10月初那阵子我跟几个老韭菜在茶馆里掰扯行情,手机上突然弹出来一条推送,我瞄了一眼差点把茶喷出来。OpenLedger基金会发公告说要拿1470万美金的企业收入从二级市场回购$OPEN 代币,而且这笔钱的来源清清楚楚——就是企业客户买数据、调用模型付的费用,不是什么印钞机里凭空造出来的流动性。我当时脑子里蹦出来的第一个念头不是“利好”,而是一个更大的问号:到底是什么样的公司会为AI训练数据买单,还愿意用区块链来做结算?
这问题我问过自己很多次。2024年那会儿AI赛道正热,项目方随便披个AI外套就能圈一波钱,但你要问他们生态里到底有没有真正付费的企业用户,十个里有九个半是在画饼。OpenLedger这1470万美金的企业收入,放在Web3圈里或许不算天文数字,但它的信号意义比金额大得多,因为这说明了一件事:现实世界里真的有人愿意为“可验证的AI数据”付钱。
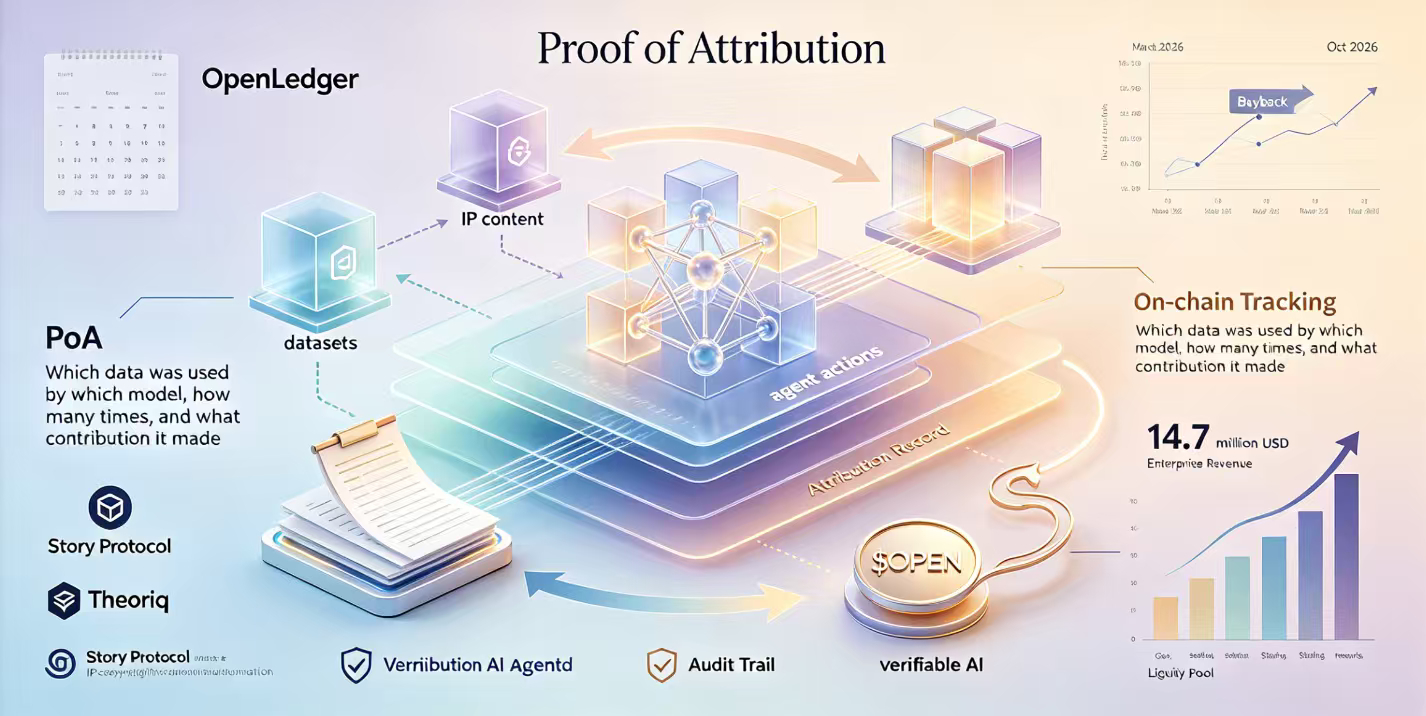
要理解这件事为什么重要,咱们得先搞清楚@OpenLedger 到底在解决什么问题。这个项目做的是AI原生区块链,核心机制叫归因证明,英文是Proof of Attribution。名字听着挺唬人,但逻辑其实不复杂,就是用链上记录的方式追踪“哪条数据被哪个模型用了几次、产生了多大贡献”,然后根据这个贡献度自动把钱分给数据提供者。说白了就是把AI数据当成一件商品来对待,谁贡献谁拿钱,用得越多分得越多。
为啥传统公司愿意掏这个钱呢?答案藏在2026年1月发生的一件大事里。当时Story Protocol跟@OpenLedger 联合宣布搞了一套AI版权自动付费机制,瞄准的是一个估值超过80万亿美元的全球知识产权市场。套机制的核心逻辑是让AI系统在训练或者生成内容的时候,先确认自己有没有使用某个IP的权限,如果用了就自动结算版税。OpenLedger的代表在公告里说了句特别狠的话:AI要从“先训练、后诉讼”转向“只用可证明有权使用的内容”。这话你要是做过AI产品就能品出分量,最近两年AI版权官司打得飞起,训练数据来源不透明是所有大模型公司的原罪,而OpenLedger用链上归因直接从这个原罪下手,给AI公司指了一条不用被告上法庭的路。
同样是1月,OpenLedger还跟Theoriq搞了另一个合作,方向完全不同但逻辑高度一致。Theoriq的AI代理能自主在DeFi市场里执行交易策略、管理资金池、跨协议套利,但问题是你怎么验证这个代理没有在背后偷偷坑你的钱?OpenLedger提供的就是这个“可验证”的部分,把AI代理从推理到执行的每一步都锚定在链上,留下一条不可篡改的审计轨迹。项目方用了个比喻我觉得挺到位——“AI代理现在是没轨道的火车,我们在铺轨”。不管你是在DeFi里跑量化策略,还是用AI做内容生成,OpenLedger想扮演的角色都一样:做AI行为的链上记录层,让每件事都可追溯、可验证、可按贡献分账。
