I remember the first time I looked at OpenLedger and thought it was mostly about data.
That was my first read: a clean place to register datasets, track them, and move on. Useful, but not dramatic. Almost quiet.
But the longer I sat with it, the more I realized the “data layer” is not the main story. The main story is the space in between—where contribution, usage, and reward actually meet. That messy middle is where most AI products either grow into something reliable… or slowly collapse into noise.
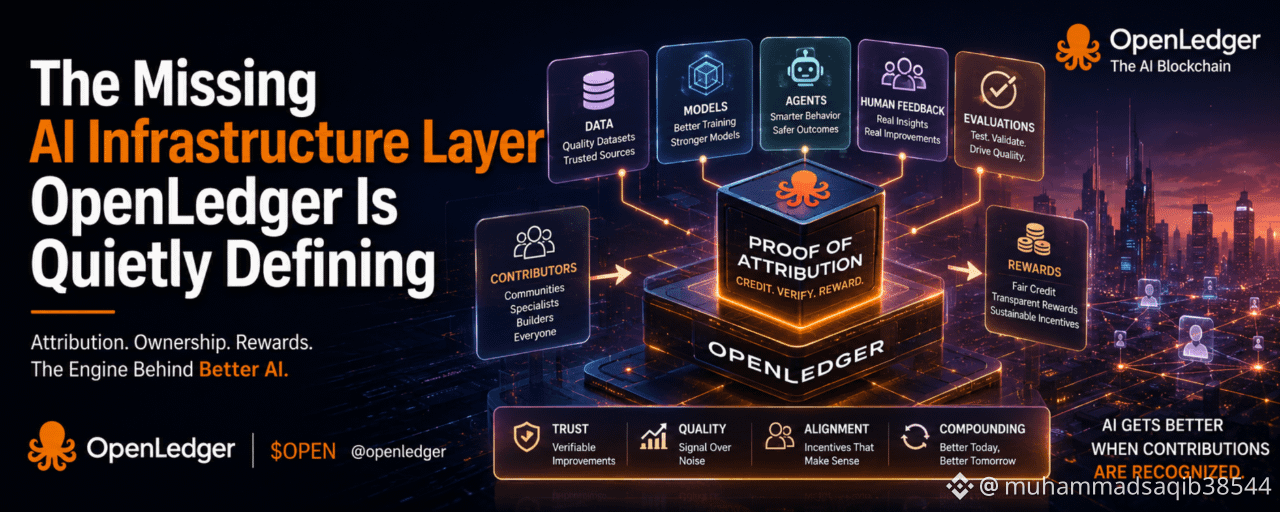
OpenLedger describes itself as an AI blockchain that records contributions on-chain and uses Proof of Attribution to assign ownership, credit, and rewards across data, models, and agents. At first, that sounds like a fancy version of “tracking who did what.”
But it’s a much bigger job than that.
Because in AI, the hard part isn’t building a first demo. The hard part is building a system that keeps improving without losing trust.
The problem most AI builders hit (and why it doesn’t feel “crypto” at first)
If you’ve ever shipped anything AI-powered—even a simple assistant—you’ll recognize this pattern:
You launch something that works “well enough.”
People use it and quickly find edge cases.
Feedback starts pouring in: wrong answers, missing context, unsafe responses, confusing behavior.
You try to improve it.
Then the real questions show up:
Which feedback actually improved the system?
Who contributed that improvement?
Can we prove the improvement happened and wasn’t manipulated?
How do we reward the people who consistently make it better?
How do we stop spam, low-quality data, or “gaming” the system?
Most teams handle this with private logs, internal dashboards, and manual judgment. That works when you’re small.
It breaks when you scale.
And it breaks even faster when multiple people—or multiple communities—are involved. Because AI improvement isn’t only code. It’s evaluations. It’s datasets. It’s carefully written test prompts. It’s human feedback. It’s “this answer is dangerous” flags. It’s “this is the correct definition in my niche” corrections. It’s thousands of tiny contributions that matter, but are hard to measure and easy to forget.
This is where I think OpenLedger is aiming: not to sit beside AI, but to sit inside the improvement loop.
Proof of Attribution, in plain English
Here’s the simplest way I can explain Proof of Attribution:
It’s like receipts for why an AI system became better.
Not receipts in a marketing sense—receipts in a practical sense.
