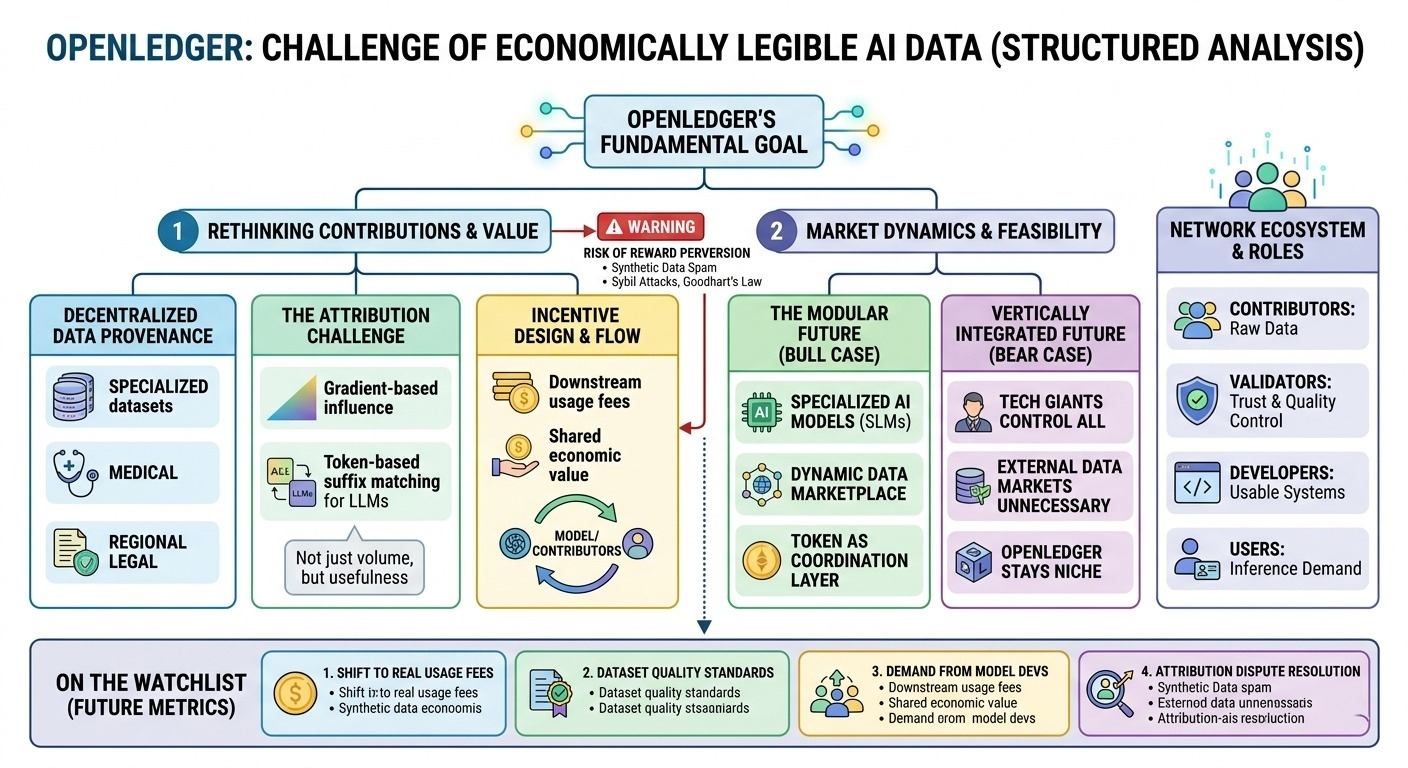
been going through openledger’s architecture over the last few days, mostly around the data attribution and incentive design. honestly, the more interesting part is not the blockchain layer itself. it’s the attempt to make ai contribution measurable in a networked environment.
most people think openledger is just another ai + crypto token. that framing feels incomplete. what caught my attention is that the protocol seems to be building around a harder question: if models are trained on distributed inputs from many contributors, how do you track who created value and how rewards should flow back?
the decentralized contribution system is the obvious starting point. contributors can provide datasets, annotations, feedback loops, or domain-specific information into the network. that could matter for specialized data that centralized systems may not prioritize collecting — things like regional legal documents, medical transcription labels, or niche industrial datasets.
then there’s the attribution mechanism. and this is the part i keep thinking about. ai models absorb patterns across huge mixtures of data. one small dataset might improve model performance more than a massive generic upload. so attribution cannot just be based on volume or activity. the protocol has to estimate usefulness somehow, which immediately becomes messy.
openledger seems to approach this through provenance tracking, validation, and reward distribution tied to downstream usage. in theory, if a dataset materially improves a model or drives inference demand, contributors should share in the economic value created.
honestly, that’s an interesting design goal. but i’m not sure attribution systems stay clean once incentives scale.
because once rewards exist, contributors optimize around the reward function. low-quality synthetic data, duplicated uploads, spam annotations — all of that becomes economically rational unless the verification layer is unusually strong. so the infrastructure challenge is not only decentralized storage or payments. it’s quality control at scale.
the marketplace side is where the long-term thesis either works or breaks. ideally, model developers pay for useful datasets, users generate demand through inference or applications, and contributors earn from actual usage instead of emissions alone. the token becomes coordination infrastructure between all these participants.
but that assumes future ai demand becomes modular enough to need external data markets.
if most commercially valuable ai remains vertically integrated — where the same companies control data, training, distribution, and feedback — then decentralized coordination layers may stay niche. useful for certain edge cases maybe, but not broad enough to sustain large network economics.
who actually creates value here is also more complicated than it first appears. contributors provide raw material. validators provide trust. developers turn inputs into usable systems. users create demand. openledger has to keep those incentives aligned long enough for the network to become economically self-sustaining.
and that is not guaranteed.
watching:
whether rewards shift from emissions toward real usage fees
quality of contributed datasets over time
demand from actual model developers versus speculative participation
how attribution disputes are resolved as the network scales
no clean conclusion yet. openledger might be building useful coordination infrastructure for decentralized ai systems. or it might be trying to bootstrap demand through incentives before the underlying market structure fully exists.