Pamiętam, jak pierwszy raz otworzyłem dokumentację Open Ledger i moją natychmiastową reakcją był cyniczny wzrusz ramionami. Patrzysz na te systemy i twoim instynktownym odruchem jest krzyk, że wszystko jest kontrolowane sztywnymi zasadami i duszącymi ograniczeniami, które stoją w sprzeczności z duchem Web3. Ale jeśli zagłębisz się trochę głębiej, zdasz sobie sprawę, że to nie jest chaos, lecz desperacka i celowa próba stworzenia struktury. Muszę być szczery, ponieważ jeśli spojrzysz na powierzchnię, po prostu nie mieści się to w głowie. To nie jest tylko platforma AI lub danych, ale dziwny eksperyment w traktowaniu danych jako aktywów, które można zdobyć.
Warstwa Datanets to doskonały przykład tego tarcia. Jesteśmy przyzwyczajeni myśleć, że Web3 oznacza wszystko bez zezwolenia, gdzie wrzucasz cokolwiek chcesz do protokołu. Open Ledger robi przeciwnie, stosując surowe formaty i walidację, które wydają się prawie kontrowersyjne. Z limitem dziesięciu megabajtów dziennie i ograniczeniem do dwudziestu plików może to brzmieć jak mały piaskownica, ale to naprawdę mądry sposób na ochronę sygnału przed szumem. Gdyby bramy były szeroko otwarte, wszyscy zalaliby strefę, a wartość po prostu zniknęłaby w eterze.
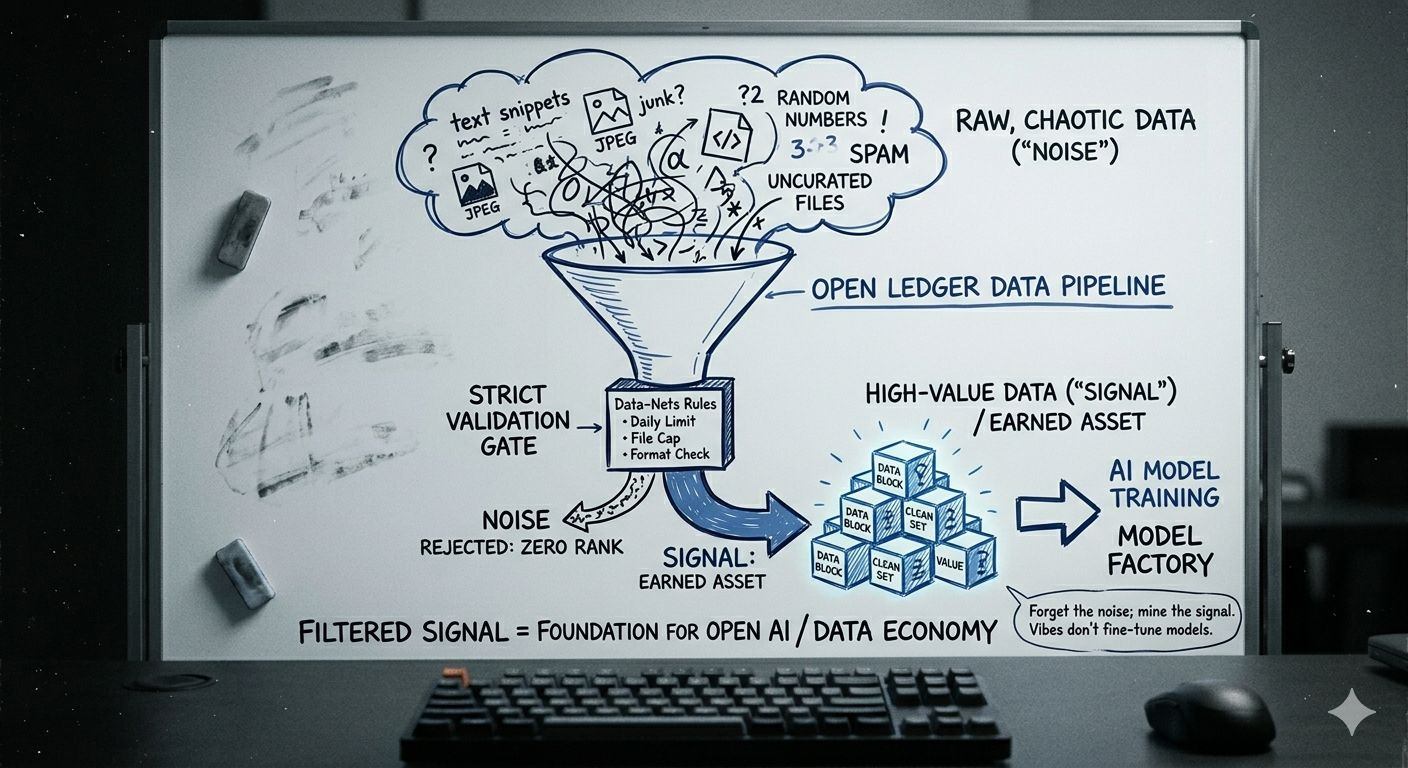
A potem jest tabela liderów, która jest szczerze mówiąc trochę zabawna, jeśli spędziłeś jakikolwiek czas w programach motywacyjnych kryptowalut. Możesz założyć, że wspinaczka na szczyt polega na czystym wolumenie, ale byłbyś w błędzie. Nie chodzi o to, ile plików wrzucisz do systemu, ale o twoją stopę akceptacji. Jeśli wrzucisz dziesięć śmieciowych plików, twoje ego może się powiększyć, ale protokół całkowicie cię zignoruje.
