
Konferencja Dartmouth: Gdzie narodziło się „SI”
Latem 1956 roku, John McCarthy, Marvin Minsky, Claude Shannon i Nathaniel Rochester zebrali się na Dartmouth College na Dartmouth Summer Research Project dotyczący SI.
To właśnie tutaj po raz pierwszy użyto terminu „Sztuczna Inteligencja”. Propozycja brzmiała:
„Każdy aspekt uczenia się lub jakiejkolwiek innej cechy inteligencji można w zasadzie tak dokładnie opisać, że maszyna może zostać zaprojektowana do jej symulacji.”
To nie była hackathon koderski. To był plan dla całej dziedziny, wskazujący na sieci neuronowe, wyszukiwanie, rozumowanie symboliczne i język. Marzenie zostało ustalone.
Aby dowiedzieć się więcej:
Konferencja w Dartmouth
Od reguł do uczenia: perceptron
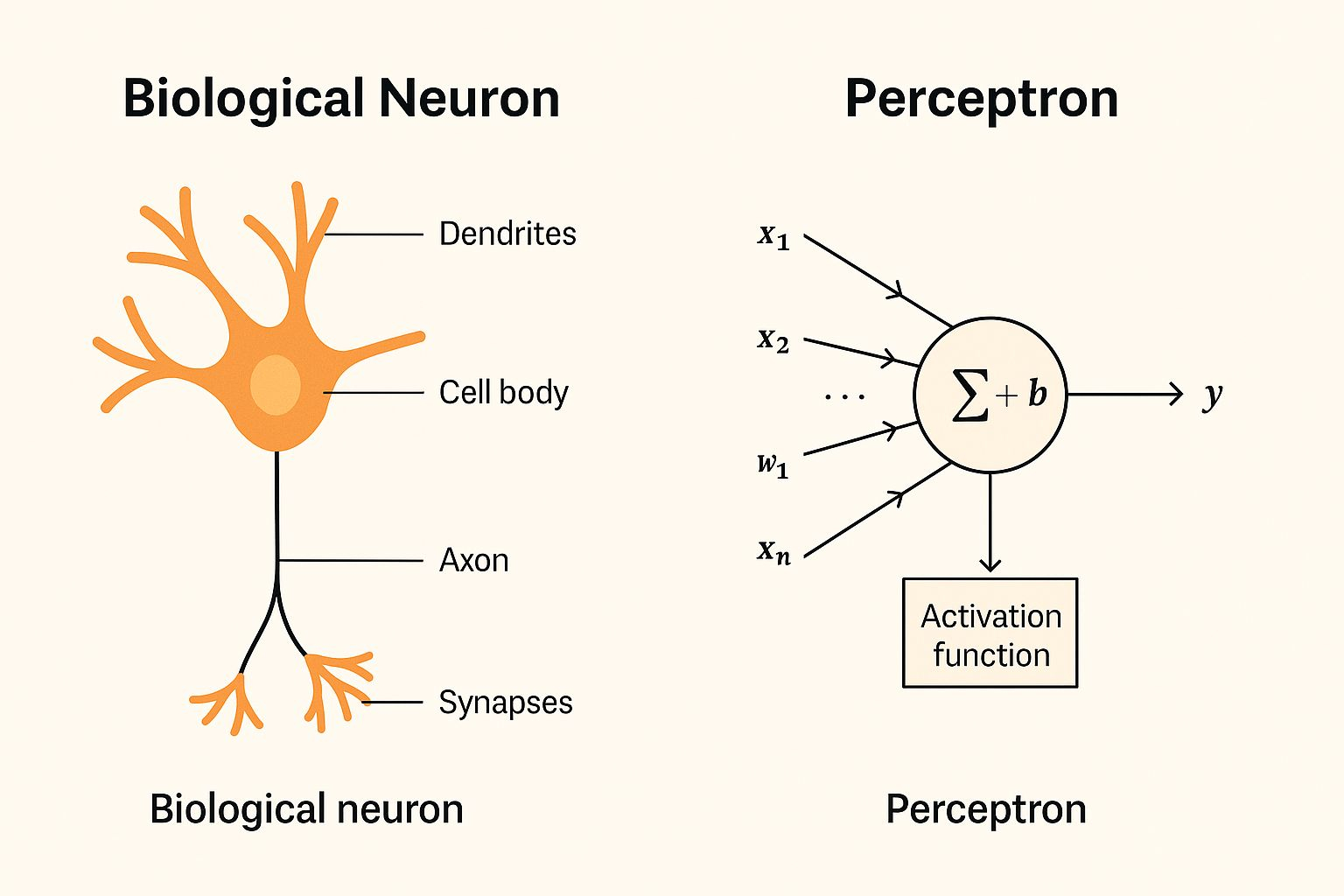
W 1957 roku Frank Rosenblatt zapytał: co by było, gdyby maszyny mogły uczyć się jak neurony? Wprowadził perceptron, pierwszy matematyczny model neuronu.