说回OPEN代币本身。很多人的第一反应是“回购利好出了赶紧冲”,但真正值得琢磨的是回购背后所代表的∗∗经济飞轮有没有真的转起来∗∗。OPEN代币本身。很多人的第一反应是“回购利好出了赶紧冲”,但真正值得琢磨的是回购背后所代表的∗∗经济飞轮有没有真的转起来∗∗。OPEN在整个生态系统里是燃料、结算单位和治理凭证。企业用户要用Datanets里的数据集训练模型,得用OPEN支付调用费;数据贡献者收到OPEN支付调用费;数据贡献者收到OPEN奖励之后可以选择继续质押或者变现;代币价格稳定甚至上涨的时候生态各方的积极性都被拉高。回购的作用不是拉盘——至少官方没这么说过——而是拿企业收入买回代币重新注入流动性池,让整个经济循环的血液不至于枯竭。OpenLedger的文档里写得很清楚,首轮回购规模相当于$OPEN 总供应量的1.6%,目标是补充流动性分配,资金来源是持续增长的企业收入。也就是说只要企业继续买数据、继续调用模型,回购就不会停。
这事要是往深了看其实触及了一个更有意思的话题。AI和区块链的结合说了好几年了,大多数项目是拿AI当区块链的马甲,AI两个字往白皮书上一贴就开始发币。但OpenLedger反过来了,它用区块链去解决AI行业自身的痛点,那就是训练数据的来源、定价和收益分配问题。现在市面上大语言模型一个比一个大,训练数据从哪来的基本上是一笔糊涂账。等到监管的铁锤落下来、等到被侵权的创作者联合起来打官司的时候,所有数据来源不透明的AI公司都会面临巨大的法律和商业风险。OpenLedger提前用链上归因把数据来源、授权状态和付费记录都锁定起来,看起来是在给AI行业装刹车,但长远看这个刹车反而是加速器。因为它让AI公司可以用合法的、可审计的方式来获取数据,不用担心某天早上醒来被集体诉讼告上法庭。
不过话得分两头说。2026年3月开始团队和投资人持有的$OPEN代币会逐步解锁,未来三年每个月大约有1800万枚代币进入流通市场,这给价格带来的压力是实打实的。1470万美金的回购能不能对冲掉解锁带来的抛压,本质上是看生态需求能不能跑过供应增长。目前的信号还算积极,企业用户在总用户里的占比大概到了28%,OpenLedger正在推进的AI Marketplace如果能持续拉新,需求的增速是有可能跑赢解锁节奏的。
我对OpenLedger最感兴趣的一个点其实不是现在,而是从2026年1月这波密集合作里能看到的一个趋势:它正在从一条AI区块链变成一个AI经济的结算层。Story Protocol合作解决的是AI版权的结算问题,Theoriq合作解决的是AI代理行为的可验证问题,加上Datanets本身解决的是AI训练数据的定价和分账问题,这三块拼在一起刚好覆盖了AI商业化最核心的三个场景。当一个协议开始成为多个行业场景的基础结算设施的时候,它的代币需求就不会只来自投机者,而是会有真实的商业消耗作为支撑。
当然一切还在很早期。OpenLedger主网2025年9月才上线,到现在一年多一点的工夫,生态里的应用数量和用户规模跟成熟公链完全不在一个量级。企业收入虽然突破了1470万美金的大关,但跟整个AI产业的体量比起来还是九牛一毛。归因证明的技术在极端大规模调用下的执行效率能不能撑住,跨链协作的安全性能不能经得起时间的检验,这些硬核的技术问题没有一个是能轻松搞定的。
但话说回来,我见过太多Web3项目钱烧完了也没弄出一个付费客户,而OpenLedger至少已经证明了自己的经济模型不是空中楼阁。1470万美金的企业收入说大不大说小不小,但它是从真实商业需求里长出来的真金白银,这个性质决定了一切。#OpenLedger