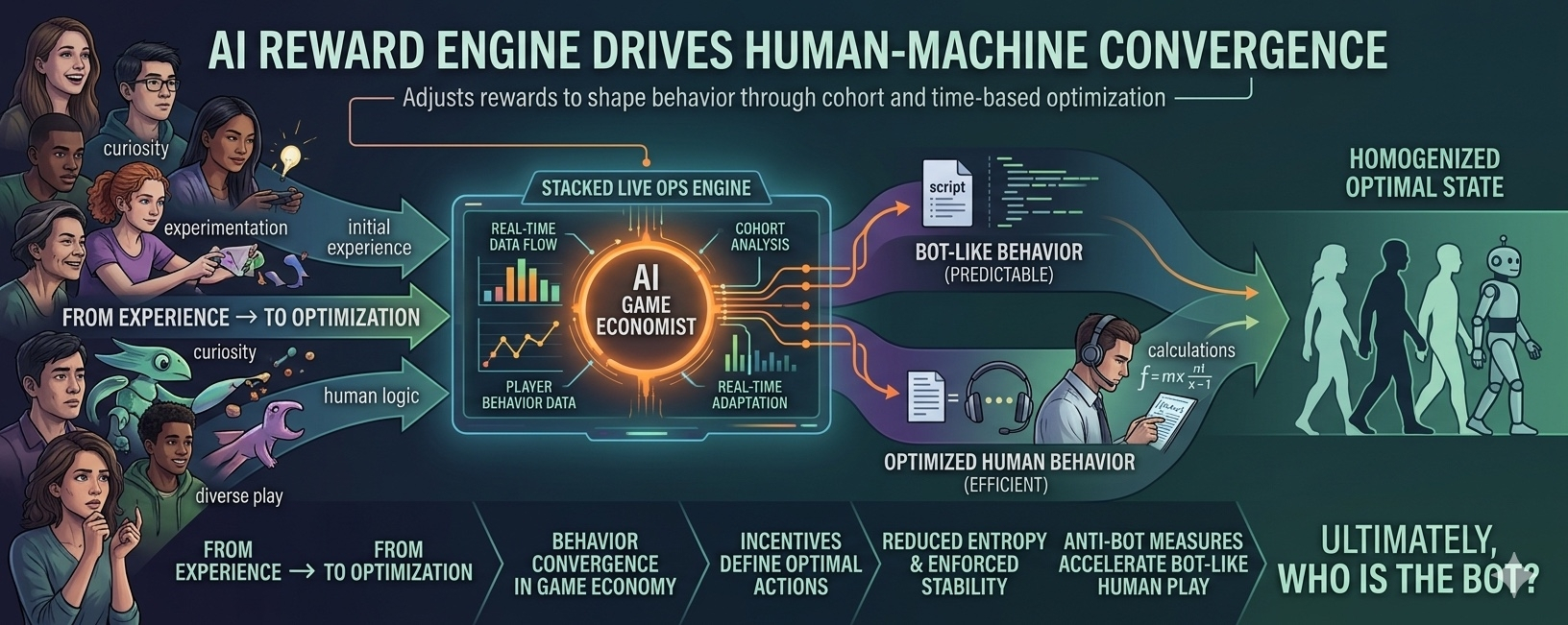
Có một đoạn trong docs Stacked của hệ Pixels mà mình quay lại nhiều lần, không phải vì nó hay về mặt marketing, mà vì nó hơi khó chịu nếu nghĩ kỹ. Nó nói về một engine LiveOps có thưởng, nơi AI game economist đứng ở lớp trên để điều chỉnh phần thưởng theo hành vi người chơi, theo cohort, theo thời điểm. Nghe thì giống một hệ thống tối ưu retention bình thường. Nhưng càng đọc kỹ, cảm giác nó không còn giống “game design” nữa.
Nó giống một hệ thống đang liên tục chỉnh lại con người thông qua phần thưởng.
Ban đầu mình nhìn bài toán này theo hướng rất quen: bot. Script farm, automation click, những thứ từng làm P2E chết dần trong giai đoạn đầu. Trong logic cũ, chống bot là để giữ lại người chơi thật, để làm hệ thống “clean” hơn. Nhưng khi nhìn vào cách Pixels và Stacked vận hành, mình bắt đầu thấy một điều khác xảy ra song song. Khi bot bị loại bỏ, hệ thống không trở nên “người hơn” như kỳ vọng. Nó trở nên tinh chỉnh hơn, chính xác hơn, và khó phân biệt hơn.
Và chính sự chính xác đó làm hành vi con người bắt đầu thay đổi.
