Skrzyżowanie Web3 i sztucznej inteligencji miało złą reputację przez ostatnie kilka lat. Przez długi czas przestrzeń ta wydawała się niekończącą się pętlą marketingowego szumu, gdzie projekty po prostu nakładały podstawowy wrapper na ogólny interfejs API czatu, przyklejały token i nazywały to rewolucyjnym przełomem. Ale w miarę jak rynek dojrzewa, poważni deweloperzy zdają sobie sprawę, że nie można zbudować zrównoważonej, zdecentralizowanej gospodarki maszynowej tylko na hype'ie.
Tutaj, w prawdziwym świecie, ekosystem AI pędzi w kierunku ściany wartej wiele bilionów dolarów. To branża dręczona problemami strukturalnymi: koncerny technologiczne pożerają dane internetu za darmo, pozwy o naruszenie praw autorskich piętrzą się w setkach, a ogromne koszty sprzętu komputerowego wykluczają niezależnych deweloperów z rynku.
Jeśli zdecentralizowana AI ma przetrwać, nie potrzebuje więcej spekulacyjnych aplikacji. Potrzebuje solidnej, opłacalnej infrastruktury. Dokładnie dlatego OpenLedger (c-119) stał się jednym z najbardziej strukturalnie istotnych breakoutów infrastrukturalnych, które warto obserwować. Nie próbują konkurować z monolitycznymi gigantami Web2, aby zbudować następny masowy, zgeneralizowany silnik czatowy. Zamiast tego cicho budują ekosystem Ethereum Layer 2, dostosowany specjalnie do weryfikowalnych modeli AI.
Przejście od Ogólnych LLM do Specjalizowanej Inteligencji
Aby zrozumieć, dlaczego OpenLedger zyskuje tak dużo trakcji pod maską, musisz najpierw zrozumieć poważne przesunięcie, które zachodzi w szerszym krajobrazie technologicznym. Era prób budowania masywnych, wszechpotężnych modeli, które wiedzą wszystko, staje się niezwykle nieefektywna. Zamiast tego przedsiębiorstwa szukają Specjalizowanych Modeli Językowych (SLM)—wąskich, specyficznych dla dziedziny silników AI trenowanych na wysoko wyspecjalizowanych, czystych i ograniczonych zbiorach danych.
Niezależnie od tego, czy to AI stworzona wyłącznie do analizy lokalnych dokumentów sądowych, analizy konkretnych rekordów medycznych, czy audytowania inteligentnych kontraktów, wyspecjalizowana AI to tam, gdzie żyje rzeczywista użyteczność. Architektura OpenLedger jest wyraźnie zaprojektowana, aby wspierać ten dokładny przesunięcie.
Wykorzystując wydajne transakcje rollup w ramach takich jak Base, Optimism i Polygon, sieć osiąga szybkie prędkości wykonania i minimalne opóźnienia. To ustanawia w pełni płynne, otwarte środowisko open-source, w którym dane, dopasowane modele i automatyczne agenty AI mogą współdziałać, utrzymywać unikalne tożsamości na łańcuchu i płynnie realizować złożone procesy robocze.
