przeglądałem litepaper protokołu SIGN i kilka demonstracji integracyjnych, głównie próbując zrozumieć, dlaczego wciąż pojawia się w narzędziach dystrybucji. na pierwszy rzut oka wydaje się dość proste — zdefiniować jakieś poświadczenia, zweryfikować je, a następnie użyć tego do podjęcia decyzji, kto otrzymuje tokeny. trochę jak formalizowanie chaotycznych arkuszy kalkulacyjnych i skryptów, które zespoły już używają.
a tak, myślę, że tak to widzi większość ludzi. warstwa poświadczeń plus kilka wbudowanych mechanizmów airdrop. przydatne, ale nie do końca nowy prymityw.
ale to nie jest pełny obraz.
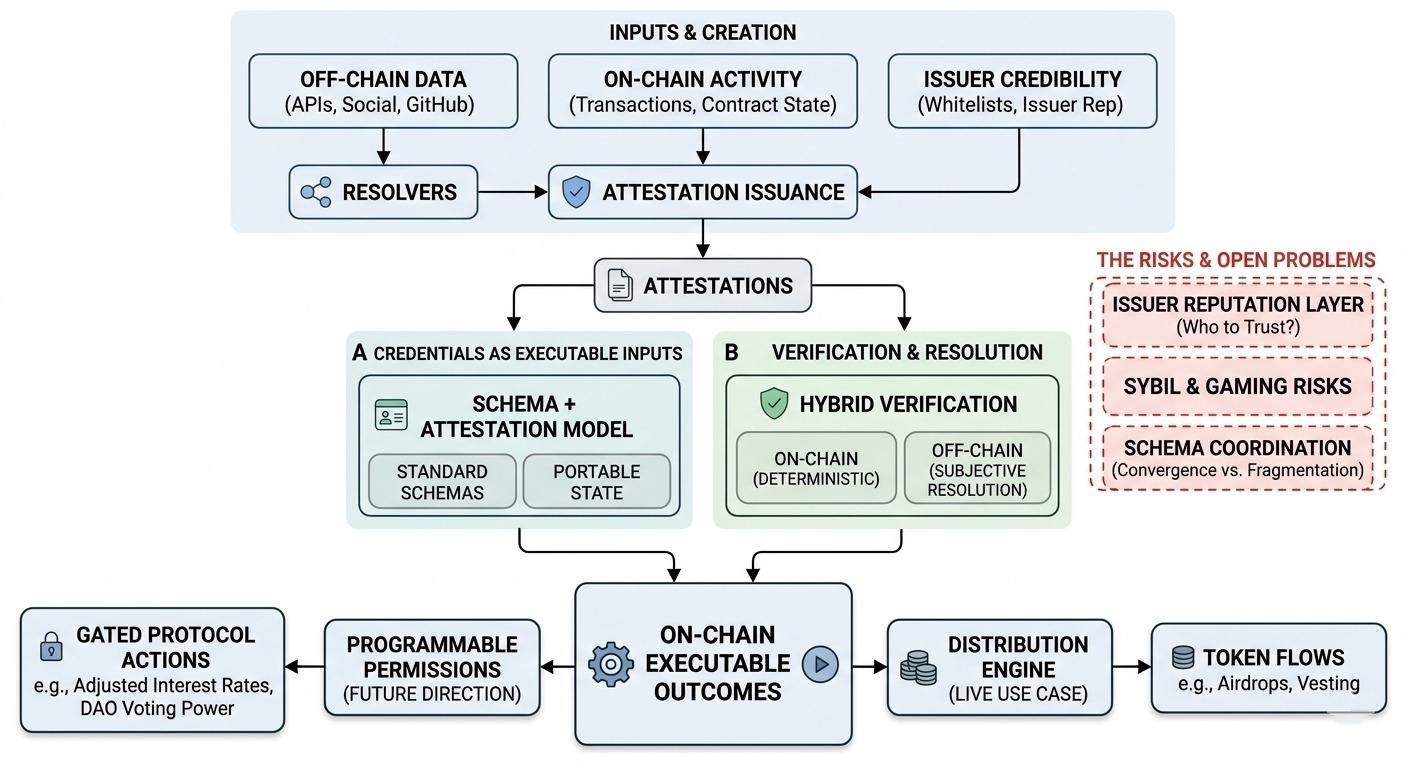
to, co SIGN cicho robi, to przekształcanie poświadczeń w coś wykonalnego. nie tylko rekordy, które przesyłasz zapytania, ale dane wejściowe, które bezpośrednio napędzają wyniki on-chain. a gdy poświadczenia zaczynają wywoływać akcje — szczególnie przepływy tokenów — przestają być pasywnymi danymi i zaczynają zachowywać się bardziej jak infrastruktura.
pierwszym elementem jest model schematu + zaświadczenia. nic nowego koncepcyjnie — schematy definiują strukturę, zaświadczenia wypełniają je roszczeniami. ale SIGN stawia na standaryzację schematów w sposób, który sugeruje ponowne wykorzystanie w aplikacjach. nie tylko „ta aplikacja definiuje poświadczenie”, ale „to poświadczenie może istnieć niezależnie od jakiejkolwiek pojedynczej aplikacji.”
