Pamiętam czasy Axie Infinity..... wszyscy mówili, że to nowa ekonomia, ale pod tą ekscytacją kryła się zamek z piasku zbudowany na pompach tokenów. Kiedy OpenLedger mówi, że wkładacze będą zarabiać na opłatach za wnioskowanie, zadaję to samo stare pytanie. Czy struktura jest tym razem naprawdę inna?🤔
Co mnie wkurzało w każdym projekcie wcześniej. Przychodzą po twoje dane, twoje adnotacje, twoje wzorce zachowań, twoje obliczenia. Dajesz to. Model się trenuje. Model działa. Ludzie płacą, żeby go używać. A gdzieś w tym łańcuchu płatności generuje się prowizja za każdym razem, gdy model przetwarza zapytanie. Ta prowizja trafia na platformę. Wkładacz dostaje jednorazową wypłatę, może alokację tokenów, może nic. A ten ciągły przepływ przychodów, który twój wkład umożliwił? Nigdy go znowu nie zobaczysz.😤
To jest strukturalny problem, który większość projektów Web3 AI cichutko pomija. Rozwiązują problem "jak zdobyć dane"... ale nie "jak sprawiedliwie wynagrodzić ludzi, którzy sprawili, że produkt działa".
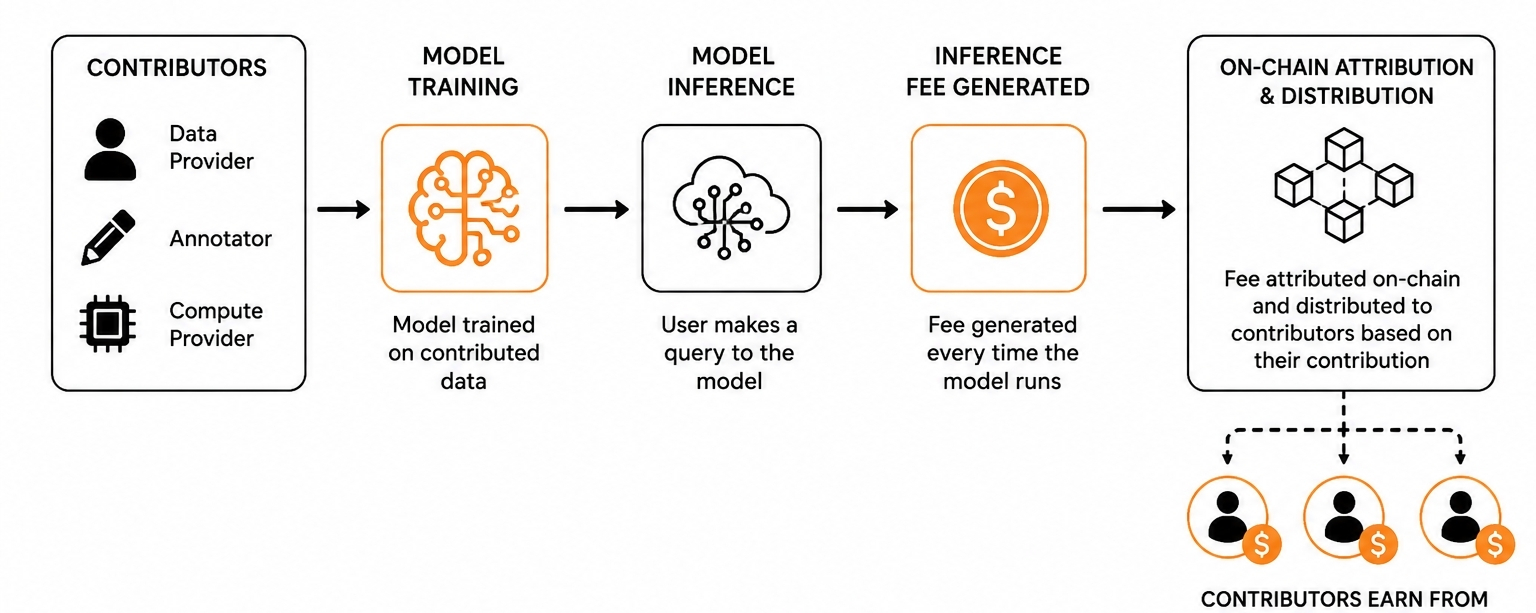
OpenLedger robi coś, co wydaje się proste, ale jest w rzeczywistości trudniejsze do zbudowania, niż się wydaje. Za każdym razem, gdy model trenowany na twoich danych wykonuje wniosek, generowana jest opłata, a ta opłata jest przypisywana z powrotem do wkładników, których dane ukształtowały zdolności tego konkretnego modelu. Atrybucja odbywa się on-chain, co oznacza, że nie jest to obietnica siedząca w wewnętrznej księdze firmy. To jest weryfikowalny zapis. To jest pierwszy mocny punkt, który warto rozważyć, ponieważ atrybucja w czasie wnioskowania, a nie tylko w czasie treningu, jest "naprawdę innym wyborem projektowym."