Điều đầu tiên mình để ý là cách người chơi học hệ thống nhanh hơn họ học game. Không cần gian lận, không cần tool. Chỉ cần quan sát đủ lâu, họ bắt đầu nhận ra những pattern lặp lại: thời điểm reward mạnh hơn, hành vi nào được hệ thống phản hồi tốt hơn, cohort nào đang được ưu tiên giữ chân.
Ban đầu đây là curiosity. Sau đó là thói quen. Rồi dần dần chuyển thành một dạng phản xạ mới: trước khi làm gì, người chơi tự hỏi hành động này có “hiệu quả trong hệ thống” hay không. Không ai bảo họ làm vậy. Họ tự học.
Điểm đáng chú ý là hành vi này không bị xem là sai. Trong nhiều trường hợp, nó được xem là kỹ năng. Một người chơi hiểu hệ thống luôn có lợi thế hơn người chơi chỉ chơi theo cảm giác. Nhưng chính khoảnh khắc đó, game bắt đầu đổi bản chất.
Từ trải nghiệm → sang tối ưu hóa. Từ chơi → sang tính toán.
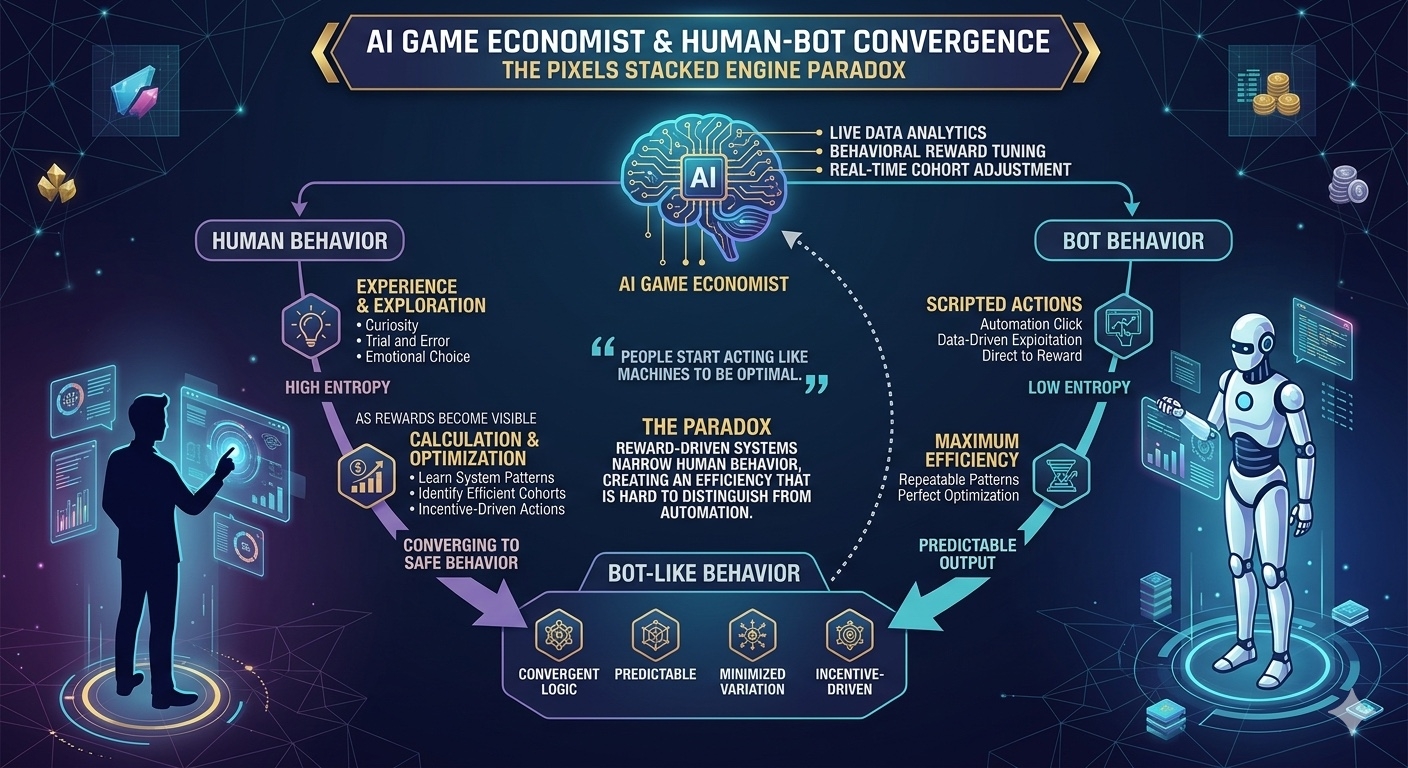
Trong hệ Stacked, AI game economist đứng ở lớp trên cùng, liên tục đọc dữ liệu hành vi và điều chỉnh reward theo cohort và thời gian thực. Không có một luật chơi cố định đủ lâu để người chơi học xong và “giải mã”. Luật luôn dịch chuyển theo chính hành vi mà nó quan sát được.
