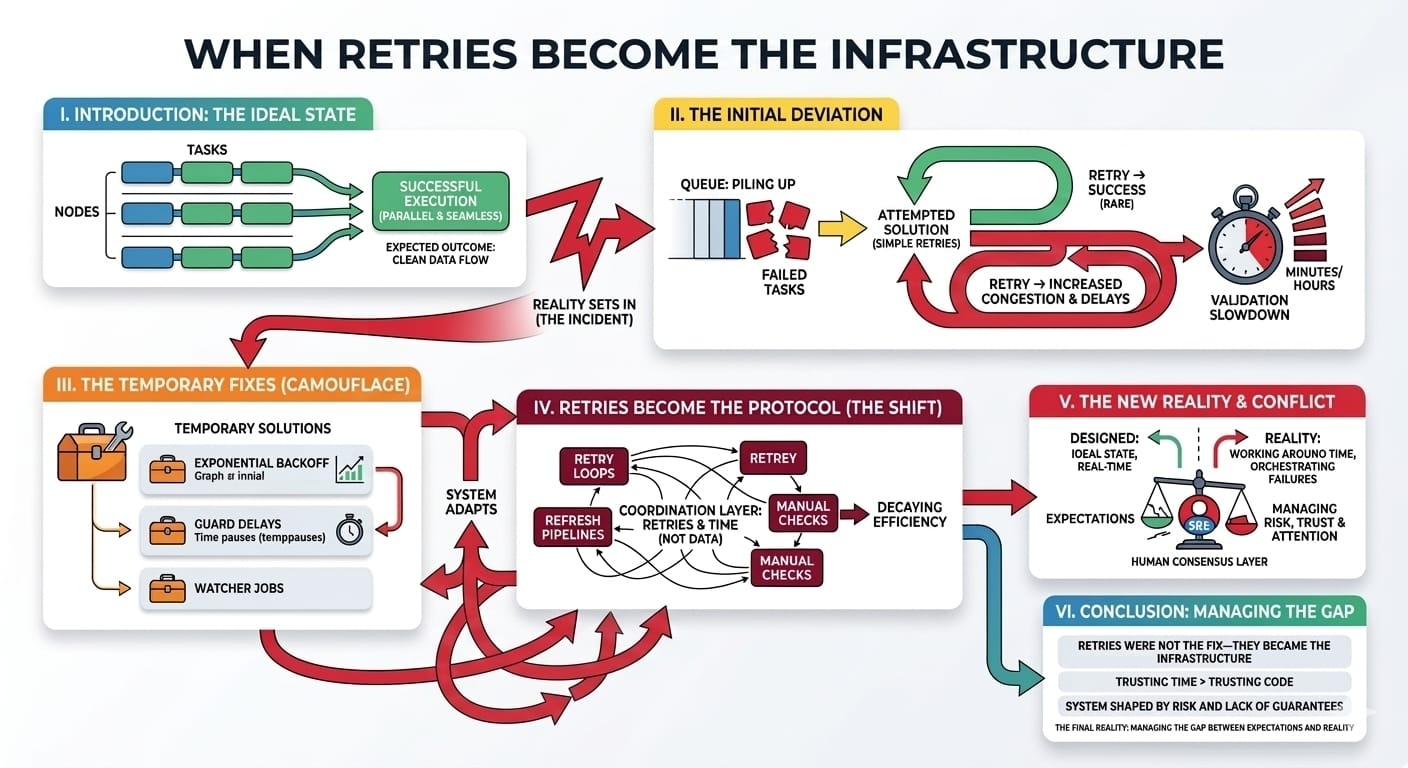
It started with a simple operational task. We had a series of automated transactions scheduled to run across multiple nodes in a decentralized Web3 network. Everything was set up to process in parallel. Our expectation was that once the task was triggered, it would execute cleanly—each node would confirm the transaction, the block would validate, and the state would update seamlessly. Nothing special, just another routine operation.
But, as usual, things didn’t go exactly as planned.
Instead of executing smoothly, the jobs began piling up in the queue. Some tasks would fail intermittently—unpredictably, but often enough to disrupt the flow. We had expected the retries to work as designed: every failed task would be re-attempted after a brief delay, eventually clearing out any blockage. Instead, retries started to act as their own form of congestion. Instead of resolving failures, they compounded the load. The system became sluggish, and the delay between transactions—previously unnoticeable—grew. Even the time it took to verify one simple transaction increased by minutes, making everything feel much slower.