Perceptron przyjmuje wejścia, mnoży je przez wagi, dodaje bias i przetwarza przez funkcję krokową:
f(x) = h(w ⋅ x + b)
Wejścia (xi) = cechy, takie jak wartości pikseli
Wagi (wi) = znaczenie każdej cechy
Bias (b) = dostosowuje granicę decyzji
Funkcja krokowa (h) = wyjście binarne (1 lub 0)
To sprawiło, że perceptron był klasyfikatorem liniowym, zdolnym do narysowania prostoliniowej granicy między klasami.
Rosenblatt zbudował także sprzęt: Mark I Perceptron (1960). Miał siatkę 20×20 fotokomórek działających jak siatkówka, losowo połączoną z jednostkami asocjacyjnymi, z regulowanymi wagami realizowanymi przez potencjometry. Silniki aktualizowały te wagi podczas uczenia.
Był w stanie klasyfikować proste wzory i wzbudził ogromne emocje. New York Times nawet twierdził, że pewnego dnia mógłby chodzić, mówić i być świadomy (
Archiwum NYT, 1958).

Ale miała swoje ograniczenia: nie mogła rozwiązywać problemów takich jak XOR, które nie są liniowo separowalne.
📖 Dowiedz się więcej:
Perceptron (Wikipedia),
Praca Rosenblatta z 1958 roku (PDF).
Modele językowe i przewidywanie następnego słowa
Równolegle rozwijała się zupełnie inna idea. Czy maszyny mogłyby przewidywać tekst zamiast rozumować logicznie?
Claude Shannon (1948–1951): Mierzył entropię angielskiego, prosząc ludzi o zgadywanie następnej litery. To udowodniło, że język jest statystycznie przewidywalny.
N-gramy (lata 60-te–70-te): Zamiast pełnego rozumowania, przybliżaj, patrząc na ostatnie kilka słów. Model trigramowy przewiduje P(wt | wt−2, wt−1).
Korpora: Brown Corpus (1961) dostarczył 1 mln słów tekstu, umożliwiając testowanie modeli statystycznych.
Aplikacje: Wczesne eksperymenty rozpoznawania mowy w IBM i Bell Labs w latach 70-tych używały modeli n-gramowych z metodami wygładzania takimi jak Good-Turing, a później Kneser-Ney.
To jest ważne, ponieważ nowoczesne LLM-y nadal używają tego samego celu: przewidzieć następny token. Różnica tkwi w skali i architekturach neuronowych, nie w celu.
Dowiedz się więcej:
Kliknij tutaj!
Symboliczna AI i systemy ekspertowe
Po Dartmouth i Perceptronie, wczesne lata były zdominowane przez symboliczną AI. Badacze budowali systemy ekspertowe: programy, które kodowały wiedzę specyficzną dla danej dziedziny jako reguły logiczne.
Przykład: MYCIN (1972) na Stanfordzie. Używał ~600 reguł do rekomendacji antybiotyków na infekcje. W wąskich przypadkach działał tak dobrze, jak lekarze.
Ale symboliczna AI stanęła w obliczu wąskiego gardła pozyskiwania wiedzy. Pisanie i utrzymywanie reguł dla chaotycznych, rzeczywistych dziedzin stało się niemożliwe. To rozpoczęło poszukiwania alternatywy na różne sposoby.
Prolog: Programowanie w logice
W 1972 roku Alain Colmerauer i Philippe Roussel wprowadzili Prolog („Programowanie w logice”). W przeciwieństwie do programowania imperatywnego, Prolog był deklaratywny. Pisało się fakty i reguły, a system wnioskował odpowiedzi.
Przykład:
cat(tom).
mouse(jerry).
hunts(X, Y) :- cat(X), mouse(Y).
