Anthropic赔钱那天,AI突然老实了
2025年9月,Anthropic因为非法抓取700万本盗版图书训练模型,被迫达成巨额和解,还被强制要求销毁相关数据集-。差不多同一时间,国内某科技公司因为未经许可抄了抖音的“变身漫画特效”模型结构和参数,被法院判赔160万-。案子不大,但意义不小——司法系统第一次明确表态:模型结构和参数是有知识产权的,不是换个皮就能据为己有。
这两件事像是两记沉闷的钟声,把整个AI行业敲醒了。过去几年大家都在用“大力出奇迹”的逻辑蒙头狂奔——谁参数多谁牛逼,谁训练数据量大谁说话硬气。至于这些数据从哪来的、版权归谁、该不该付钱,没人问,也没人敢问。2025年最高人民法院审结的涉数据权属和交易纠纷案件高达908件,同比增长了25.6%,这还只是中国一个市场的统计-。
@OpenLedger 这个项目就是在这种火药味最浓的时候,默默把自己的$OPEN 主网推上了线。2025年11月18日,Polychain Capital和Borderless Capital联合发布OPEN主网,用一种近乎沉默的方式给出了他们的答案-。而在主网上线前的测试网阶段,已经有超过600万个节点注册、2500万笔交易完成、20,000多个AI模型被构建出来、27个产品在网络上完成部署-。市场用真实的参与量告诉所有人一件事:AI行业对公平分配机制的渴求,远比想象中更迫切。
那么问题来了,一个区块链项目到底是怎么解决AI数据归属这个千古难题的?答案藏在他们设计的那套“归因证明”机制里。
20,000个模型之后,答案自己浮出来了
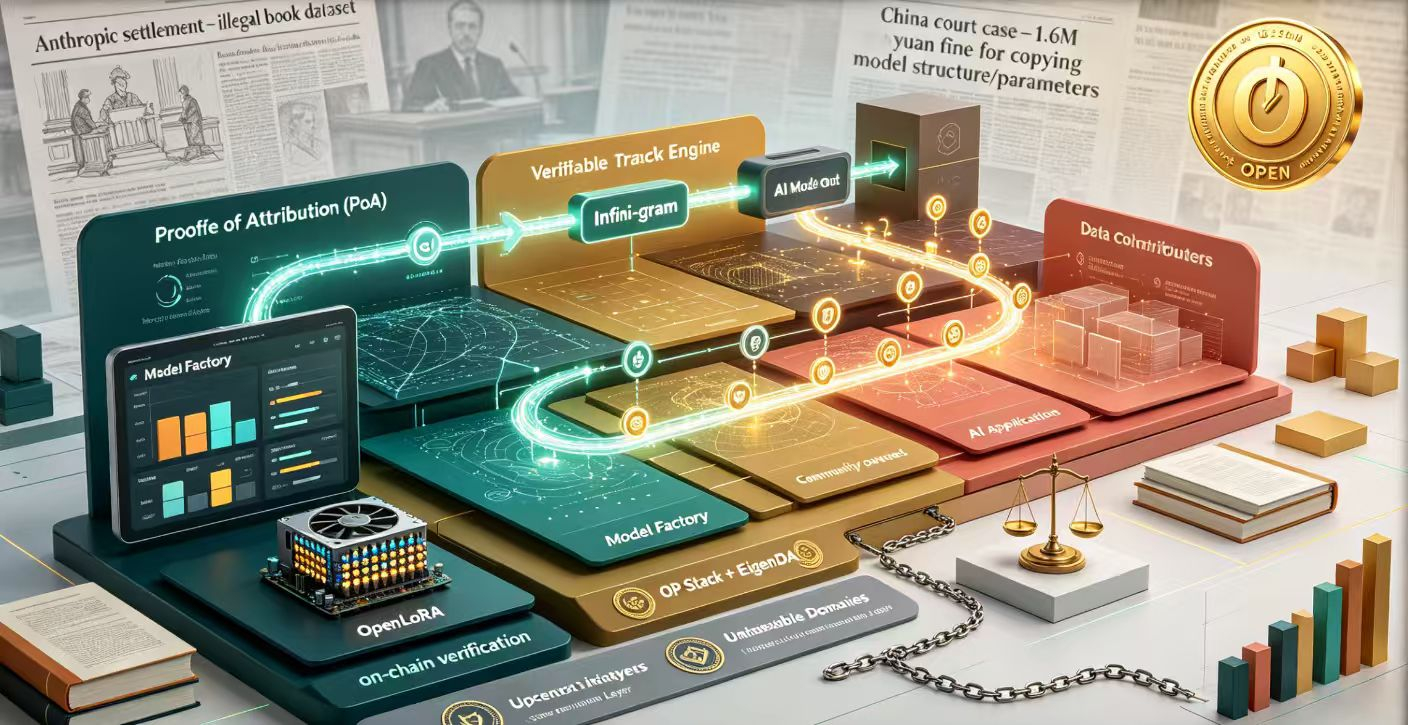
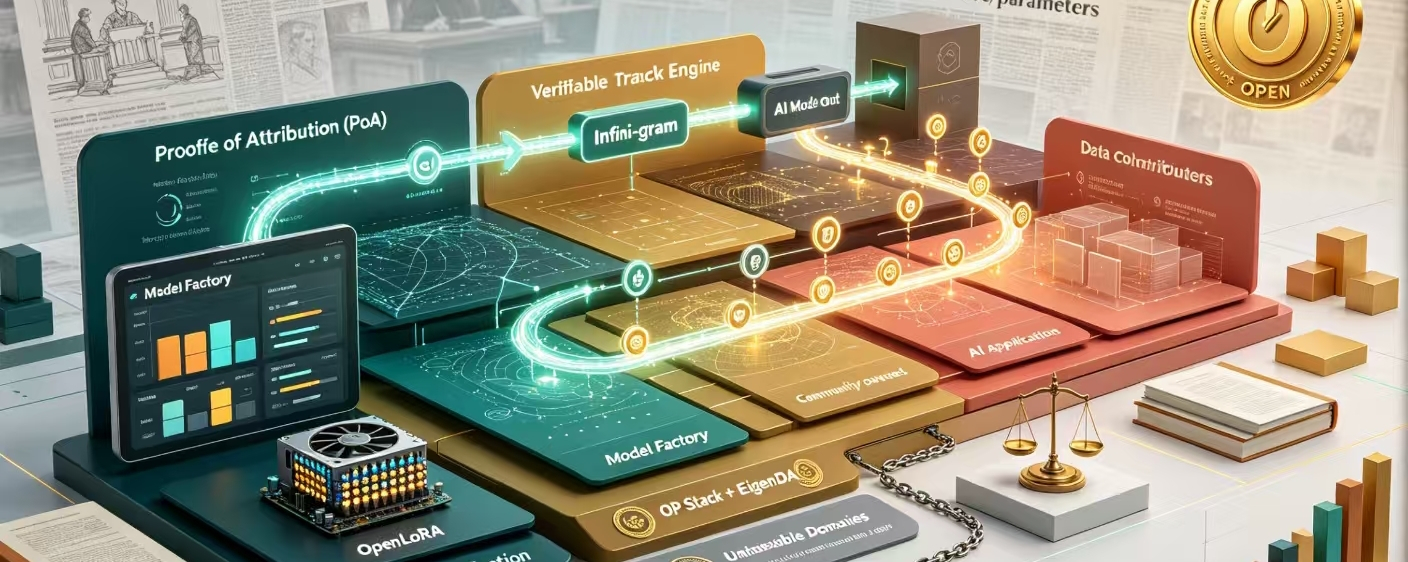
@OpenLedger 提出的核心概念叫 Payable AI,可支付的AI。翻译成大白话:每一次AI模型产生输出,系统都能精准追溯到喂给它数据的那些人,然后自动把钱分过去。这就是他们所谓的归因证明(Proof of Attribution) 。
这个设计的牛批之处不在于技术炫酷,而在于它把一个没人敢碰的灰色地带变成了透明的游戏规则。AI这行有一个所有人都心知肚明却不愿明说的原罪:模型变得越来越智能,靠的是从互联网上扒来的海量数据,但真正贡献这些数据的人一毛钱没分到。核心贡献者Ram Kumar说过一句话:“AI从贡献者身上提取了数万亿的价值,却没有给过他们任何认可或补偿。$OPEN 要奖励的是那些让AI变得聪明的真正贡献者。”
