
Najpierw zauważyłem OpenLedger, ponieważ strona główna promowała bardzo aktualną aktualizację – „OctoClaw jest na żywo” – jednocześnie kierując ludzi do swojego eksploratora, stakingu i studia AI. Moja pierwsza reakcja była lekka sceptycyzm, ponieważ widziałem wiele projektów krypto, które przebrały zwykłą infrastrukturę w wielkie słowa. Ale czytałem dalej i pomysł zaczął wydawać się mniej jak slogan, a bardziej jak odpowiedź na coś, o czym branża wciąż unika rozmowy: AI wciąż się poprawia, ale dane i praca za tym są nadal w większości traktowane jak niewidoczne wejścia.
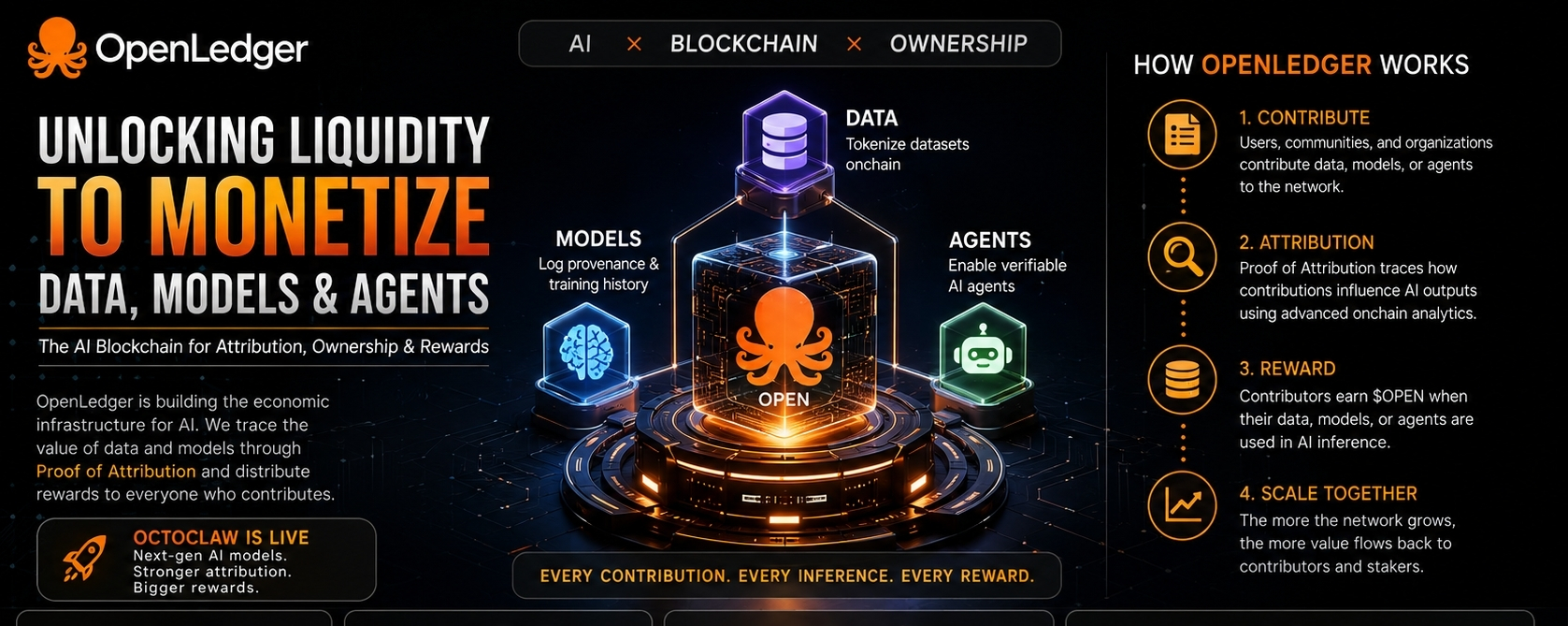
To jest ta część, która ze mną została. Wciąż wracam do luki między tym, ile wartości AI może stworzyć, a tym, jak mało z tej wartości wraca do ludzi, którzy dostarczali materiały treningowe, kuratorzy zbiorów danych lub budowali specjalistyczne systemy, które to wszystko wspierają. OpenLedger opisuje siebie jako blockchain AI, który chce uczynić dane, modele i agentów płynnymi, co brzmi abstrakcyjnie, dopóki nie przetłumaczę tego na coś prostszego: stara się przekształcić wkład AI w coś, co można naprawdę posiadać, śledzić i za co można płacić, zamiast znikać w czarnej skrzynce.
