
The OpenLedger lifecycle begins with the global community. In this first image, we establish the diverse contributors—from students and medical researchers to financial analysts—uploading their localized datasets. Crucially, the image visualizes the "anonymization and encryption" process as data flows from personal devices into the "OpenLedger Datanet" vault, where it becomes part of a collective intelligence pool without compromising privacy.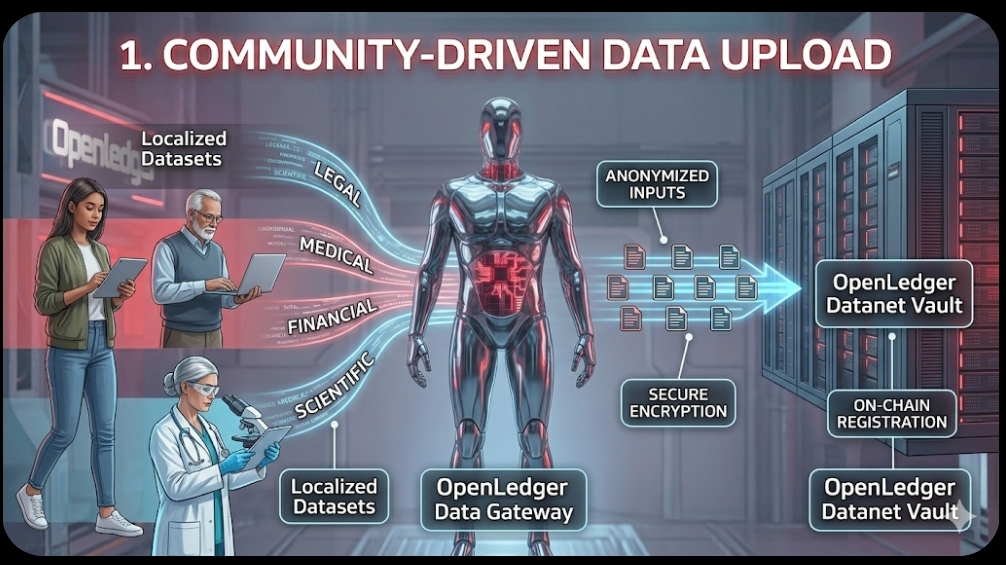
AI Model Training and Fine-Tuning
Once data is securely stored in the Datanets, the second image shifts perspective to how AI developers utilize this resource. We move away from the contributors' gateway to a structured network of ModelFactory Workstations and specialized Training Pods.
The core of image 0, the distinctive android with exposed glowing circuitry, is now specialized and multiplied. One android is fine-tuning a Large Language Model (LLM), another specializes in medical diagnostics, and a third in high-frequency trading. They pull data streams directly from the transparent On-Chain Datanet Vault that we saw being populated in Image 1, illustrating that model creators access unbiased, community-governed data for training. The environment remains industrial but focuses on computation rather than data ingest.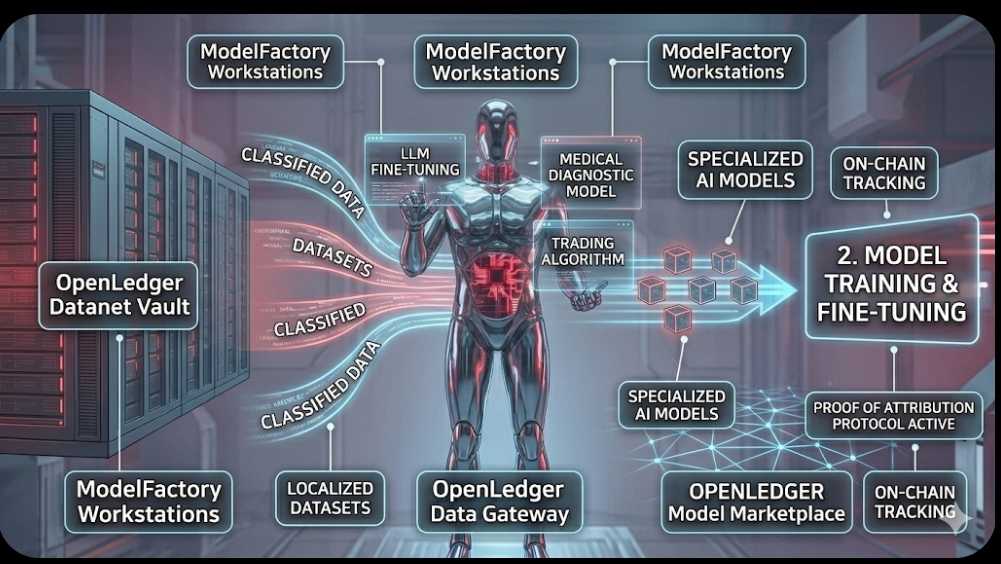
Ecosystem & Decentralized Collaboration Focus
The decentralized AI sector needs scalable solutions that move beyond simple speculation and into real utility. @OpenLedger edger is actively addressing this by introducing an innovative framework where data contributors, model developers, and agents can co-create and monetize their assets transparently. Features like their Model Datanets allow global communities to collaborate securely on dataset curation, ensuring fair attribution for all participants on-chain. Keeping an eye on $OPEN N is essential for anyone tracking the intersection of smart contracts and machine learning. Exciting times lie ahead for decentralized intelligence! #OpenLedger