
Modele AI przyciągają większość uwagi. Większe modele. Mądrzejsze wyniki. Szybsze odpowiedzi.
Ale pod tym wszystkim kryje się cichszy problem: jakość danych.
AI jest tak samo użyteczne, jak informacje, z których się uczy. A dzisiaj wiele z tych danych znajduje się w zamkniętych systemach kontrolowanych przez małą liczbę platform. Gdy treści generowane przez AI zalewają internet, znalezienie wiarygodnych, wyspecjalizowanych i wysokiej jakości danych staje się coraz trudniejsze, a nie łatwiejsze.
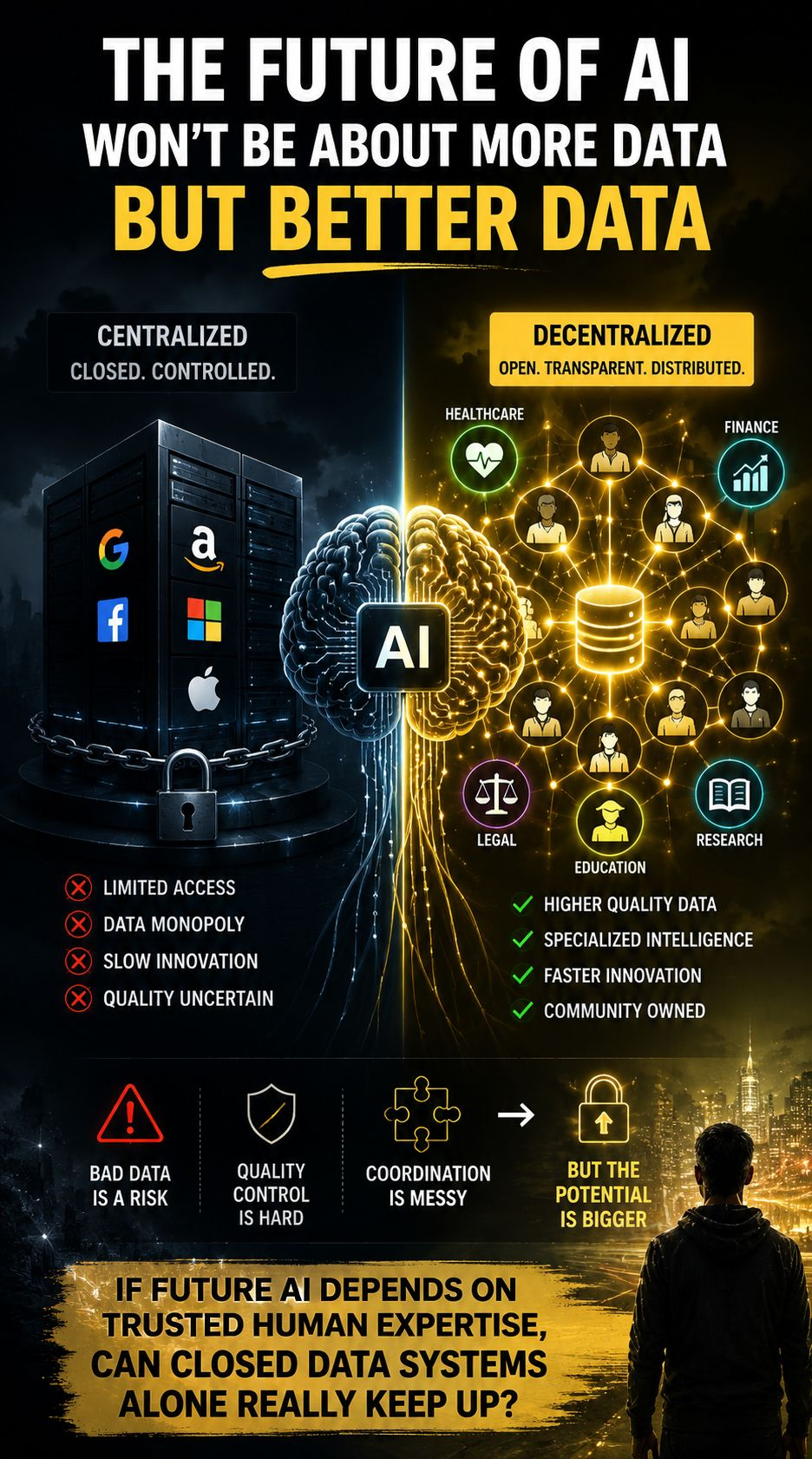
Dlatego zdecentralizowane dane AI mają znaczenie.
Argument jest prosty: przyszła AI może nie wygrać dzięki większej ilości danych, ale dzięki lepszym danym.
AI w opiece zdrowotnej nie może polegać na losowych treściach z internetu. Model finansowy potrzebuje dokładnych wskazówek z rynku. AI prawne polega na zaufanej ekspertyzie. Specjalistyczna inteligencja wymaga specjalistycznych zbiorów danych.
Zdecentralizowane systemy danych próbują to rozwiązać, czyniąc wkład bardziej otwartym, przejrzystym i rozproszonym, zamiast polegać całkowicie na scentralizowanych rurkach.
Bardziej istotna implikacja jest często ignorowana: jeśli wysokiej jakości ludzka wiedza stanie się najcenniejszym wkładem dla AI, systemy zbierające i organizujące tę inteligencję mogą być równie ważne jak same modele.
Oczywiście, decentralizacja stwarza wyzwania. Kontrola jakości jest trudna, koordynacja jest chaotyczna, a złe dane wciąż stanowią ryzyko.
Jednak jedno pytanie staje się coraz głośniejsze:
Jeśli przyszłe AI będzie polegać na zaufanej ludzkiej ekspertyzie, czy zamknięte systemy danych naprawdę mogą nadążyć?