主网上线后,OpenLedger的动作确实不是画饼。2026年1月和Pundi AI达成合作,把Pundi AI的去中心化数据创建和标注能力接入到OpenLedger的Datanets体系中,形成了从数据生产到模型训练再到上链执行的全栈闭环。同一时期Astro AI也跑了进来,基于OpenLedger的Datanets搭建了一套纯链上的AI占星预测系统,所有逻辑和数据全部跑在链上,没有任何链下黑盒。
而在生态扩张之前,$OPEN 代币的经济基础已经相当扎实。测试网阶段预留了总供应量51OPEN代币的经济基础已经相当扎实。测试网阶段预留了总供应量51OPEN在OpenLedger生态里扮演着Gas费、质押资产、治理投票权和贡献者认证凭证四个核心角色。更关键的是,归因证明机制让这种经济循环可持续运转——数据被使用了,贡献者就持续拿钱;模型被调用了,开发者就持续分账;而不是一次性买卖然后什么都没有。
区块链成了数据权的最后防线
有一点必须掰扯清楚:OpenLedger的野心不是再造一个大模型,而是在大模型时代下重新定义数据价值和模型贡献的归属权。这两个是本质不同的赛道。
去看看现在的AI+Crypto版图就明白了。Bittensor虽然头顶灰度ETF申请和英伟达黄仁勋站台的光环,TAO代币的完全稀释估值高达58亿美元,但实际年收入才300万到1500万美元,补贴和实际收入的比值超过了22倍-。本质上是靠代币通胀在养着算力网络,外部真实需求还没有真正跑起来。
OpenLedger走了一条完全相反的路。它不是“先补贴后变现”的逻辑,而是从一开始就把变现机制做进了底层协议里。技术栈方面,基于OP Stack和EigenDA构建,既保证了高性能推理的执行效率,又保证了链上结算的不可篡改-。Datanets是社区共有的数据集,专门服务于不同AI应用场景;Infini-gram归因系统让每一笔贡献都被追踪和记录;ModelFactory提供了无代码的模型微调工具;OpenLoRA系统让单个GPU可以托管数千个模型-。还有和Unstoppable Domains合作推出的.openx域名体系,为每一个生态参与者提供了一个可验证的链上身份层,让数据贡献者的身份与收益权紧密绑定,不再依赖任何中心化机构的信用背书。把AI从一个说不清道不明的黑箱,变成了一个所有参与者可以实时核账的分布式账本——这个转换背后站着整个数据权利意识觉醒的时代浪潮。
答案一直在你眼皮底下
OpenLedger其实在用最朴素的方式验证一件事:当AI行业终于不得不面对“数据到底是谁的”这个问题的时候,那些从一开始就把答案写在协议里的项目,会比那些靠融资和补贴撑着、假装问题不存在的选手走得远得多。Anthropic赔了钱,Bittensor烧着补贴,而@OpenLedger 在安安静静地告诉大家:数据是谁的,钱就是谁的。这件事不需要你懂技术,懂常识就够了。#OpenLedger