Zapytanie: ?- hunts(tom, jerry). → true
Prolog napędzał symboliczną AI i był centralnym punktem Projektu Komputerowego Japonii Piątej Generacji (1982–1992), który zainwestował 400 mln USD w budowę inteligentnych maszyn wnioskowania.
Uczenie maszynowe: dane stają się nauczycielem
📖 Dalsza lektura: Teoria uczenia statystycznego – Vapnik, Podstawy uczenia maszynowego – Mohri, Rostamizadeh, Talwalkar
Do lat 80-tych, symboliczna AI utknęła. Reguły nie mogły uchwycić nieskończonego bałaganu rzeczywistego świata. Nowy pomysł był radykalny: zamiast pisać reguły ręcznie, dostarczyć systemowi dane i pozwolić algorytmowi odkryć reguły samodzielnie.
To oznaczało narodziny uczenia maszynowego. Przejście nie było tylko filozoficzne, ale głęboko matematyczne. Władimir Vapnik i Aleksiej Czerwonienkis sformalizowali tę ideę poprzez Teorię Uczenia Statystycznego.
Głównym problemem była generalizacja: mając skończony zbiór danych treningowych, jak model może dokonywać dokładnych prognoz w przypadkach, których nie widział? Vapnik i Czerwonienkis wprowadzili kluczowe pomysły:
Wymiar VC: miara pojemności klasy modelu
Empiryczna minimalizacja ryzyka (ERM): minimalizuj błąd treningowy
Strukturalna minimalizacja ryzyka (SRM): równoważenie błędu treningowego z złożonością modelu, aby uniknąć overfittingu
To sprawiło, że uczenie maszynowe stało się nauką, a nie zgadywaniem.
Wczesne algorytmy: Drzewa, Bayes i Marginesy
Gdy teoria była na miejscu, praktyczne algorytmy zaczęły kształtować przemysły.
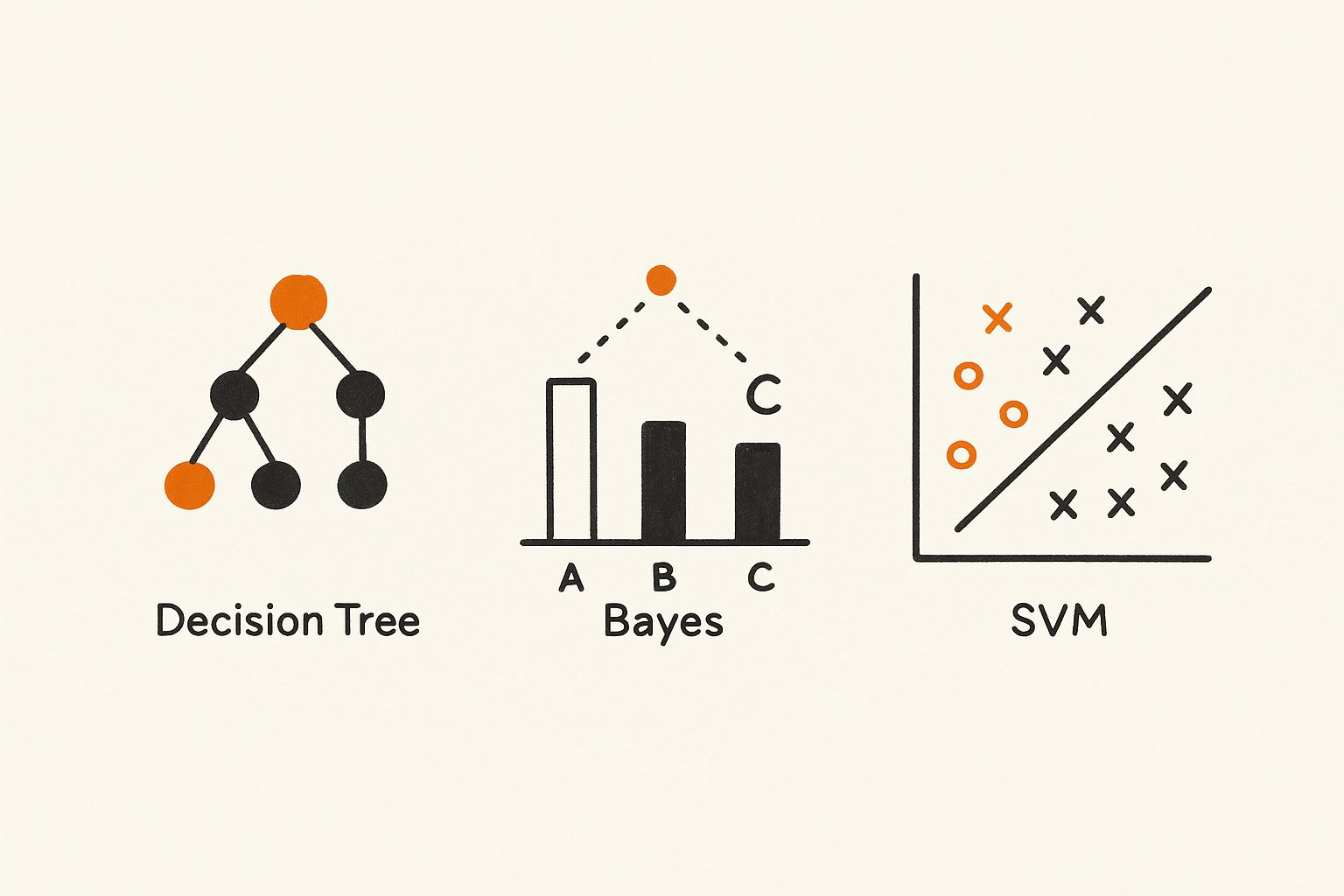
Drzewa decyzyjne