To twarda rzeczywistość, ale jest sprawiedliwa. Jeszcze lepiej, że odrzucone pliki nie obniżają twojej pozycji, co tworzy zaskakująco zdrowe środowisko, w którym możesz eksperymentować bez obaw o kary.
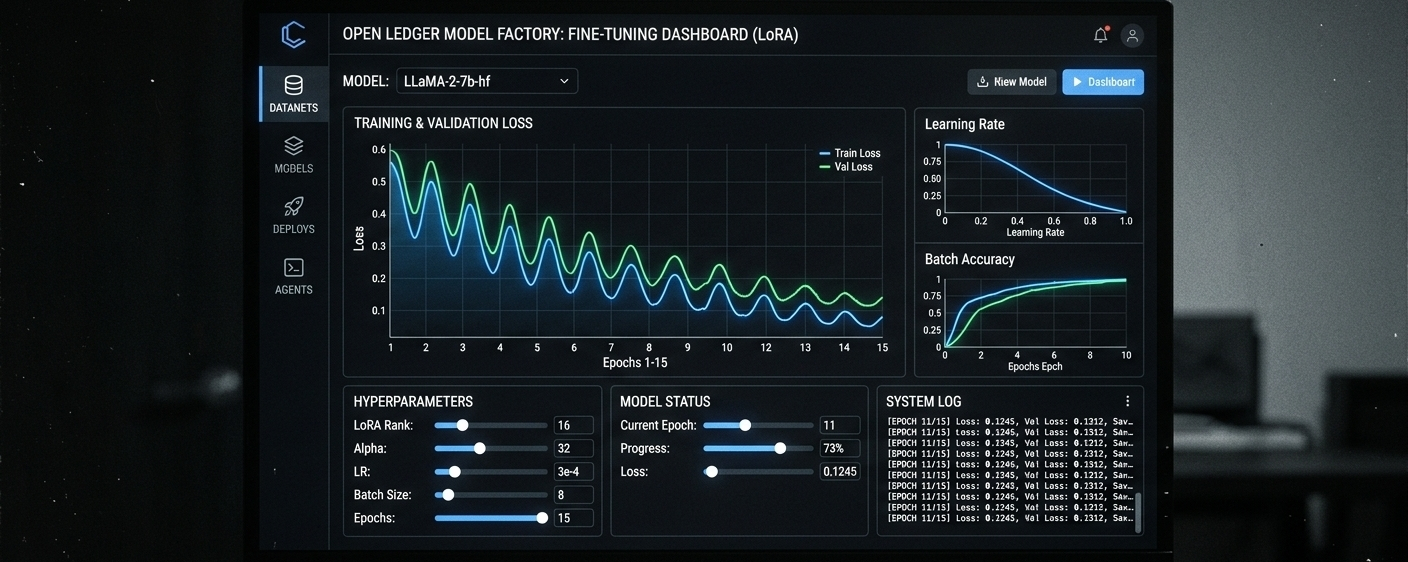
Model Factory to miejsce, gdzie sprawy stają się poważne, a klimat zmienia się z grindowania danych na legitny workflow. Przemieniają tajemniczy proces dostrajania w wizualny interfejs, który w końcu rezygnuje z estetyki terminalowego wojownika. Możesz dostosować stawki uczenia się i rozmiary partii bez potrzeby posiadania doktoratu z uczenia maszynowego.
Choć to wygląda jak zabawka dla początkujących, to tak naprawdę ruch w stronę demokratyzacji AI bez puszczenia kontroli jakości przez palce. Stawiając na LoRA i QLoRA, wybierają ścieżkę lekkiej adaptacji zamiast udawania, że każdy może sobie pozwolić na ogromną moc obliczeniową wymaganą do pełnego dostrajania.
Wsparcie ekosystemu, które zebrali, jest naprawdę imponujące, ponieważ nie gonią tylko za hype'em najnowszych elitarnych modeli. Włączając wszystko, od LLaMA po starsze architektury, takie jak GPT 2, budują ogromną przestrzeń do eksperymentowania. Przypomina mi to ściśle zdyscyplinowaną kuchnię, gdzie nie możesz po prostu wrzucać losowych składników, aby zobaczyć, co się stanie. Musisz trzymać się przepisu, aż gotowanie się skończy, a dopiero wtedy możesz spróbować i ocenić ostateczny wynik. Na pewno nie przetrwasz tutaj tylko na dobrych wibracjach.
Kiedy patrzę na instrukcje agenta i sposób, w jaki traktują URL GitBook jako system wiedzy do zapytań, w końcu to do mnie dociera. Open Ledger stoi dokładnie pomiędzy dwiema ogromnymi napięciami decentralizacji i sztywnej walidacji. Nie jest łatwo znaleźć równowagę, ale jeśli uda im się to osiągnąć, mogą stworzyć prawdziwą gospodarkę danych, a nie tylko kolejną warstwę cyfrowego hałasu. Duże pytanie pozostaje, czy dane naprawdę staną się zasobem, który można zdobyć, czy po prostu nadajemy nową, fajną nazwę tym samym starym problemom walidacyjnym. Jeszcze nie mam odpowiedzi, ale jako eksperyment to zbyt ciekawe, by to po prostu zignorować.
Porównując to do obecnego stanu danych, wygląda to jak czysta laboratoria w porównaniu do szalonego rynku na świeżym powietrzu, gdzie wszyscy krzyczą, ale nikt tak naprawdę nie kupuje nic wartościowego.
\u003cm-34/\u003e\u003ct-35/\u003e\u003cc-36/\u003e