Szczera myśl... Kiedyś zakładałem, że integralność kryptograficzna i skalowalność to po prostu dwa punkty na tym samym suwaku. Podnieś jeden, drugi opada. Ta teoria trzymała się do momentu, gdy zacząłem czytać, jak OpenLedger faktycznie strukturyzuje swoją warstwę transakcyjną. Rollupy zajmują się przepustowością, podczas gdy kryptograficzne przejścia stanu na stałe blokują każdy rekord przypisania. To nie jest suwak... To dwa oddzielne systemy wykonujące dwie oddzielne prace, a architektura działa tylko dlatego, że żaden z nich nie jest proszony o robienie pracy drugiego.
Istnieje szczególny rodzaj zmęczenia, które narasta, gdy widzisz wystarczająco dużo projektów blockchainowych składających tę samą obietnicę w różnych czcionkach. "Rozwiązaliśmy trylemat." "Nieskończenie skalowalne i w pełni zdecentralizowane." Czytałem te linie tak wiele razy..... że przestałem odbierać je jako techniczne twierdzenia i zacząłem postrzegać je jako postawę marketingową. Kiedy więc natknąłem się na architekturę OpenLedger, moim pierwszym instynktem była ta sama sceptyczność, którą noszę ze sobą do wszystkiego. Ale coś sprawiło, że zwolniłem tempo i naprawdę przeczytałem strukturę, a nie nagłówek.
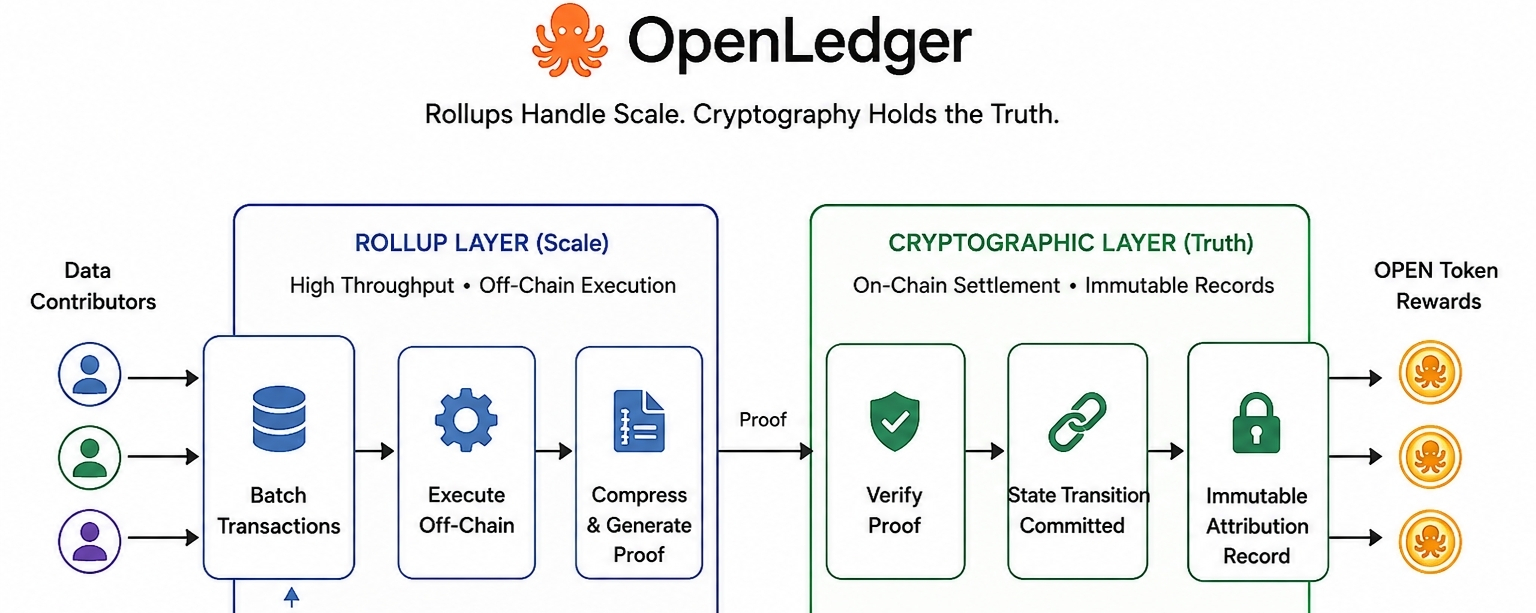
Podstawowe napięcie, które OpenLedger naviguje, jest realne. Nie jest wymyślone na potrzeby białej księgi. Każdy system, który chce rejestrować wkłady danych treningowych AI na dużą skalę, napotyka tę samą przeszkodę, na którą natrafia każdy blockchain o wysokiej przepustowości. Jeśli próbujesz kryptograficznie weryfikować każdy pojedynczy mikro-wkład w czasie rzeczywistym, nie uzyskasz wydajnego systemu. Uzyskasz wąskie gardło przebrane za infrastrukturę. Większość projektów rozwiązuje to, cicho luzując gwarancje kryptograficzne. OpenLedger rozwiązuje to, całkowicie oddzielając te dwa zagadnienia.
