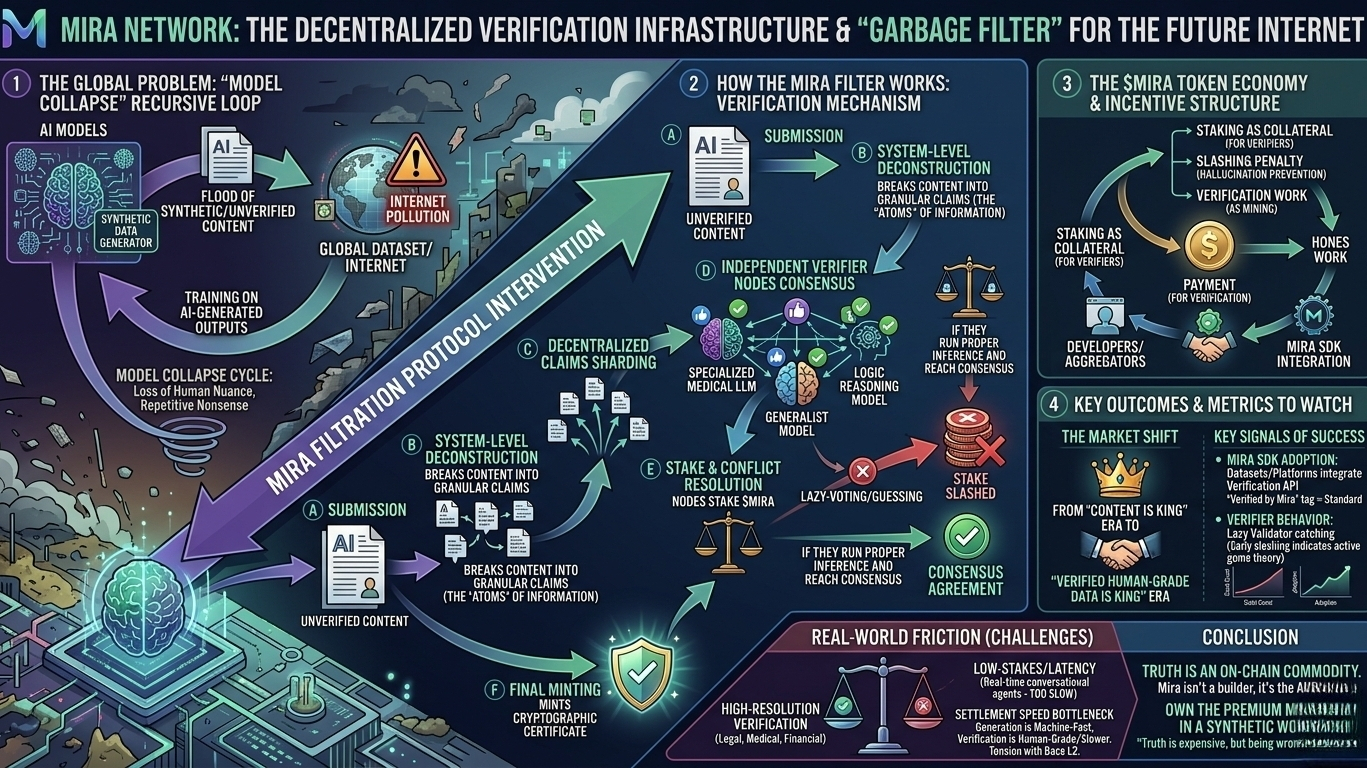
Spędziłem większość swojego poranka dzisiaj, przeglądając najnowsze badania na temat "Zapaści Modeli", i szczerze mówiąc, jest to znacznie bardziej przerażające niż typowa narracja "AI odbierze nam pracę". Jeśli jeszcze nie widziałeś tego terminu, to zjawisko, w którym modele AI zaczynają trenować na wynikach innych modeli AI. Ponieważ internet jest obecnie zalewany syntetycznymi, niezweryfikowanymi i nieco "dziwnymi" treściami, wkraczamy w rekurencyjną pętlę. Modele w zasadzie się rozmnażają, tracąc "końce" ludzkich niuansów, i ostatecznie przekształcają się w papkę powtarzalnych, pewnych nonsensów.
To jest miejsce, gdzie uważam, że rynek całkowicie przegapia sens sieci Mira.
Większość ludzi patrzy na Mirę jako na kolejną zdecentralizowaną grę AI—sposób na uzyskanie "tańszych" lub "zdecentralizowanych" odpowiedzi. Ale po dzisiejszym zagłębieniu się w ich mechanizm weryfikacji, zrozumiałem, że to błędna perspektywa. Mira nie chodzi naprawdę o tworzenie AI; chodzi o działanie jako wysokiej rozdzielczości filtr, który zapobiega całemu ekosystemowi danych AI zapadnięciu się pod własnym ciężarem.
Teza
Prawdziwa wartość Mira nie leży w generowaniu treści, ale w Dowodzie Pochodzenia. W miarę jak syntetyczne dane zanieczyszczają globalny zbiór treningowy, świat przechodzi z ery "Treść jest Królem" do ery "Zweryfikowane Dane Ludzkiej Klasy są Królem". Mira jest pierwszą infrastrukturą, którą widziałem, która traktuje "Prawdę" jako udowodniony, on-chain towar poprzez mechanizm, który naprawdę może skalować.
