Data used to be free.
Okay, Let me be honest,Not free as in beer. Free as in worthless. You generated data every day. Your clicks. Your searches. Your location. Your purchases. Companies took it. You got nothing. That was the deal. Implicit. Unequal. Never questioned.
Then the pendulum swung. Data became valuable. Your data is the product. Your data is the asset. Your data is what they're mining. Suddenly everyone was talking about data ownership. Data monetization. Data as property.
But that swung too far. Because most data isn't valuable alone. It's valuable in aggregate. One person's search history is noise. A billion search histories is a treasure. You can't monetize your data by yourself. You need the crowd.
OpenLedger is sitting in the middle of this tension. Between structure and chaos. Between individual ownership and collective value. Between data as free and data as asset. It's a quiet experiment. Most people haven't noticed. But the outcome will affect everyone who uses AI.
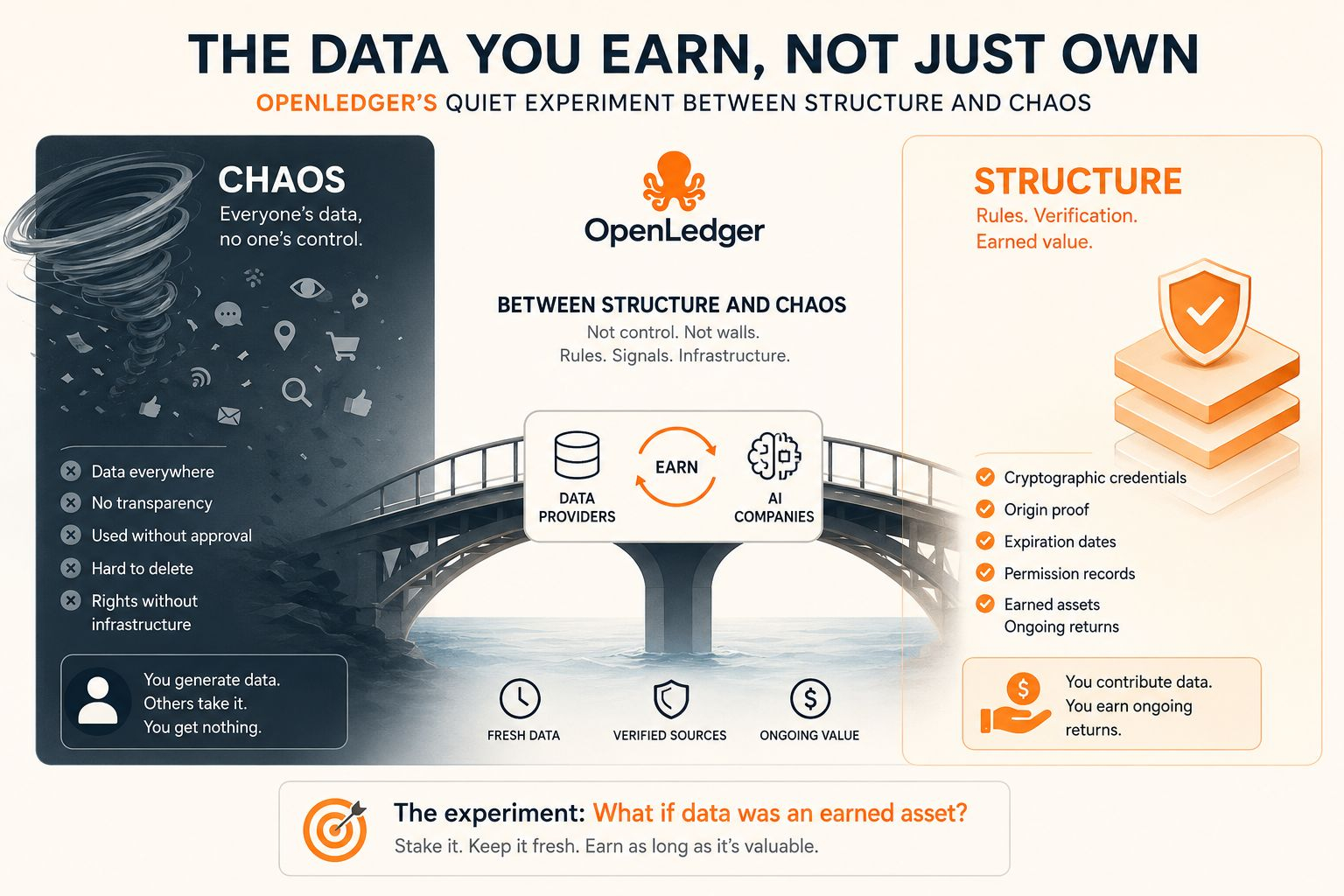
The chaos: everyone's data, no one's control
Right now, data is chaos.