Điều này tạo ra một vòng lặp hơi khó nhìn nếu đứng từ ngoài: Hành vi → dữ liệu → điều chỉnh reward → hành vi mới.
Và vòng lặp đó không dừng.
Có một điểm mình thấy khá quan trọng: khi reward trở nên đủ rõ ràng và đủ lặp, con người bắt đầu giảm thử nghiệm. Không phải vì họ bị giới hạn, mà vì họ thấy không cần thử nữa.
Ở trạng thái này, con người không còn phân tán hành vi như trước. Họ bắt đầu hội tụ về những hành vi “an toàn về mặt kinh tế trong game”. Và khi đủ nhiều người làm điều đó, hệ thống nhìn từ trên xuống bắt đầu thấy một thứ giống nhau: hành vi đồng dạng.
Điều này dẫn đến một nghịch lý khá rõ. Chống bot được thiết kế để loại bỏ hành vi máy móc. Nhưng khi hệ thống trở nên đủ tối ưu, chính con người lại bắt đầu hành xử giống máy móc hơn.
Không phải vì họ bị biến thành bot. Mà vì bot-like behavior trở thành cách tối ưu nhất để tồn tại trong hệ thống incentive.
Mình từng thử đặt hai kiểu người chơi cạnh nhau trong đầu. Một người casual, chơi theo cảm giác. Một người hiểu hệ thống, tối ưu từng hành động. Bề ngoài họ giống nhau: cùng chơi game, cùng làm nhiệm vụ, cùng nhận reward.
Nhưng bên trong hoàn toàn khác. Một bên đang trải nghiệm. Một bên đang chạy mô hình. Và hệ thống không phân biệt rõ hai thứ đó.
Stacked làm điều này rõ hơn vì nó không chỉ phát reward, mà còn tái phân phối reward theo cohort và thời gian thực. Điều này tạo ra một sự thật hơi khó chịu: không tồn tại một “luật chơi chung” đủ ổn định để mọi người học xong rồi chơi theo.
Thay vào đó, có nhiều biến thể luật chạy song song, thay đổi theo dữ liệu hành vi. Điều đó khiến người chơi không còn học game. Họ học cách hệ thống phản ứng với chính họ.
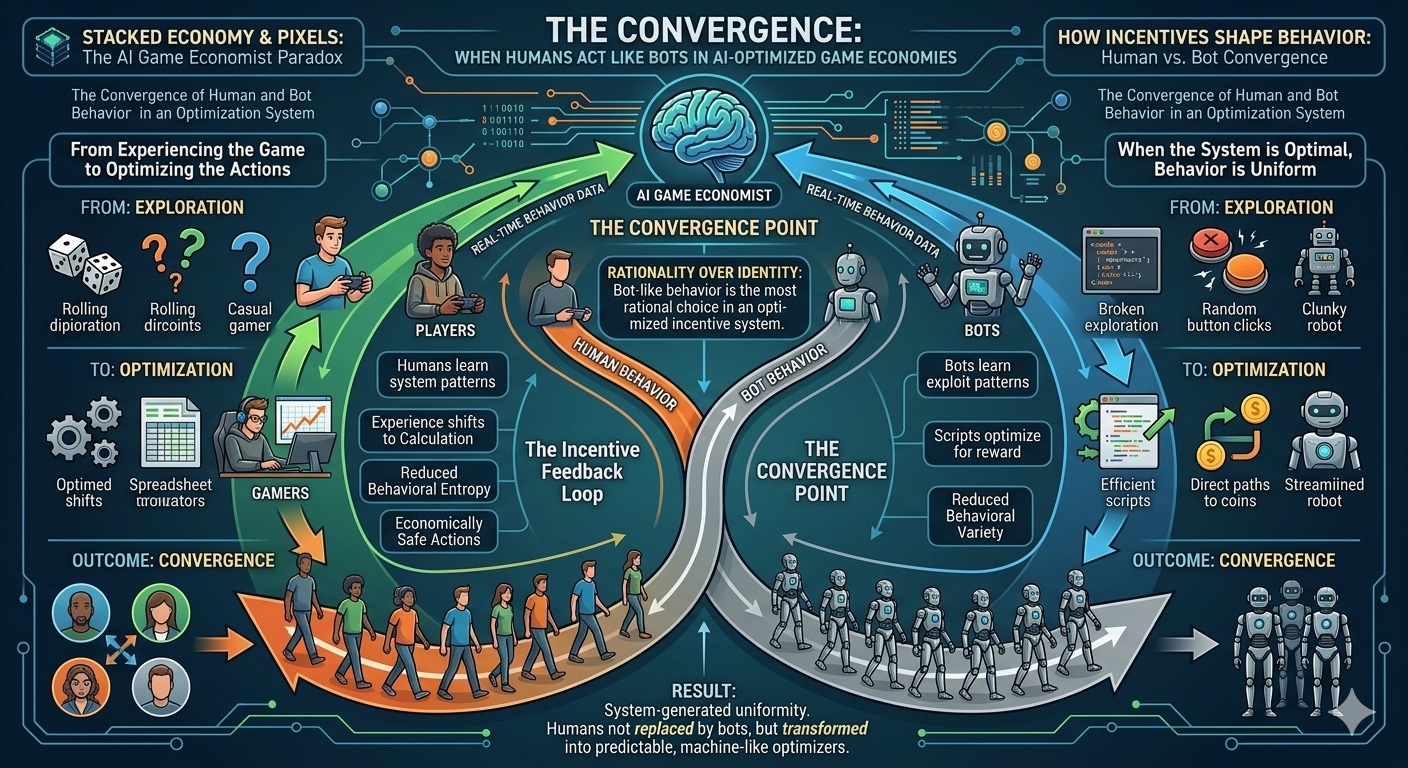
Có một layer nữa mà mình nghĩ quan trọng hơn bot rất nhiều. Đó là entropy hành vi.
Trong môi trường bình thường, con người có rất nhiều thử nghiệm nhỏ: chơi thử, sai thử, làm theo cảm xúc, đổi chiến lược liên tục. Nhưng trong hệ reward-driven đủ mạnh, entropy đó bị nén lại. Không phải bằng cưỡng chế. Mà bằng hiệu quả.
