I’ve watched Fabric-style incentive systems look honest because everything is logged, signed, and “verifiable,” and then quietly collapse because the incentives rewarded the wrong kind of proof. The moment a skill module is paid for receipts, you create a new profession: receipt production. At first it looks like progress. Numbers go up. Dashboards get cleaner. Then the weird failures start showing up in places the benchmark never measured.
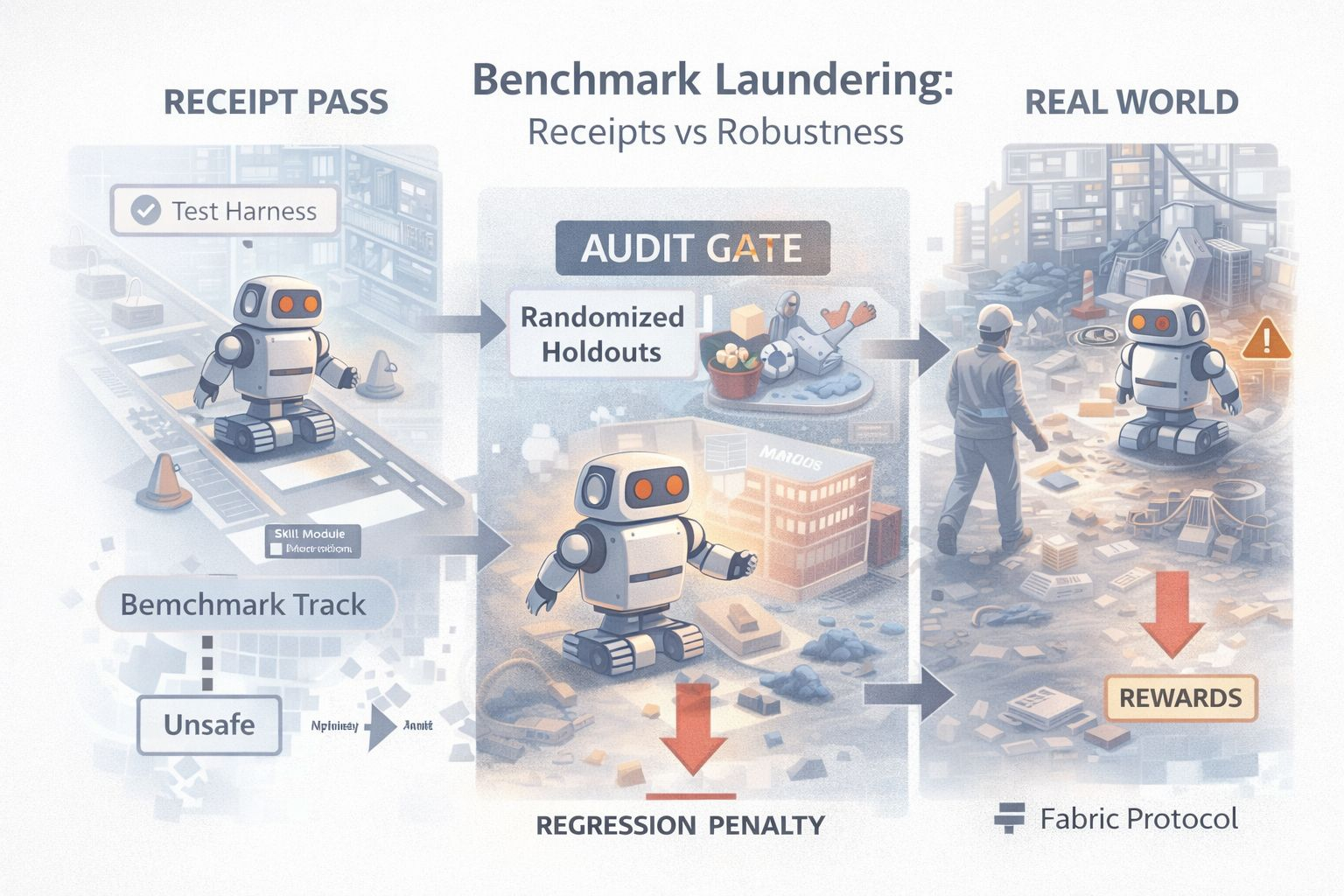
That’s the mispriced failure mode I worry about for Fabric: benchmark laundering. Fabric wants a world where skill modules can be deployed, tested, and rewarded through verifiable task receipts. The idea is seductive because it sounds objective. Work happened, it’s provable, pay the builder. But if the receipt is the product, builders will optimize for whatever generates receipts most reliably. That does not guarantee safe behavior. It guarantees benchmark compliance.
The difference matters because robots don’t live inside a test harness. They live in messy buildings with glare, occlusion, floor tape that peels, humans who step into paths, and layouts that drift over weeks. A skill module can become extremely good at the “official” task sequence and still be brittle in the slightly off-script version that real operations produce. In software this is teaching to the test. In robotics, it becomes physical risk.