Jak działa filtr
Jeśli spojrzysz na dokumenty, rdzeniem Mira nie jest pojedynczy model "sędziego". To byłby tylko scentralizowany wąskie gardło. Zamiast tego, to dekonstruowanie na poziomie systemowym.
Kiedy AI (lub człowiek) składa wynik, protokół Mira nie patrzy tylko na cały akapit i nie mówi "wygląda dobrze." Rozbija treść na granularne, niezależne roszczenia. To są "atomy" informacji. Te roszczenia są następnie shardowane—wysyłane do zdecentralizowanej sieci niezależnych weryfikatorów.
Tutaj robi się interesujące z perspektywy mechanizmu: te węzły nie działają wszystkie na tym samym modelu. Są zróżnicowane. Jeden może być specjalizowanym modelem medycznym LLM, inny ogólnym, inny modelem ciężko logicznym. Wszyscy głosują.
Ale rozmowy są tanie w kryptowalutach, więc Mira zmusza ich do zaangażowania się. Aby być weryfikatorem, musisz zainwestować $MIRA. Jeśli próbujesz zaoszczędzić pieniądze poprzez "leniwe głosowanie" lub zgadywanie bez faktycznego przeprowadzenia wnioskowania, a reszta sieci osiągnie inny konsensus, twoja inwestycja zostanie zmniejszona.
Token to zachęta do prawdy
Token $MIRA to nie tylko "płatność za chatbota." To funkcjonalne zabezpieczenie, które sprawia, że weryfikacja jest uczciwa.
Obniżanie jako kontrola jakości: Tworzy bezpośrednią karę finansową za halucynację.
Pracuj jako górnictwo: W Mira, "Praca" nie polega na rozwiązywaniu bezużytecznych zagadek; to rzeczywista obliczenia weryfikacji.
Certyfikat: Kiedy sieć się zgadza, mintuje kryptograficzny certyfikat.
Pomyśl, dlaczego to ma znaczenie dla problemu "Zapaści Modelu". Jeśli jestem deweloperem budującym nowy model podstawowy w 2027 roku, nie mogę po prostu zbierać danych z sieci—jest zbyt zanieczyszczona. Potrzebuję sposobu na filtrowanie danych "Zweryfikowanej Klasy". Zapłacę (w $MIRA), aby zweryfikować, że mój zbiór treningowy przeszedł przez zdecentralizowany konsensus.
Friction w rzeczywistym świecie
Teraz, bądźmy szczerzy—to jeszcze nie jest magiczne rozwiązanie. Największym wąskim gardłem, które teraz widzę, jest opóźnienie. Rozbicie artykułu o 500 słowach na 20 roszczeń i czekanie na zdecentralizowany konsensus, aby "ustalić" zajmuje więcej czasu niż surowe wywołanie API do GPT-4.
Jeśli Mira chce być globalną infrastrukturą dla prawdy, muszą rozwiązać "Szybkość Rozliczenia" weryfikacji. Na razie jest to świetne dla dokumentów o wysokiej stawce (prawne, medyczne, finansowe), ale wciąż jest zbyt wolne dla real-time agenta konwersacyjnego. Używają Base dla efektywności L2, co pomaga, ale warstwa weryfikacji "Ludzkiej Klasy" jest naturalnie wolniejsza niż warstwa generacji "Maszynowo-Szybkiej". To jest napięcie, którego jeszcze całkowicie nie rozwiązali.
Co obserwuję
Zaczynam odchodzić od patrzenia na ich "liczbę użytkowników" i zamiast tego przyglądam się przyjęciu ich SDK dewelopera.
Sygnal, który udowodniłby moją tezę, nie jest wzrostem cen; to dostrzeganie dużego agregatora danych lub platformy dostrajania integrującej API weryfikacji Mira, aby "wstępnie filtrować" swoje zestawy danych. Jeśli zobaczymy tag "Zweryfikowane przez Mirę" stający się standardem dla danych do treningu wysokiej jakości, to projekt skutecznie przeszedł z "zabawki crypto-AI" do globalnego narzędzia.
Obserwuję również zachowanie "Leniwego Weryfikatora". Jeśli zobaczymy dużo obniżania wczesnego, to znaczy, że teoria gier działa—łapie ludzi próbujących oszukiwać system.
Ostateczna myśl
Spędziliśmy ostatnie dwa lata obsesyjnie zastanawiając się, jak szybko AI może generować treści. Zamierzamy spędzić następne pięć lat obsesyjnie zastanawiając się, jak możemy udowodnić, że cokolwiek z tego jest naprawdę prawdziwe. Mira nie jest budowniczym AI; jest jego audytorem. W świecie syntetycznych śmieci, audytor jest tym, który naprawdę posiada rynek premium.
Prawda jest droga, ale mylenie się zaczyna kosztować znacznie więcej.
@SignOfficial #SingDigitalSovereignInfr $SIGN