It's everywhere. On servers you don't control. In models you can't see. Used for purposes you never approved. The GDPR and CCPA tried to fix this. They gave you rights. The right to access. The right to delete. The right to portability.
But rights without infrastructure are just words. Try actually deleting your data from a company's AI model. You can't. The model doesn't have a delete button. Your data is in there forever. Baked into the weights. Unreachable. Unforgettable.
This is the chaos. Data exists. You supposedly own it. But you have no real control. No way to enforce your rights. No mechanism to make the model forget.
The structure: OpenLedger's architecture
OpenLedger is trying to impose structure on this chaos.
Not by centralizing data. By attaching rules to it. Every piece of data on OpenLedger comes with cryptographic credentials. A timestamp. An origin proof. An expiration date. A permission record.
When you query data, you don't just get the information. You get the rules. The model knows where the data came from. Knows when it expires. Knows who allowed it to be used.
This doesn't solve the forgetting problem entirely. But it creates the infrastructure for forgetting. The model can choose to ignore expired data. Can choose to prioritize trusted sources. Can choose to verify permissions before using.
Structure, not control. Rules, not walls. That's the OpenLedger way.
The earned asset pivot
Here's where it gets interesting.
Most data marketplaces treat data as something you sell. One-time transaction. You provide data. You get paid. Done.
OpenLedger is experimenting with something different. Earned assets. Data that generates ongoing returns. Not because you sell it once. Because you stake it. You commit to providing ongoing value. You get paid as long as your data remains useful.
This flips the model. Instead of extractive — take your data, pay you once, use it forever — it becomes cooperative. Your data earns as long as it contributes. If it becomes stale or irrelevant, the earnings stop.
I haven't seen this anywhere else. It's subtle. But it changes incentives. Data providers have a reason to keep their data fresh. To keep it accurate. To keep it valuable. Because stale data stops earning.
The chaos that remains
OpenLedger doesn't solve everything.
It can't force models to honor expiration dates. It can only provide the signals. Model owners have to choose to act on them. Some will. Some won't. The chaos of human behavior remains.
It also can't solve the aggregation problem. One person's data is still noise. Value comes from the crowd. OpenLedger helps coordinate the crowd. But the crowd has to show up. Has to participate. Has to trust the system.
And the token economics are still messy. Does $OPEN capture the value of earned data? Or does most value accrue to the data providers directly, with $OPEN just the toll road? I don't know yet.
The experiment in progress
This is all an experiment.
OpenLedger is not claiming to have solved data ownership. They're testing. Building. Iterating. The testnet is live. The code is public. The integrations are growing.
But the core question is unanswered. Will data become an earned asset? Will people stake their data for ongoing returns? Will AI companies pay for verified, fresh, rule-bound data instead of just scraping everything?
I don't know. No one knows. That's why it's an experiment.
What I'm watching
Three things.
First, adoption by data providers. Are real datasets being listed on OpenLedger? Not test data. Real data. Valuable data.
Second, adoption by AI companies. Are they querying OpenLedger for training data? Are they honoring the expiration rules? Are they paying for verified sources?
Third, the earned asset loop. Do data providers actually earn ongoing returns? Or does it become a one-time payment masquerading as something new?
Until I see answers, I'm watching from the sidelines. But I'm watching closely.
Final thought
Data was free. Then data was an asset you sold once. Now OpenLedger is asking: what if data was an earned asset?
What if your contributions generated ongoing returns, as long as they remained valuable? What if stale data stopped paying, creating incentives for freshness? What if the crowd could coordinate without giving up control?
This is the experiment. Between structure and chaos. Between individual ownership and collective value. Between data as free and data as earned.
It might fail. The technical challenges are real. The adoption hurdles are high. The token economics are unproven.
But if it works, it changes everything. Data stops being something extracted from you. It becomes something you earn. Something you stake. Something you own, not just in theory, but in practice.
That's worth watching. That's worth building. That's the quiet experiment happening right now .