Ross Quinlan wprowadził ID3 w 1986 roku. Drzewa decyzyjne dzielą dane krok po kroku, tworząc reguły if-then bezpośrednio z przykładów. Były zrozumiałe i przydatne w wykrywaniu oszustw, diagnostyce medycznej i segmentacji klientów.
Naive Bayes
Zakorzeniony w twierdzeniu Bayesa, Naive Bayes zakłada, że cechy są niezależne. Pomimo tego uproszczenia, działał dobrze w klasyfikacji tekstu. W latach 90-tych napędzał filtry spamowe i klasyfikację dokumentów na dużą skalę.
Maszyny wektorów nośnych (SVM)
Wprowadzony przez Vapnika w latach 90-tych, SVM miał na celu znalezienie hiperpłaszczyzny, która najlepiej oddzielała klasy, maksymalizując margines. Doskonale sprawdzały się w rozpoznawaniu pisma, wykrywaniu twarzy i bioinformatyce, pokazując silną moc uogólniania w przestrzeniach o wysokich wymiarach.
📖 Dowiedz się więcej:
Uczenie drzewa decyzyjnego (Wikipedia),
Naive Bayes (Wikipedia),
Maszyny wektorów nośnych (Wikipedia).
Sieci i przełom propagacji wstecznej
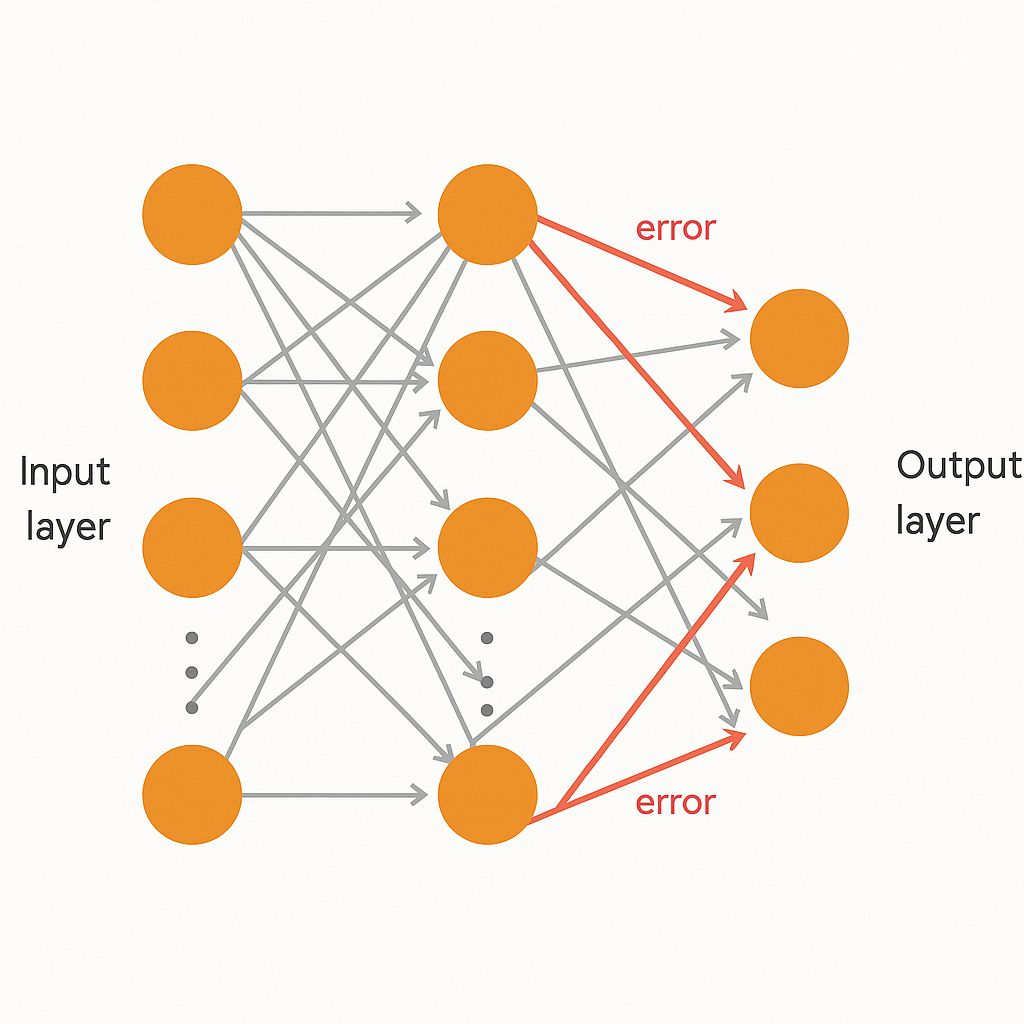
Ludzki mózg buduje zrozumienie w warstwach: od krawędzi do kształtów do obiektów. Pojedynczy perceptron nie mógłby tego zrobić, ale perceptrony wielowarstwowe (MLP) mogły.
W 1986 roku Rumelhart, Hinton i Williams spopularyzowali propagację wsteczną, metodę treningu tych wielowarstwowych sieci. Błędy z warstwy wyjściowej były propagowane wstecznie, dostosowując wagi w wcześniejszych warstwach krok po kroku.
Propagacja wsteczna używała spadku gradientu, przesuwając wagi w kierunku wartości, które zmniejszały błąd. To sprawiło, że MLP były wystarczająco potężne, aby przybliżyć prawie każdą funkcję, co później udowodnił Twierdzenie o Uniwersalnej Aproksymacji.
