

Yesterdy at 2:17 AM last night I was starng at a cluster of GPU activity dashboards while Bitcoin, Ethereum moved sideways again candles barely breathing, and honestly the silence felt stranger than volatility. Usually when the market cools down, infrastructure narratives disappear with it. This time I kept noticig the opposite. More developers were stress-testing decentralized AI networks while liquidity across the broader market stayed cautious. That caught my attention fast.
I think a lot of people still underestimat where the next blockchain pressure point is coming from. Everyone talks about bigger models, smarter agents, faster inference. Almost nobody talks about what actually happens underneath once thousands of users start hammering the same network simultaneously. VRAM exhaustion is becoming a real bottleneck now. Not theoretical anymore. Real systems are starting to choke on memory before they even hit compute limits.
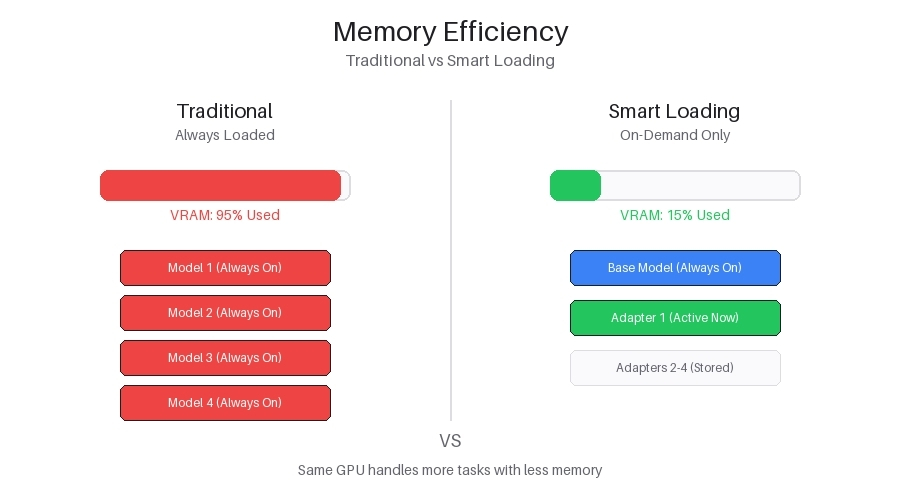
From what I have been watching, most AI infrastructure still treats GPU memory like permanent real estate. Entire models stay loaded into VRAM all day whether requests are coming in or not. That works fine during demos. Feels efficient too. But once traffic spikes, memory fragmentation starts creeping in, response latency stretches out, and suddenly operators are scaling hardware just to survive inefficiency.
That’s the part I think @OpenLedger is trying to rethink.
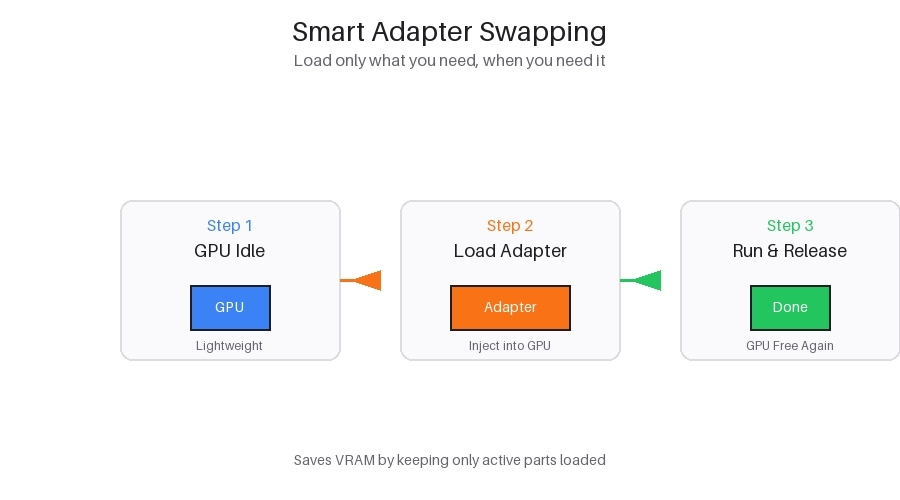
What pulled me deeper into it wasn’t hype. It was the architecture behavior itself. The network reportedly keeps only the essential layers of a base open-source model active inside GPU memory during idle periods. Everything else, especially specialized adapters tied to niche workflows, sits outside the GPU until someone actually needs them.