Mechanizm to miejsce, w którym zaczyna być dla mnie ciekawiej. W swoim dokumencie Proof of Attribution OpenLedger mówi, że system opiera się na DataNets, które są zbiorami danych na łańcuchu, dostarczonymi przez społeczności. Modele rejestrują swoje pochodzenie treningowe, a atrybucja jest obliczana po inferencji, aby protokół mógł śledzić, które dane wpłynęły na które wyniki. Dla mniejszych modeli stosuje metody w stylu funkcji wpływu; dla większych modeli językowych wykorzystuje atrybucję na poziomie tokenów w stosunku do skompresowanego korpusu. To jest prawdziwa teza tutaj: jeśli model korzysta z danych, dane powinny być wystarczająco śledzone, aby ich dostawcy mogli dzielić się zyskami.
To też jest miejsce, w którym token zaczyna mieć dla mnie sens. Studio OpenLedger mówi, że zweryfikowane wkłady zarabiają $OPEN, a dokument opisuje, że opłaty za inferencję są dzielone pomiędzy platformę, model, stakerów i dostawców wkładów. Więc token nie jest tylko symbolem do handlu lub uwagi; ma na celu osadzenie się wewnątrz ekonomicznej pętli sieci, płacąc za użycie i nagradzając ludzi, których dane naprawdę poprawiają system. Nie sądzę, że to rozwiązuje wszystko, ale myślę, że to bardziej uczciwa próba na AI niż zwykle "społecznościowe" języki, które projekty rzucają.
Myślę też, że problem w rzeczywistości jest łatwy do przeoczenia, jeśli patrzę tylko przez pryzmat kryptowalut. Większość systemów AI nadal polega na jednostronnym związku: konsumują dane, produkują wyniki i zostawiają oryginalnych dostawców prawie bez widoczności. To staje się większym problemem, gdy AI staje się bardziej wyspecjalizowane. Niszowy model prawny, asystent handlowy lub system robotyczny jest tylko tak dobry, jak dane, na których się opiera. OpenLedger stara się uczynić tę zależność widoczną i ekonomicznie znaczącą, co wydaje się być bardziej dojrzałym pytaniem niż tylko pytanie, jak przymocować token do produktu AI.
Jednak to, co sprawia, że myślę o przyszłości, to możliwość, że taka warstwa atrybucji stanie się normalna, a nie nowatorska. Jeśli agenci AI będą się przemieszczać z prostych interfejsów czatu do rzeczywistej egzekucji — zarządzanie portfelami, przepływami pracy, badaniami, a może w końcu systemami fizycznymi — to pochodzenie zaczyna mieć znacznie większe znaczenie. Obecna strona OpenLedger jest już skonstruowana wokół agentów AI w czasie rzeczywistym, a ich blog promuje ideę, że AI potrzebuje audytowalnej, on-chain koordynacji zamiast kruchych, ukrytych integracji. To wskazuje na świat, w którym inteligencja nie tylko jest używana, ale też jest odpowiedzialna.
Wciąż nie sądzę, że trudna część jest rozwiązana. Atrybucja to chaotyczny problem, zwłaszcza gdy modele stają się większe, dane są powtórnie wykorzystywane, a zachęty zaczynają przyciągać ludzi, którzy wiedzą, jak oszukiwać systemy. Nawet własny dokument OpenLedger brzmi jak poważna próba rozwiązania trudnego problemu pomiarowego, a nie gotowa odpowiedź. Ale to też jest powód, dla którego uznałem to za interesujące. Sprawiło, że pomyślałem, że następna faza infrastruktury AI nie będzie tylko związana z skalą czy prędkością. Może chodzić o udowodnienie, skąd pochodzi inteligencja, kto pomógł ją stworzyć i jak wartość jest dzielona, gdy maszyny zaczynają produkować coś użytecznego na przemysłową skalę. To wydaje się być większą zmianą, którą OpenLedger stara się osiągnąć.