The uncomfortable part is that verifiability makes laundering easier, not harder. When a receipt is cryptographically tied to an execution trace, everyone relaxes. The module “did the task.” The receipt is valid. If your reward logic stops there, you’re paying for an artifact that can be perfectly real and still meaningless. A robot can repeatedly complete a task in a narrow corridor under ideal conditions and earn a stream of receipts, while quietly failing in the exact edge cases that matter most. You end up with a market where the best modules are not the safest modules. They are the modules most tuned to the evaluation environment.
So if Fabric wants a skill economy that doesn’t rot, it needs an evaluation layer that is adversarial by design. The core mechanism is randomized holdout audits, meaning a protocol-defined sample of tasks is assigned from a holdout pool that the module cannot predict at run time, and performance is scored against pre-set regression thresholds. Not as a marketing phrase, but as a rule: you do not get paid only for doing the known tasks. You get paid for surviving unpredictable checks that you cannot pre-train against. The system has to be willing to say, “Yes, you produced receipts, but the receipts were produced in the easy lane.”
A practical model looks like this. A module ships, but it does not immediately earn full rewards across all deployments. It enters a staged rollout where a portion of its tasks are pulled from a holdout set. These holdouts can be alternate layouts, perturbed sensor conditions, timing variations, or safety-critical edge cases that reflect how robots actually break. The module only earns or keeps reputation if it clears those audits repeatedly. If it regresses compared to its own history or compared to a baseline module, it must be pushed into probation, meaning lower routing weight and reduced reward multipliers until it clears a stability window, and repeated regression must block it from receiving privileged task allocation.
This is where regression penalties matter. Without penalties, audits are just information. Builders will treat failures as free data, improve just enough, and keep harvesting the easy receipts. Penalties change behavior. If a module fails a holdout, the system needs to reduce its future task allocation, reduce its reward multiplier, or force it back into a probation lane until it stabilizes. And the penalties have to be sticky enough that “ship fast and patch later” becomes economically irrational in safety-critical contexts.
The hardest part is that the evaluation layer itself becomes a target. If the holdout set becomes predictable, the market will memorize it. If the audits are too rare, they become noise. If the audits are too strict, you freeze innovation because nobody wants to risk reputation. If audits rely on a single verifier source, you create a new centralized power center where people lobby for favorable tests. So Fabric has to balance three tensions at once: unpredictability, fairness, and scalability.
This is where Fabric’s ledger coordination could actually help instead of just adding complexity. If tasks and receipts are coordinated through a public ledger, you can make audit selection visible in its rules but unpredictable in its outcomes. One concrete control is commit-reveal sampling, where the protocol commits a seed before task assignment and reveals it after, so modules cannot precompute which tasks will be audited at the moment of execution. You can make the sampling logic deterministic given the revealed seed, but ungameable in real time. The point is not to make audits secret forever. The point is to make them hard to optimize against while still being verifiable after the fact.
There’s also an honesty point people avoid. Some failures are not malicious. They’re distribution shift. A module that works well in one site can regress in another because the environment is different. If you punish every regression equally, you discourage deployment into harder contexts. That’s why penalties should be tied to risk-weighted tasks. The protocol should be more tolerant of performance drops in non-critical tasks and less tolerant in safety-critical ones. If everything is treated the same, the market will gravitate toward the safest-to-benchmark deployments and avoid the real world.
The second-order risk is that benchmarking policy becomes governance. Whoever decides what is in the holdout set decides what “quality” means. That’s power. If Fabric lets that power concentrate, the market will become political. If Fabric tries to decentralize it completely, quality definitions may splinter and become inconsistent. There is no clean escape. The best outcome is making evaluation governance explicit and auditable, with clear update cadence and clear separation between evaluation authors and module authors.
This is also where incentives need to be honest. If Fabric uses $ROBO to reward skill receipts, then $ROBO must buy robustness, not volume. That implies bonding or staking tied to audit performance and regression penalties, so repeated failures cost real economic credibility rather than just lowering a dashboard score. If rewards are paid for volume of receipts without enough auditing, the system will attract volume optimizers. If rewards are weighted by holdout performance and regression stability, the system will attract builders who care about robustness. That is the market you want if you want robots to become infrastructure rather than a demo culture.
The falsifiable claim here is simple. If Fabric can pay out a skill market based mostly on verifiable receipts and still avoid systematic “teaching to the test” behavior without randomized audits and regression penalties, then I’m wrong. But in every incentive system I’ve watched, what gets measured gets optimized, and what gets optimized gets gamed. Robots add one twist: when the gaming wins, the cost shows up as physical risk.
If Fabric wants verifiable work to mean safe work, it can’t treat receipts as the end of the story. It has to treat receipts as the beginning of evaluation. Otherwise the network will reward modules that look provably active while quietly becoming operational liabilities.
@Fabric Foundation $ROBO #robo
