一份工资,然后数据就跟他没关系了
全国已经有40个这样的训练中心
数千个Kim在产生机器人最需要的东西:真实的世界交互数据与信息
但没有人在问那个真正重要的问题:
这些数据产生的价值,凭什么只能被公司拿走?

@Fabric Foundation 给了我想要的答案
机器人训练数据,是2026年最稀缺的资产
语言模型可以爬互联网,图片模型可以抓YouTube
机器人不行
它需要的是在真实的世界里真实发生的每一个动作
这些东西网上找不到,只能靠人一遍遍地做出来
所以数据荒是真实的
Scale AI今年收集了10万小时机器人动作数据,行业普遍说还不够
谁控制数据,谁就控制最聪明的机器人
数据正在变成新的垄断手段
Fabric在这里做的事,是在建一套不同的规则
具体说$ROBO 的数据贡献机制
在Fabric网络里,数据贡献是链上可记录的
谁提供了什么数据
被机器人调用了多少次
质量评分多少
每一条都在链上,公开可验证,任何人都可以查
这意味着两件事
第一,数据的价值不会消失进公司服务器变成我们不可探究的数据
第二,数据产生的收益可以持续分配——每一次被机器人调用,都可以触发一笔$ROBO结算
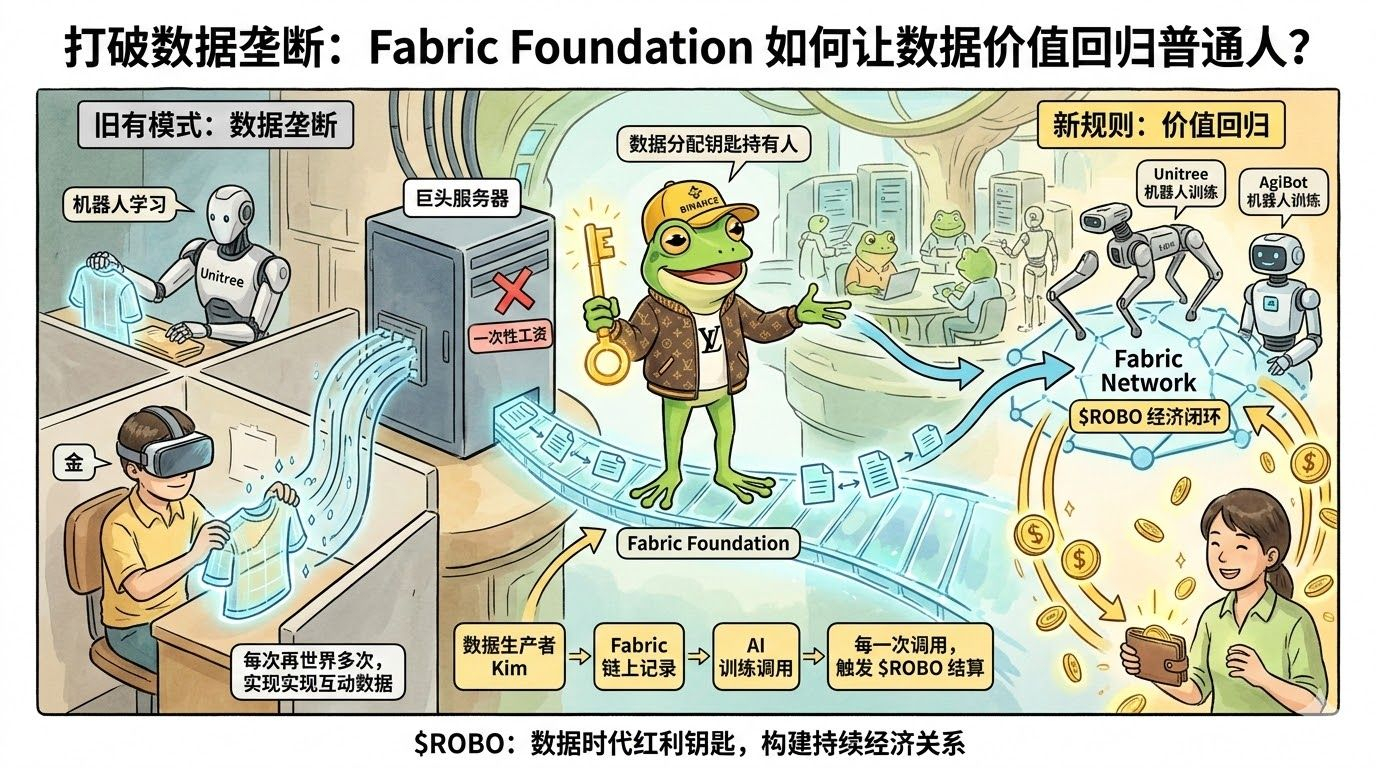
Kim提供的那批折衣服动作数据
每次被Unitree或者AgiBot的机器人调用来训练
链上都有记录,都有对应的$ROBO奖励打进他的钱包
这不是一次性买卖
这是Kim和他的数据之间,建立了一种持续的经济关系
再说ROBO在这套机制里的位置
它不是单纯的结算通证
它是整个数据市场的权限钥匙
机器人运营商想访问网络里的数据资源,需要持有并质押ROBO
开发者想在Fabric上构建技能模块,需要买入ROBO作为准入门槛
贡献数据的人获得ROBO奖励,这批奖励又会被下一个需要数据的运营商买走
这形成了一个真实的经济闭环:
数据贡献 → ROBO奖励→运营商买入ROBO奖励 → 运营商买入
ROBO奖励→运营商买入ROBO访问数据 → 产生协议收入 → 回购ROBO
每一笔真实发生的数据交易
然后说Adaptive Emission Engine
这是ROBO的发行机制,很多人都不了解,但我知道
它不是固定释放
而是根据两个实时信号动态调整:
网络实际使用率(收入 vs 机器人容量)和服务质量评分
网络空闲的时候,多发ROBO吸引更多节点和数据贡献者进来
服务质量下降的时候,减少发放倒逼标准提升
每个周期变化幅度上限5%,防止市场大幅震荡
这个机制的核心逻辑是:
ROBO的供给会自动跟网络的真实需求校准
不会出现"网络没人用但通胀照常跑"的情况
对持有者来说,这意味着ROBO的稀缺性不是人为设定的
是由网络真实活动决定的
说完好处,另一面也要说清楚
数据贡献激励Q2才上线,现在还没有跑起来
防止"数据农场"刷低质量数据的反作弊机制,目前细节不透明
44%的代币要到2027年2月才开始解锁,那批筹码的供给压力是真实的
Fabric现在是一张正在铺设的网
Kim这样的数据贡献者还没有真正接入
数据市场的闭环还没有形成
机器人训练数据的战争已经打响
国家在建训练中心,大厂在囤数据,学界在喊数据荒
最后会产生两种结果:
要么数据被少数几个巨头垄断,要么有一套开放的机制让数据自由流通
Fabric在做的,是第二种结果的基础设施
如果Q2的贡献激励真的跑起来
如果数据市场的闭环真的形成
#ROBO 装的不只是机器人经济的燃料
是数据时代里,普通人能参与分配的那把钥匙
这个钥匙值不值这个价