The task that was supposed to take seconds now stretched into hours. Not only that, but the nodes responsible for validation started responding slower. These retries weren't just a safety net anymore; they were becoming the protocol itself. There was a fundamental shift happening in how we thought the system should behave.
The system we had designed expected that once a transaction failed, it could just retry until the state updated. But in production, the retries started to drift, diverging from the simple, “retry until success” model we had envisioned. The retries themselves started to influence the system’s state, and not in a positive way. What had been an occasional, rare event became a constant backdrop. It felt like a subtle failure was being camouflaged by the retries, but no one really noticed until the system got slower and slower.
In those early stages, the fixes came quickly. We added retries with exponential backoff, hoping that reducing the frequency would allow the system to recover gracefully without overwhelming it. We also added guard delays—small pauses before new tasks were initiated, trying to ensure the state was fully synchronized before executing again. It felt like a reasonable solution, at least at first.
But as the system grew, we realized that these fixes weren't solving the underlying issue. They were just treating the symptoms, and frankly, doing so in a way that was starting to obscure the real problem. Instead of addressing the causes of failure, we were delaying the inevitable. Guard delays, retries, and exponential backoffs started becoming woven into the fabric of the system itself. They were no longer just supplementary tools. They were becoming the unofficial protocol for how the system operated.
It was like the retries themselves had become the new coordination layer. We weren't coordinating nodes or data anymore; we were coordinating retries. We weren't managing tasks so much as managing time and the constraints around how much time we could afford to waste before a transaction was considered "complete." The retries were shaping the system, defining how it behaved in ways we hadn’t fully anticipated.
The real coordination point was no longer the transaction itself, but the time spent waiting for it. Each retry, each guard delay, each watcher job we added to monitor the process, were all small pieces contributing to the coordination of time. The work became less about verification and more about ensuring that enough time had passed for the system to be reasonably confident the process would eventually complete. In some ways, retries started feeling like a buffer for handling risk—acknowledging that failures could happen, but that time would eventually resolve most of the issues. It was as if we were trusting the passage of time more than the code itself.
I began to notice that this shift was happening everywhere. It wasn’t just retries anymore. We started adding refresh pipelines, tasks that would recheck previous stages to ensure that stale data didn’t cause issues down the line. Then, manual checks—simple scripts run by the engineers themselves—became a standard part of the workflow. What we had initially thought of as an automated system quickly became a hybrid of automation and human oversight, with each retry loop acting as a manual intervention. It was as if automation had slipped into a state where the only way to ensure success was by adding more layers of automation that could react to the very failures the first automation layer was supposed to prevent.
At some point, it became clear that we weren’t really automating the system at all. We were just orchestrating failures. Every retry was a failed opportunity for a clean execution. And the system, which had been designed to work in real time, was now designed to work around time, constantly manipulating its own clock to make up for the fact that things weren’t happening as quickly as they were supposed to. Time was no longer just a part of the system; it was the system itself.
And that's when the frustration really hit me: the system had started relying on all the fixes that were supposed to be temporary. The retries, the guard delays, the manual checks—they weren’t just fixing things. They were becoming the reality of the system. What had once been a set of rules was now a patchwork infrastructure of layers designed to mask how broken the flow was. It was as if the fixes themselves had become the final consensus mechanism for the network. If a task could go wrong, it would; and we would rely on a system of retries, manual interventions, and time buffers to make sure it eventually "worked."
This forced me to rethink what the system was actually coordinating. It wasn’t just coordinating tasks, validation, or state updates. It was coordinating risk, trust, and attention. Each retry wasn’t just a chance for the task to succeed; it was an acknowledgment that we weren’t entirely trusting the system to get things done without intervention. In some ways, it was the humans on the other side of the retries that were becoming the true final consensus layer.
And that's the uncomfortable truth about distributed systems, especially in the Web3 world: it’s not always the technology that's the bottleneck. It’s the lack of guarantees around it. The automation, the retries, the safety nets—those aren’t there to make things run smoothly. They’re there to protect us from the reality that things don’t always work as they should.
In the end, the retries didn’t just become part of the infrastructure. They were the infrastructure. And it’s a reminder that no matter how elegant the system seems, there’s always something in the background quietly managing risk, time, and trust in ways you didn’t expect. The infrastructure isn’t just about execution anymore. It’s about managing the gaps between expectations and reality.#ROBO @Fabric Foundation $ROBO