Rollupy grupują wykonanie transakcji poza głównym łańcuchem i kompresują wynik w weryfikowalny dowód. Ten dowód jest osadzany na łańcuchu. Przepustowość żyje w warstwie rollup. Prawda żyje w kryptograficznym przejściu stanu. Żaden z systemów nie pełni podwójnej roli. To jest część, która naprawdę mnie zatrzymała i skłoniła do myślenia, ponieważ odpowiada na pytanie, na które większość projektów nawet nie uznaje za zasadne... Jak radzisz sobie z milionami rekordów wkładów danych, nie dławiąc łańcucha ani cicho nie obniżając standardów integralności?
Model przypisania to miejsce, w którym to staje się wystarczająco specyficzne, aby miało znaczenie. Kiedy zestaw danych przyczynia się do uruchomienia treningu modelu AI, OpenLedger rejestruje ten wkład jako zmianę stanu, a ta zmiana stanu zostaje zablokowana przez warstwę kryptograficzną. Rollup zajmuje się wolumenem. Rekord kryptograficzny zajmuje się trwałością. Mały przykład, nad którym warto się zastanowić... wyobraź sobie, że wkładca dostarcza 10 000 oznaczonych obrazów. Każde rozliczenie partii jest kompresowane, weryfikowane i kotwiczone. Rekord wkładcy nie zależy od tego, czy ktokolwiek to zapamięta. Zależy od matematyki, która nie może być cicho zmieniana później. Ta różnica nie jest mała, gdy mówisz o nagrodach tokenów OPEN związanych z tymi rekordami.
Oto pytanie... Do którego ciągle wracałem. Systemy oparte na rollupach są tylko tak wiarygodne, jak dowody ważności, które wykorzystują. Optymistyczne rollupy zakładają poprawność i polegają na oknie wyzwań. Rollupy ZK generują dowody, które są weryfikowane obliczeniowo. To są naprawdę różne modele zaufania, a praktyczne implikacje dla księgi przypisań są znaczące. System optymistyczny oznacza, że istnieje okno, w którym teoretycznie może istnieć oszukańcza partia wkładów zanim zostanie zakwestionowana.👀 System ZK zamyka to okno... ale niesie ze sobą większe koszty obliczeniowe. Architektura OpenLedger skłania się ku stronie ZK, co jest trudniejszą ścieżką do zbudowania, ale bardziej uczciwą dla systemu, w którym trwałość przypisań jest całym propozycją wartości.
To, co warto obserwować, to czy gwarancje kryptograficzne utrzymują się pod rzeczywistym obciążeniem, a nie w warunkach testnetu. Każda architektura brzmi spójnie w dokumentacji. Test obciążeniowy to to, czy generowanie dowodów nadąża, gdy wolumen danych nie jest kontrolowaną demonstracją, ale rzeczywistym pipeline'em szkoleniowym pobierającym wkłady z tysięcy źródeł jednocześnie.😤 To nie jest krytyka projektu. To po prostu szczere pytanie, na które każda poważna deklaracja infrastrukturalna musi w końcu odpowiedzieć.