Drugą rzeczą, którą uważam za wartą zbadania, jest aspekt przejrzystości on-chain. Większość modeli przychodów AI to czarne skrzynki, nawet gdy firmy są technicznie "otwarte". Ufasz, że opłata została wygenerowana, ufasz, że formuła podziału, ufasz, że procent...... Podejście OpenLedger sprawia, że wydarzenie wnioskowania samo w sobie jest śledzalną transakcją. Czy wdrożenie wytrzyma kontrolę to osobne pytanie, ale zamiar projektowy ma znaczenie, ponieważ zmienia to, co oznacza odpowiedzialność w tym kontekście.
Teraz zaczynam zadawać trudniejsze pytania.🧐 Model opłat za wnioski brzmi czysto w teorii. Ale co się dzieje, gdy model jest trenowany na tysiącach wkładników, a jedno zapytanie o wniosek dotyka zdolności kształtowanych przez wszystkich z nich? Jak sensownie podzielić atrybucję w tej złożoności? Czy wkładnik, który dostarczył najbardziej niszowy, ale decydujący punkt danych, otrzymuje proporcjonalne uznanie, czy system spłaszcza wkłady do przybliżonych średnich? To nie jest powód, aby odrzucać model... To jest dokładne pytanie, które decyduje o tym, czy struktura ekonomiczna OPEN rzeczywiście trzyma się na dużą skalę.
Trzeci punkt to to, co naprawdę przykuło moją uwagę, ponieważ OpenLedger zasadniczo argumentuje, że wkład danych to praca, a nie darowizna. To przedefiniowanie ma realne konsekwencje. Jeśli dane to praca, to opłata za wnioski to wynagrodzenie odroczone do momentu, gdy produkt zarobi przychody. To jest bliższe temu, jak muzyk zarabia tantiemy z odtworzeń, niż jak pracownik fabryki sprzedaje swój czas za stałą stawkę godzinową. Model tantiem w muzyce zajął dziesięciolecia i wiele walk prawnych, aby go poprawić. OpenLedger stara się wbudować ten mechanizm natywnie w protokół od samego początku....
Czwartą rzeczą, do której ciągle wracam, jest pytanie, co właściwie oznacza "wkład" na różnych etapach. Wczesni wkładnicy, którzy pomogli w trenowaniu modeli podstawowych, mają większe znaczenie w architekturze niż późniejsi wkładnicy, którzy dostrajali mniejsze funkcje. Czy model opłat za wnioski uwzględnia tę różnicę czasową, czy traktuje każdy wkład jako równoważny? Jeśli model trenowany dwa lata temu nadal generuje miliony wniosków dzisiaj, to ludzie, którzy przyczynili się na początku, powinni teoretycznie nadal zarabiać. Czy to jest sposób, w jaki OPEN rzeczywiście rozdziela, to coś, co dane z sieci na żywo w końcu nam powiedzą.
Po piąte, sceptyczny punkt, którego nie mogę zignorować... to że ten model wymaga od OpenLedger utrzymania bardzo specyficznej dyscypliny operacyjnej w czasie. Systemy atrybucji są łatwe do zaprojektowania i łatwe do cichego erodowania. Firma pod presją finansową mogłaby dostosować formułę podziału opłat, zdefiniować na nowo, co liczy się jako kwalifikujący wniosek, lub po prostu spowolnić on-chain rejestrację wydarzeń. Długoterminowa integralność protokołu zależy od tego, czy zarządzanie jest naprawdę zdecentralizowane, a nie tylko teoretycznie zdecentralizowane, podczas gdy zespół rdzeniowy trzyma klucze decyzyjne.👀
To, co uważam za naprawdę interesujące w OpenLedger, to nie token. To pytanie, które stawia na stole. Jeśli model AI zarabia pieniądze za każdym razem, gdy myśli, a twoje dane nauczyły go myśleć, to co tak naprawdę sprzedałeś, kiedy przyczyniłeś się tymi danymi? Jednorazowy zasób... czy prawo do ciągłego uczestnictwa w komercyjnym życiu tego modelu?