Simple idea on paper. Bigger implications underneath.
Instead of dedicating separate GPUs to dozens of permanently loaded fine-tuned models, the same machine can rotate between different configurations throughout the day. One request arrives, the system pulls a specific adapter from decentralized storage, injects it into the live model, executes the task, then unloads it again seconds later. GPU returns to a lightweight state almost immediately.
I kept thinking about how different that fels compared to the current direction most AI infrastructure is taking. A lot of projects are brute-forcing scale through heavier hardware requirements. OpenLedger seems more interested in fluidity. Les permanent weight. More temporary execution.
A few hours before Asia opened, I noticed repeated contract interactions tied to small bursts of node synchronization activity. Nothing dramatic. Just strange enough to make me pause. Wallets cycling rapidly, short-duration computational loads appearing and disappearing, almost like the network was rehearsing adapter mobility under pressure. Could’ve been testing. Could’ve been noise. Still felt deliberate.
And you know the technical side is honestly where things get more interesting for me.
The adapter injection reportedly happens directly inside the active inference graph using low-level CUDA optimizations instead of rebuilding the entire model architecture every single time. That matters because full reloads kill responsiveness. If the delay becomes noticeable, users stop caring how elegant the architecture is. They just leave.
From what I understand, the system can even combine multiple adapters simultaneously during execution. Temporary hybrid models. That’s the part I keep circling back to because it changes how decentralized AI networks could evolve economically too. Instead of isolated models competing for dedicated infrastructure, networks could dynamically compose intelligence depending on live demand conditions.
But I’m still skeptical about the coordination layer underneath all this.
The honest part I keep returning to is that downloading adapters nonstop across distributed nodes sounds clean until real traffic hits. Continuous synchronization creates pressure everywhere at once. Bandwidth stability. Cache timing. Driver reliability. Runtime fragmentation. Those problems usually stay hidden until systems operate under sustained stress for weeks, not hours.
And the market is weirdly ignoring that risk right now.
Everybody focuses on compute supply, GPU scarcity, token narratives around decentralized AI. Meanwhile the deeper issue might be orchestration itself. Thousands of adapter swaps happening simultaneously across geographically distributed nodes could introduce instability nobody fully models in testnet conditions.
I had one moment last night where I almost convinced myself this architecture was overengineered. Too many moving pieces. Too dependent on perfect coordination timing. Then I looked again at how quickly VRAM gets consumed under parallel inference loads and suddenly the tradeoff started making more sense.
Especially once quantization enters the picture.
The network reportedly applies aggressive low-bit precision during execution to reduce memory pressure while maintaining throughput under heavy demand. That’s practical engineering, not marketing language. Lower precision means less VRAM usage, faster movement, more concurrent operations. The risk, obviously, is degradation. Push quantization too aggressively and output quality starts slipping in subtle ways users notice before benchmarks do.
Compared to other decentralized AI infrastructure projects, OpenLedger feels less obsessed with raw model ownership and more focused on adaptive deployment efficiency. That’s a meaningful distinction. Some competitors seem designed around static compute allocation. OpenLedger appears to assume instability by default and optimize around rapid reconfiguration instead.
That changes incentive design too.
Nodes aren’t just rewarded for raw compute power anymore. Reliability, synchronization speed, adapter availability, and memory efficiency suddenly become part of the network’s identity. I think that’s the overlooked shift most people aren’t pricing in yet. Infrastructure value may slowly move away from pure GPU accumulation toward operational coordination quality.
Still early though. Way too early to pretend adoption risk isn’t massive.
Real-world deployment depends on whether developers actually trust decentralized execution layers for production workloads. Enterprises hate unpredictability. Latency spikes alone can kill confidence. And if adapter retrieval delays start stacking during peak demand periods, users will notice instantly.
The ripple I’m still sitting with is this: decentralized AI might not fail because models are weak. It could fail because infrastructure coordination becomes too fragile once scale turns chaotic.
That’s what I’ll be watching heading into 2026. Not just model performance. Not token charts either. I want to see what happens when continuous live traffic forces these systems into nonstop adaptation cycles for months without rest.
Because technical demos always look smooth in controlled environments.
The real question is whether decentralized AI networks can survive the messy physics of real-world usage once the markt stops experimenting and starts depending on them.