i to jest miejsce, gdzie robi się interesująco. jeśli schematy rzeczywiście staną się wspólne, wtedy poświadczenia zaczynają wyglądać jak przenośny stan. „historia” lub „reputacja” użytkownika nie jest zablokowana w jednym systemie. ale to w dużej mierze zależy od koordynacji. schematy mają znaczenie tylko wtedy, gdy wiele stron się na nie zgadza, a ta zgoda nie jest egzekwowana przez protokół.
część z tego jest już w toku — projekty wydają zaświadczenia i używają schematów wewnętrznie. ale ponowne wykorzystanie między aplikacjami wciąż wydaje się słabe. większość zespołów chyba definiuje, czego potrzebują i przechodzi dalej, zamiast opierać się na wspólnych standardach.
drugim mechanizmem jest warstwa weryfikacji, szczególnie model hybrydowy. SIGN obsługuje zarówno weryfikację on-chain (deterministyczną, opartą na kontrakcie), jak i rozwiązania off-chain (dane zewnętrzne, API, heurystyki). na papierze to tylko elastyczność.
ale oto rzecz — mieszanie tych dwóch tworzy podzieloną granicę zaufania. weryfikacja on-chain jest jednolita, wszyscy widzą ten sam wynik. rozwiązanie off-chain wprowadza subiektywność, w zależności od tego, jak są wdrażani i utrzymywani resolverzy.
więc teraz poświadczenie nie jest tylko „prawdziwe lub fałszywe”, to „prawdziwe w zależności od tego, jak to rozwiązujesz.” co jest w porządku dla danych ze świata rzeczywistego, ale komplikuje kompozycyjność. dwie aplikacje mogą konsumować to samo zaświadczenie, ale dojść do nieco innych wniosków.
to hybrydowe podejście jest już stosowane, szczególnie w kontrolach kwalifikacji, które polegają na sygnałach off-chain. ale standaryzacja zachowań resolverów, a nawet zgoda na akceptowalną wariancję, wydaje się otwartym problemem.
trzecim elementem jest silnik dystrybucji, który prawdopodobnie jest najbardziej konkretną częścią dzisiaj. SIGN łączy poświadczenia bezpośrednio z logiką dystrybucji tokenów. definiuj kwalifikowalność za pomocą zaświadczeń, a następnie wykonuj dystrybucje bez eksportowania list lub pisania niestandardowych skryptów.
to jest wyraźnie na żywo i jest używane. to zmniejsza obciążenie operacyjne i sprawia, że dystrybucje są bardziej powtarzalne. ale także przesuwa, gdzie mieszka złożoność. zamiast ręcznego skryptowania dystrybucji, kodujesz logikę w schematach i zasadach weryfikacji.
i nie jestem do końca pewien, czy to zawsze jest prostsze — tylko inne. złożoność przenosi się z ad hoc skryptów do zdefiniowanych struktur, które są łatwiejsze do ponownego użycia, ale trudniejsze do zrozumienia, gdy coś idzie nie tak.
bardziej przyszłościowe części — warstwy tożsamości, przenośność poświadczeń między blockchainami, głębsze integracje portfeli — wydają się bardziej kierunkiem niż rzeczywistością. zależą od ponownego wykorzystania poświadczeń w różnych ekosystemach, co znowu wraca do koordynacji schematów i zaufania do wydawców.
jedną z rzeczy, którą ciągle kwestionuję, jest wiarygodność wydawcy. jeśli ktokolwiek może wydawać zaświadczenia, system potrzebuje jakiegoś sposobu na ich ważenie. w przeciwnym razie dostaniesz zalew niskosygnałowych poświadczeń. SIGN nie egzekwuje tej warstwy — pozostawia to aplikacjom lub przyszłym rozszerzeniom.
więc kończysz z problemem drugiego rzędu: nie tylko weryfikując poświadczenia, ale decydując, którzy wydawcy mają znaczenie. a to może szybko stać się chaotyczne.
też zastanawiam się, jak to się trzyma w warunkach wrogich. ataki sybili, koludujący wydawcy, gry schematowe — żadne z tych zjawisk nie jest unikalne dla SIGN, ale protokół ułatwia operacjonalizację poświadczeń na dużą skalę, co może nasilić te problemy.
ciekawi mnie:
* czy schematy rzeczywiście się zbliżają, czy pozostają fragmentaryczne w zależności od projektu
* jak ewoluują resolverzy off-chain i czy się standaryzują
* jeśli dystrybucja pozostaje głównym przypadkiem użycia lub tylko punktem wejścia
* pojawienie się reputacji wydawcy lub warstw filtrujących
* prawdziwe przykłady ponownego wykorzystania poświadczeń w niepowiązanych ekosystemach
#signdigitalsovereigninfra @SignOfficial $SIGN