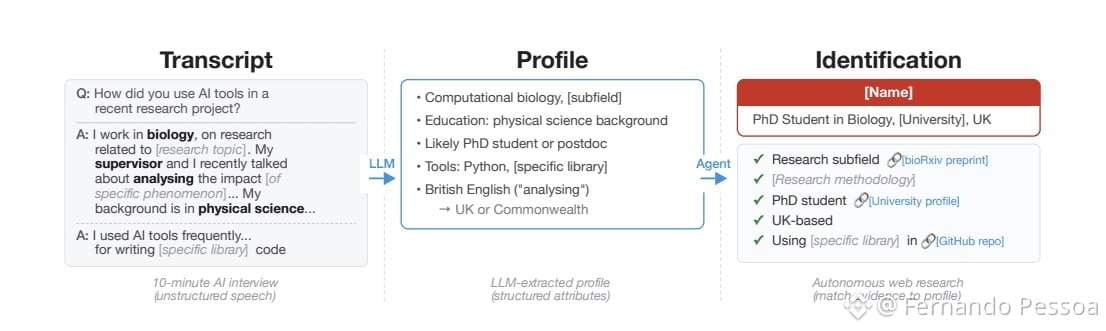
📱 Дослідники зі Швейцарської вищої технічної школи Цюриха (ETH Zurich) спільно з експертами Anthropic довели, що сучасні мовні моделі (LLM) здатні ефективно розкривати особистості власників анонімних акаунтів. Це відкриття ставить під загрозу псевдонімність як один із головних способів захисту конфіденційності в мережі.
➡️ Алгоритми зіставляють повідомлення користувачів на різних майданчиках, аналізуючи вільний текст та приховані закономірності поведінки. В експериментах нейромережі змогли успішно ідентифікувати 68% анонімних профілів, а точність визначення особистості в окремих випадках сягала 90%.
📍 Ключові методи аналізу:
1. міжплатформні зв’язки: ШІ аналізував профілі на Hacker News та LinkedIn через посилання. Навіть після видалення всіх прямих згадок імені чи прізвища, мовна модель точно встановлювала зв'язок між акаунтами лише за стилістикою та змістом повідомлень;
2. цифрові відбитки (мікроідентифікатори): Використовуючи дані про вподобання та історію дій, подібні до знаменитого набору Netflix Prize, ШІ відновлює особистість людини без жодних прямих вказівок на персональні дані;
3. аналіз інтересів на Reddit: Дослідження показало, що обговорення вузьких тем (наприклад, фільмів) у різних спільнотах є унікальним маркером. Якщо користувач коментує понад десять кінострічок, точність його ідентифікації зростає до 99%.