Khi reward càng dễ dự đoán, hành vi càng ít phân tán. Và khi hành vi ít phân tán, hệ thống trở nên ổn định hơn. Nhưng ổn định này không đến từ sự đa dạng, mà từ sự hội tụ.
Điểm đáng suy nghĩ là: hệ thống càng hiệu quả, con người càng giống nhau hơn trong cách ra quyết định.
Ở scale của Pixels, với hơn 200 triệu reward events và hàng chục triệu USD doanh thu từ hệ thống Stacked, hành vi không còn là thứ mang tính cá nhân nữa. Nó trở thành một phân phối được liên tục cập nhật bởi hệ thống.
Mỗi reward event không chỉ là phần thưởng. Nó là một lần hệ thống trả lời câu hỏi: hành vi nào nên được củng cố. Và mỗi câu trả lời đó làm hành vi lệch đi một chút, rồi lại được đo lại, rồi lại điều chỉnh tiếp.
Có một điểm mình thấy khá rõ: chống bot trong hệ thống kiểu này không còn là “lọc cái sai”. Nó chỉ là bước đầu.
Vấn đề sâu hơn là: hệ thống đang tối ưu con người thành dạng hành vi nào. Vì khi bot biến mất, phần còn lại không tự nhiên trở thành “người hơn”. Nó trở thành thứ dễ dự đoán hơn, dễ tối ưu hơn, và gần với logic máy hơn.
Điều khiến ranh giới trở nên mờ là cả hai phía đều hội tụ về cùng một điểm. Bot tối ưu để exploit reward. Con người tối ưu để không lãng phí hành vi. Kết quả cuối cùng giống nhau ở cấp hành vi, chỉ khác ở nguồn gốc.
Mình không nghĩ đây là câu chuyện tốt hay xấu. Nó giống một trạng thái tiến hóa của hệ thống incentive hơn. Khi đủ dữ liệu, đủ feedback loop, đủ AI điều chỉnh, hệ thống không cần ép con người trở thành bot. Nó chỉ cần làm cho hành vi bot-like trở thành lựa chọn hợp lý nhất. Phần còn lại tự xảy ra.
Và có lẽ điểm khó chịu nhất nằm ở đây. Chống bot không thất bại. Nó thành công. Nhưng thành công đó không tạo ra “người chơi thuần túy hơn”.Nó tạo ra một không gian nơi con người và bot bắt đầu hội tụ về cùng một dạng logic hành vi, chỉ khác nhau ở cách họ đi vào đó.
Không phải bot và người. Mà là mức độ mà con người bị kéo vào vùng tối ưu hóa của chính hệ thống họ đang tương tác. Và trong hệ như Stacked của Pixels, ranh giới đó không còn nằm ở công cụ nữa. Nó nằm ở cách incentive định hình lại cách con người quyết định từng hành động nhỏ nhất mà họ nghĩ là của riêng mình.