If a dataset helps a model answer more accurately, there should be a trail. If a contributor’s evaluation catches a consistent failure mode, there should be a record. If an agent’s behavior improves because of specific feedback or training examples, that should be attributable.
And once attribution is possible, two big things become possible too:
Ownership and rewards can be fairer (because you can point to impact, not vibes).
Quality can be defended (because you can validate contributions instead of accepting everything blindly).
That might sound “technical,” but it’s really about a simple human problem: people contribute more when the system recognizes the contribution, and people trust systems more when improvements are verifiable.
Why OpenLedger feels like infrastructure, not a feature
A lot of AI projects feel like tools: they help you do a task.
OpenLedger feels closer to infrastructure: it changes what kinds of coordination are possible.
When contributions can be tracked and attributed, you can build AI products that don’t rely on one team doing everything. You can build with communities, specialists, and independent contributors—without turning the whole process into chaos.
That’s the missing layer I don’t see discussed enough.
Most of the “AI + crypto” conversation focuses on funding, tokens, or compute. But the day-to-day friction that kills AI products is usually simpler:
quality control
incentive alignment
accountability
long-term improvement
OpenLedger’s framing puts those problems in the center.
A simple story: a community assistant that doesn’t rot over time
Imagine a crypto community launches an AI assistant for beginners. The assistant answers questions like:
“What is staking?”
“Why do gas fees change?”
“What does slippage mean?”
“How do I spot common scams?”
In week one, people love it. In week two, people start noticing issues:
It explains a concept in a confusing way.
It misses regional context.
It gives advice that is too risky for beginners.
It gets certain token mechanics wrong.
Trolls try to make it say dumb stuff.
Now the community does what communities always do: they try to help.
Some members write better explanations. Some submit examples of scam patterns. Some create test questions that the assistant must pass. Some flag unsafe outputs. Some bring niche knowledge: “In my market, this works differently.”
Here’s the question: how do you turn that messy help into compounding improvement?
Without a system, you get:
random suggestions scattered across chats
repeated arguments about what is “correct”
no reliable way to measure what improved the assistant
no reason for serious contributors to keep doing the hard work
With OpenLedger’s approach, the goal is different: treat those contributions as structured inputs that can be validated, attributed, and rewarded. The assistant doesn’t just “learn.” It improves in a way you can track.
That changes everything.
Because now the community isn’t just consuming an AI tool. The community becomes part of the training and evaluation engine—with incentives that make sense.
The part that matters most: stopping the noise spiral
Every open system has the same enemy: noise.
If you accept every contribution equally, quality drops. If quality drops, serious users leave. If serious users leave, the remaining contributions get worse. And once that spiral starts, it’s hard to reverse.
So when I think about OpenLedger, I keep coming back to one make-or-break point:
Can the validation and attribution system stay strong as volume grows?
If it can, OpenLedger becomes more than “a place to upload data.” It becomes a marketplace where useful contributions compound.
If it can’t, it becomes another funnel that accelerates low-effort inputs.
That’s not a small difference. That’s the difference between “more activity” and “more progress.”
Why this matters right now (the timing feels real)
We’re entering an era where building AI products is getting easier fast. Vibecoding, templates, and agent frameworks are making “first versions” cheap.
When first versions become cheap, two things become valuable:
Trust (is this system reliable and safe?)
Improvement (does it get better over time, in a measurable way?)
That’s why I think OpenLedger’s focus lands at the right moment.
The future isn’t only about who can ship the fastest demo. It’s about who can coordinate contributions without losing quality. And in AI, coordination is the moat.
How I personally judge whether OpenLedger is “working”
I don’t judge it by hype. I judge it by two simple signals:
First: Do AI products built on it keep getting better over time in a way users can feel?
Not just “new features,” but fewer mistakes, better safety, better accuracy, better consistency.
Second: Do contributors keep showing up—and keep contributing quality—because the credit loop is real?
If people can see that good work gets recognized, the system attracts serious contributors. If they can’t, it attracts farmers.
If those two signals hold, OpenLedger is not just another blockchain narrative. It’s a real infrastructure layer for AI—a layer that helps AI systems become trustworthy, community-improvable, and economically sustainable.
And to me, that’s the quiet part that’s easy to miss at first… but hard to unsee once you notice it.