Trzy Filary: Datanety, ModelFactory i OpenLoRA
Praktyczna, codzienna użyteczność sieci sprowadza się do spójnej pętli trzech natywnych narzędzi deweloperskich, które drastycznie zmieniają sposób, w jaki budowane i wdrażane są modele AI:
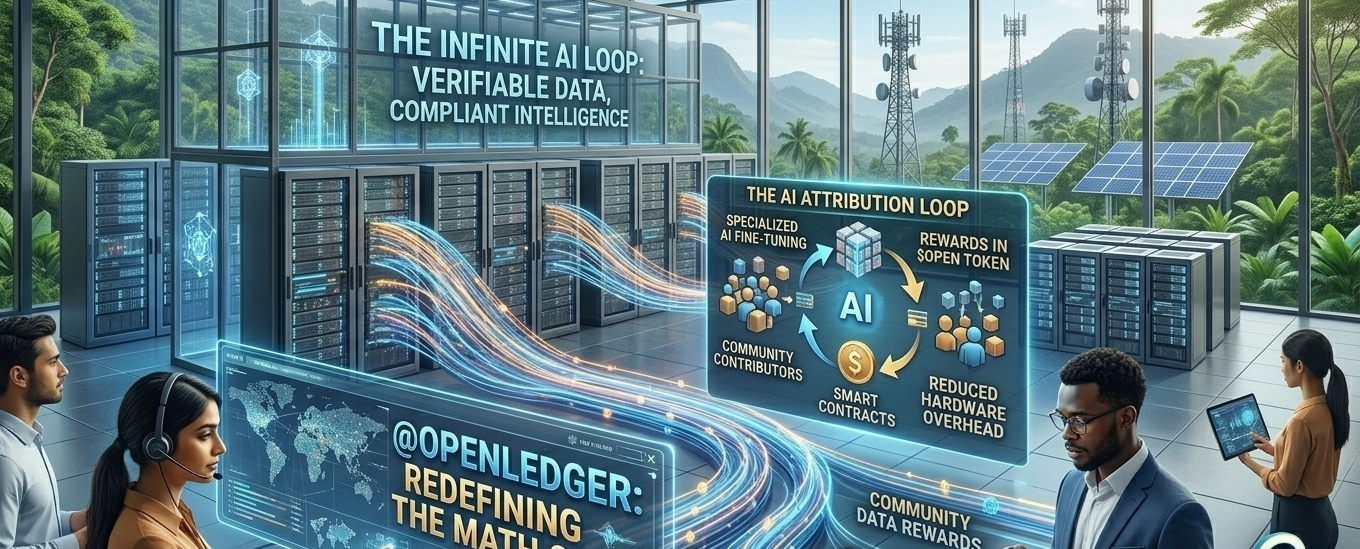
1. Datanety i Proof of Attribution (PoA)
W świecie Web2, zbieranie danych to czarna skrzynka. Wielkie korporacje technologiczne zeskrobują publiczne fora, kreatywne platformy i dane użytkowników, wchłaniając je do swoich modeli bez zapłacenia ani grosza w ramach rekompensaty czy uznania dla oryginalnych twórców.
OpenLedger rozwiązuje to za pomocą Datanetów—zdecentralizowanych, wspólnotowych sieci współpracy danych. Każdy może wnieść wysokiej jakości, zweryfikowane zbiory danych do tych bibliotek.
Kluczowe jest to, że wszystko jest zakotwiczone przez niezmienny mechanizm księgowy na łańcuchu, zwany Proof of Attribution (PoA). Używając zaawansowanych, opartych na wpływie modeli matematycznych, sieć dokładnie oblicza, jak bardzo pojedynczy punkt danych treningowych wpłynął na końcowy wynik modelu AI. Działa to jako niezłomny ślad audytu. Kiedy agent AI generuje wartość, używając tego konkretnego modelu, inteligentne kontrakty zajmują się automatycznymi mikropłatnościami z powrotem do oryginalnych twórców danych. To dosłownie uczy AI, jak płacić za paliwo, które spala.
2. ModelFactory
Historycznie, dostosowywanie modelu AI wymagało specjalistycznej wiedzy inżynieryjnej, biegłości w wierszu poleceń oraz chaotycznych konfiguracji API. OpenLedger obniża tę barierę wejścia za pomocą ModelFactory, całkowicie graficznego, wyłącznie GUI pulpitu.
Dzięki ModelFactory, niezależny deweloper lub przedsiębiorstwo może wybrać model bazowy open-source (taki jak LLaMA, Mistral czy DeepSeek), zażądać danych z zezwoleniem bezpośrednio z repozytorium zdecentralizowanych Datanetów, skonfigurować swoje parametry dostosowywania i przeprowadzać oceny wszystko z jednego pulpitu. Ta demokratyzacja zapewnia, że eksperci z danej dziedziny—tacy jak lekarze, prawnicy czy księgowi—mogą tworzyć wyspecjalizowane narzędzia AI bez potrzeby bycia inżynierami uczenia maszynowego.
3. Ramy Serwisowe OpenLoRA
Nawet jeśli masz idealne dane i dopasowany model, jego hostowanie to ekonomiczny koszmar. Normalnie wdrożenie modelu AI wymaga uruchomienia dedykowanych, niezwykle drogich serwerów w chmurze wypełnionych rzadkimi GPU. Jeśli firma potrzebuje tysiące wyspecjalizowanych modeli niszowych dla różnych klientów lub produktów, koszty sprzętu stają się całkowicie nie do udźwignięcia.