Powód, dla którego zwracam większą uwagę na OpenLedger niż na większość projektów, nie wynika z dopracowanej mapy drogowej. Chodzi o to, że problem, który rozwiązują, jest naprawdę trudny... a ich architektoniczne podejście uznaje ten trud, zamiast go zatuszować. Rollupy dla skalowalności, kryptograficzne przejścia stanu dla prawdy. Dwa systemy, dwa zadania, jedna księga. Czy to wytrzyma presję, to wciąż otwarte pytanie... Ale przynajmniej jest to właściwe pytanie.
#OpenLedger #CryptoVibes #analysis 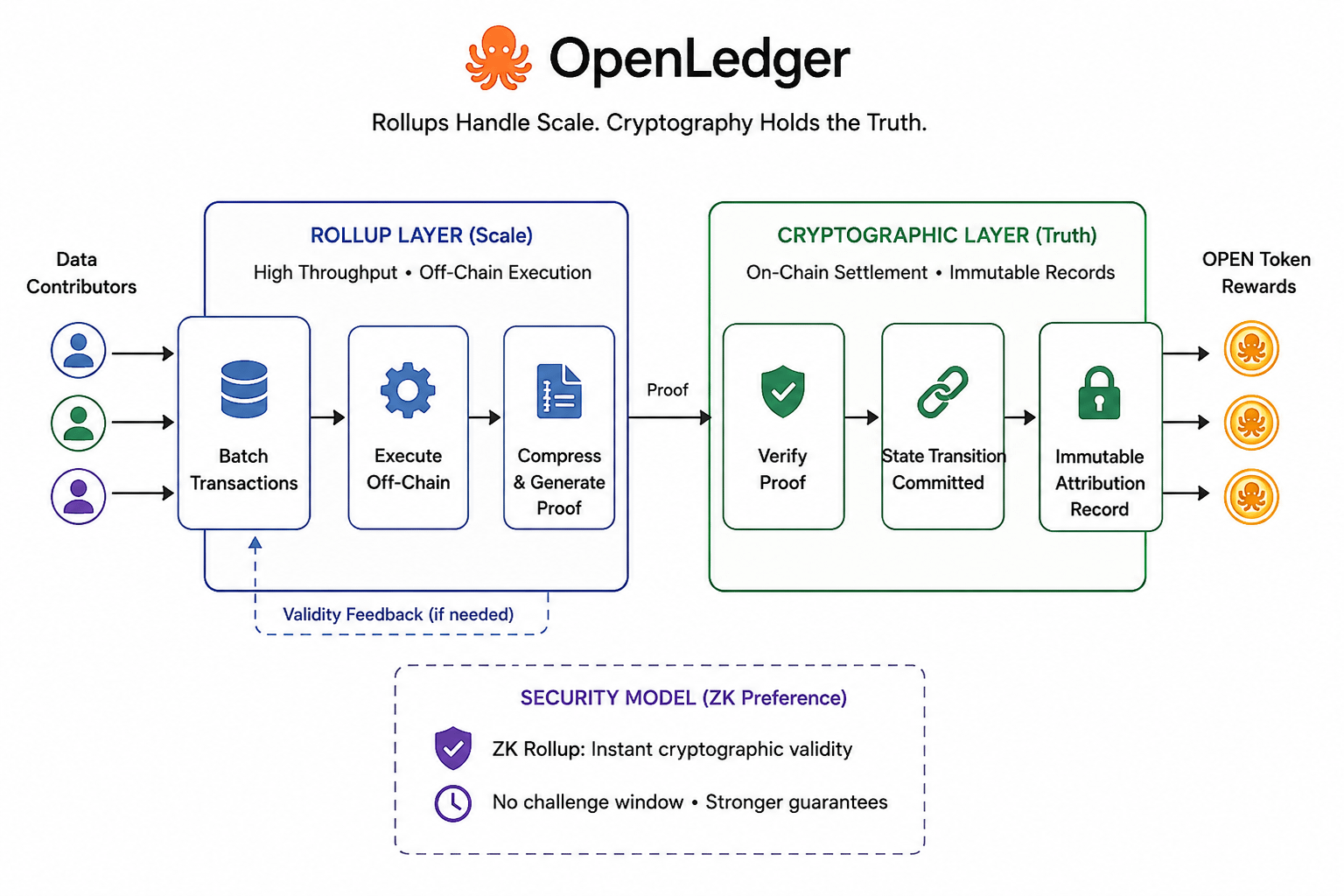
$GENIUS