To pytanie jeszcze nie ma czystej odpowiedzi. Ale fakt, że OpenLedger buduje infrastrukturę wokół tego, a nie tylko stawia pytanie w białej księdze, to dlaczego zwracam na to uwagę, uważnie... NIE
entuzjastycznie.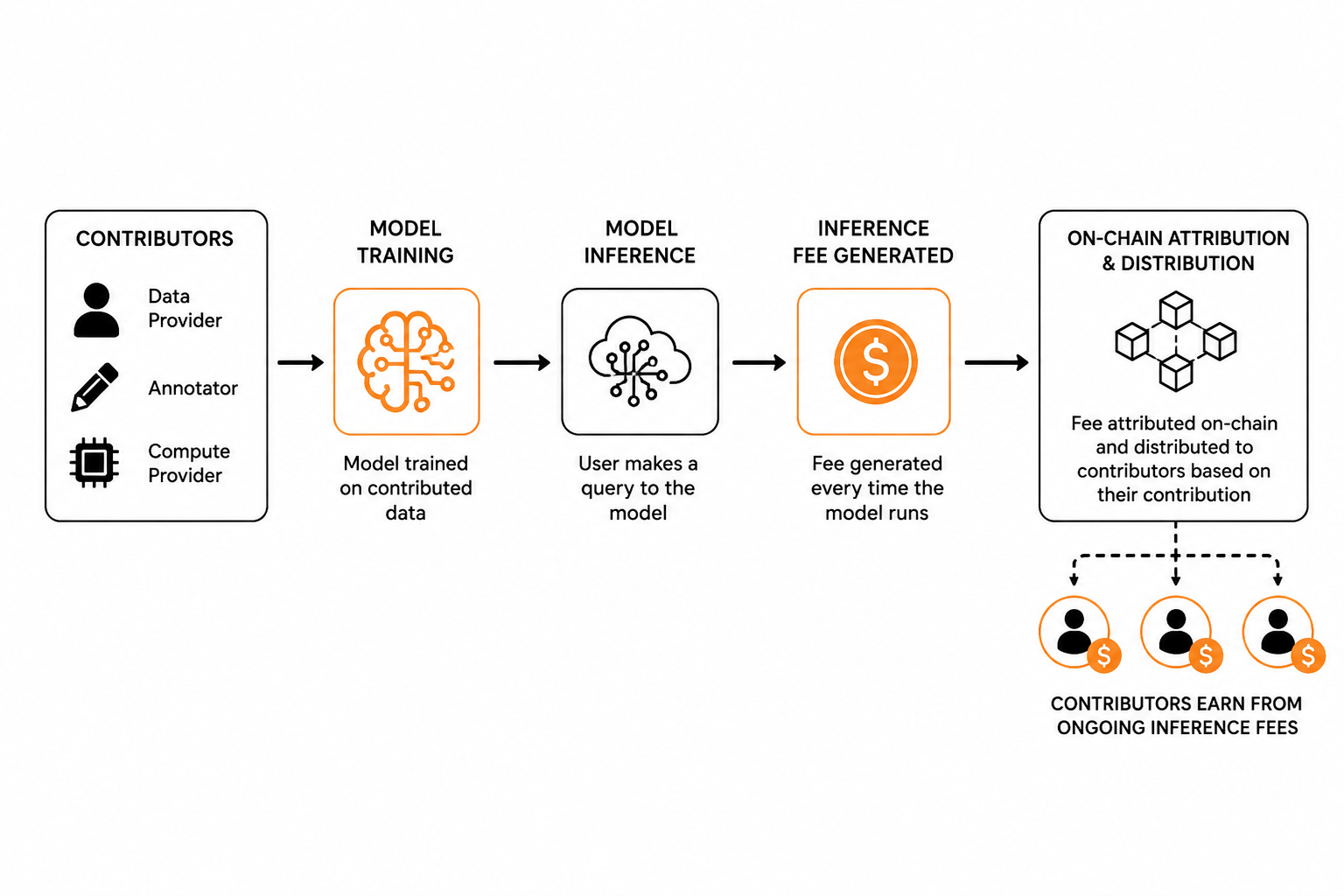
#OpenLedger #dyor @OpenLedger #CryptoVibes


