
最近去淘了一张旧显卡,配置好环境加入 OpenLedger 测试网跑起节点。等整套链上记账和结算流程实操跑完一遍,我才算真正看懂了这个项目的底层逻辑。坦白讲,长久以来 AI 行业都有个心照不宣的痛点——数据到底是谁的、收益该怎么分,一直像一滩浑水。而 OpenLedger 这次算是踩中了痛点,直接跳出传统的老套路,用一种挺硬核的打法重新理顺了数据、算力与收益之间的账本。
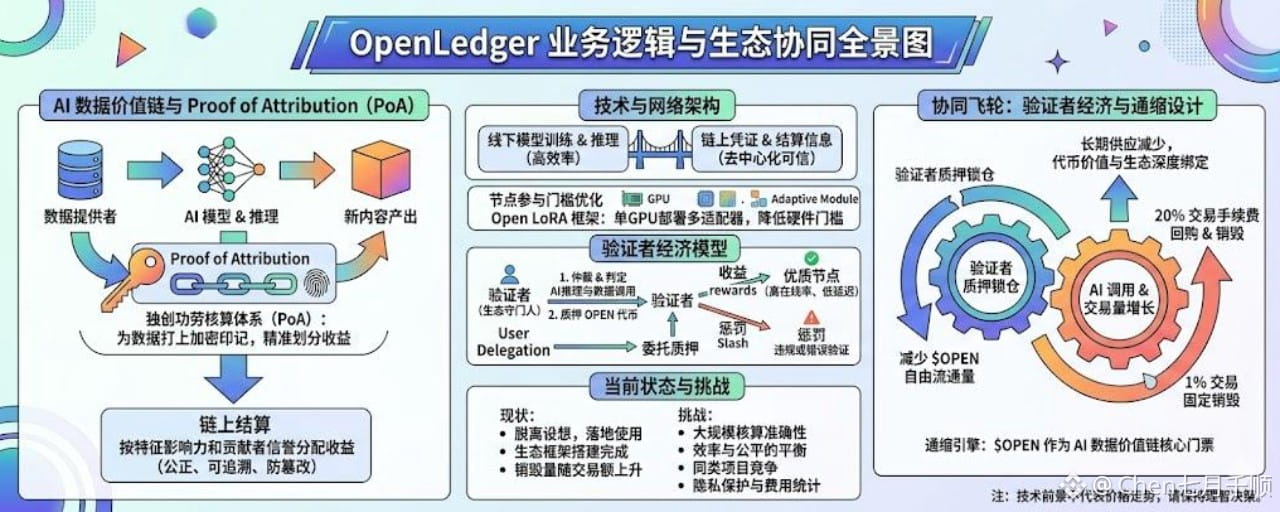
过去咱们看 AI 大模型训练,数据创造者往往是最弱势的。你产出的优质内容被大厂拿去喂了模型,最后赚了大钱,跟普通用户却没半毛钱关系。这个项目最戳中我的一点,就是它给所有进入生态的数据都打上了专属的加密印记。这就好比给数据办了张“身份证”。每当大模型被调用、产出新内容的时候,系统就会顺藤摸瓜,通过它独创的归因机制,去倒推到底是谁的数据出了力、贡献有多大。
这种功劳核算体系最聪明的地方在于,它把过去含糊不清的分钱方式,变成了一套铁面无私的数理规则。系统会根据实际的贡献比重自动划分收益,并在区块链上完成结算。这样一来,以往行业里那些根本算不明白的暗箱操作彻底没了生存空间。只要你付出了优质数据或算力,到手的回报全程公开可查。
不过,分布式网络要能稳定跑起来,光靠一套记账系统肯定不够。在实际体验中,我发现它的节点质押和惩罚机制设计得相当老辣。在这个网络里,验证者不仅是打包数据的节点,更是整个生态的守门人。日常的每一次 AI 推理和归因证明,都需要验证者质押 $OPEN 代币来投票投票确认。要是有人敢动歪心思、验证出错或者故意使坏,质押的代币就会直接被系统扣除。这种把“技术管控”和“真金白银的经济约束”捆绑在一起的做法,才能真正逼着节点去追求极致的在线率和低延迟,也让普通用户敢把代币委托质押给靠谱的节点,一起分一杯羹。
体验过程中,我也一直在琢磨它的架构设计。说实话,以目前区块链的硬件性能和吞吐量,想把动辄百亿、千亿参数的 AI 大模型推理全塞进链上,根本不现实。OpenLedger 走了一条非常务实的混合路线:复杂的 AI 运算和推理放到线下去搞,而关键的资产凭证、归因结果和结算信息则牢牢锁在链上。
配合上模型拆分和轻量化适配这些技术优化,它把硬件门槛拉得足够低。普通人手里的普通显卡,不用像工业级机房那样烧钱,也能轻松接入网络分一块蛋糕。这种对硬件的包容度,对快速壮大整个分布式生态规模来说至关重要。
如果说利益分配和技术架构是这个项目的骨架,那么它的代币经济学就是让整个项目跑起来的血液。很多人关注这个项目,可能只是把它当成一个普通的 Gas 代币来看,但深入研究它的通缩设计后,你会发现这里边藏着一个很有意思的“协同飞轮”。
这个通缩引擎有两个很凶猛的进气口:一个是每笔交易固定销毁 1% 代币的日常消耗;另一个则是平台会将 20% 的交易手续费拿出来,直接从二级市场回购代币并永久销毁。系统每周五都会雷打不动地执行回购,销毁量随着平台交易额的飙升持续水涨船高。
这套硬核的通缩机制,跟前面提到的验证者质押撞在一起,就产生了一种奇妙的化学反应。当生态越来越火爆、加入的验证者越来越多时,大量的代币就会被锁定在质押池里,导致市面上自由流通的代币变少;与此同时,AI 调用和交易越频繁,手续费回购和固定销毁的代币就越多。一紧一缩之间,代币的稀缺性被无限放大。它成功地把代币的价值和生态的实际使用量深深绑定在了一起。正因如此,$OPEN 绝对不仅是个单纯的手续费代币,而是整个 AI 数据价值链里一张高含金量的核心入场券。
从目前公开的生态动向、融资背景以及网络日常的调用热度来看,OpenLedger 已经彻底脱离了“讲故事”的空气阶段,基础框架搭建得有模有样。尤其是随着各路大厂进场和生态合作的推进,链上数据流触发的通缩燃料正在加速消耗。
不过,作为一个亲身参与进去的节点玩家,兴奋之余我也保持着一份理智。毕竟任何硬核机制想要长期运转,都必须面对大并发、大规模启用后的真实考验。比如,当未来调用量呈几何级数增长时,复杂的归因核算算法能不能一直保持高效率和准确性?为了追求速度而调整算法时,又该怎么平衡收益分配的绝对公平?在同类去中心化 AI 项目层出不穷的当下,它如何建立起自己难以被复制的护城河?甚至于如何在不泄露用户原始数据隐私的前提下,完美搞定功劳统计?这些都是需要项目方在后续发展中,用大智慧去慢慢打磨和完善的硬骨头。
说一千道一万,OpenLedger 并没有去画那些虚无缥缈的科幻大饼,而是把目光死死盯在数据确权、收益划分、安全运行这些实打实的行业顽疾上。它的上升潜力和想象空间确实不小。但最后还是得唠叨一句,技术走势和代币价格从来不能简单地画等号,去中心化 AI 赛道瞬息万变,保持独立的思考和理性的分析,永远是你在币圈里最安全的底牌。#OpenLedger @OpenLedger