Ramy OpenLoRA OpenLedger wprowadzają infrastrukturę GPU wielo-najemną, która radykalnie zmienia tę matematykę. Zamiast hostować tysiące indywidualnych modeli osobno, sieć hostuje jeden, wcześniej wytrenowany rdzeń modelu. Tysiące małych, wysoko wyspecjalizowanych dostosowań (zwanych adapterami LoRA) "dzieli" tę samą rdzeniową infrastrukturę jednocześnie. To drastycznie obniża koszty obsługi serwera, optymalizuje przepustowość GPU i pozwala systemowi skalować się przewidywalnie bez poświęcania prędkości przetwarzania.
Realny Napływ i Zgodność Prawna
Co odróżnia prawdziwy projekt użyteczności od spekulacyjnego, to adopcja w świecie rzeczywistym. OpenLedger już udowodnił swoją skalowalność, rejestrując ponad 6 milionów zarejestrowanych węzłów, wykonując 25 milionów transakcji na łańcuchu i wspierając ponad 27 aktywnych produktów ekosystemu podczas swoich faz testnet i wczesnej operacyjnej.
Ponadto protokół stawia czoła rzeczywistości prawnej AI. Tworząc głębokie, strategiczne partnerstwa z sieciami własności intelektualnej, takimi jak Story Protocol, OpenLedger zintegrował automatyczny, napędzany przez AI mechanizm płatności tantiem. W miarę jak globalne regulacje stają się coraz bardziej restrykcyjne, a pochodzenie danych staje się ścisłym wymogiem prawnym, możliwość matematycznego udowodnienia, że Twój model AI był szkolony w całości na czystych, legalnie licencjonowanych danych, będzie ogromną przewagą konkurencyjną.
Tokenomika: Zbiornik Paliwa c-151
Całe życie ekonomiczne tej sieci maszyn jest bezpiecznie zakotwiczone przez rodzimy token użytkowy, $OPEN, który ma matematycznie twardo ograniczoną całkowitą podaż 1 miliarda tokenów.
Zamiast polegać na spekulacyjnej manipulacji rynkowej, Open działa jako główny token gazowy ekonomiczny i warstwa oczyszczająca użyteczności dla sieci:
Pętla Podażowa: Deweloperzy i przedsiębiorstwa muszą kupować i wydawać c-68, aby uzyskać dostęp do wyspecjalizowanych bibliotek Datanetów lub płacić za wspólną moc obliczeniową GPU potrzebną do uruchomienia swoich modeli.
Pętla Popytu: Te opłaty wracają bezpośrednio do ekosystemu, nagradzając zdecentralizowanych operatorów węzłów sprzętowych, którzy hostują modele i twórców danych, którzy zasilają sieć.
Dopasowanie Społeczności: Aby zapewnić długoterminową stabilność i zrównoważyć dynamikę podażową, 61,71% całkowitej alokacji tokenów jest ściśle zablokowane i zarezerwowane na nagrody dla społeczności oraz rozwój ekosystemu. Dodatkowo, sieć jest wspierana przez zorganizowany system wykupu ekosystemu finansowany bezpośrednio z przychodów protokołu.
Podsumowanie: Przejście na Odpowiedzialną AI
W miarę jak szerszy rynek kryptowalut zaczyna pozbywać się cykli opartych na memach i domaga się rzeczywistej, mierzalnej użyteczności na łańcuchu, projekty infrastrukturalne, które rozwiązują rzeczywiste wąskie gardła przemysłowe, są naturalnie pozycjonowane, aby prowadzić ten obszar.
Budując przejrzysty, napędzany przez społeczność i hiperwydajny rejestr danych, OpenLedger rozwiązuje dokładnie te problemy związane z własnością danych i kosztami, z którymi tradycyjny sektor technologiczny aktywnie zmaga się. Jeśli chcesz spojrzeć poza zwykły krótko-terminowy hałas na Binance i śledzić rzeczywiste fundamenty kładzione pod przyszłość sztucznej inteligencji, ścisłe obserwowanie rozwoju ekosystemu Open jest bardzo rozsądnym posunięciem.
Jakie są Twoje przemyślenia na ten temat? Czy uważasz, że zdecentralizowana infrastruktura, taka jak OpenLoRA, może realistycznie przełamać monopol Big Tech na sprzęt i dane AI? Zacznijmy dyskusję w komentarzach poniżej! 👇