Chociaż ograniczone przez moc obliczeniową i małe zbiory danych tamtych czasów, propagacja wsteczna położyła fundamenty dla sieci neuronowych, które później zdominowały AI.
Dowiedz się więcej:
Propagacja wsteczna (Wikipedia)
Wnioski: Scena dla nowoczesnej AI
Do lat 90-tych, AI stała na dwóch mocnych nogach. Z jednej strony, algorytmy uczenia maszynowego takie jak drzewa decyzyjne, Naive Bayes i SVM napędzały aplikacje w finansach, opiece zdrowotnej i telekomunikacji. Z drugiej strony, sieci neuronowe z propagacją wsteczną miały teoretyczną moc, aby przybliżyć prawie wszystko, ale były ograniczone przez ograniczenia danych i mocy obliczeniowej.
Obok tych rozwijał się cichszy, ale równie ważny wątek w modelowaniu języka. Od wczesnych eksperymentów Claude'a Shannona z przewidywalnością w angielskim tekście po modele n-gramowe i badania nad rozpoznawaniem mowy, idea przewidywania następnego słowa stała się praktycznym sposobem uchwycenia wzorców w języku.
Gdy w latach 2000 pojawiły się duże zbiory danych, a GPU odblokowały skalę, te trzy nurty zaczęły się zbiegać. Algorytmy napędzane danymi, sieci neuronowe z propagacją wsteczną i tradycja przewidywania następnego słowa połączyły się w to, co teraz nazywamy głębokim uczeniem.
Skromne początki perceptrona, rygorystyczna teoria uczenia statystycznego, przełom propagacji wstecznej i wytrwałość modelowania języka połączyły się, aby stworzyć fundamenty nowoczesnej AI.

W następnym blogu zbadamy, jak sieci neuronowe ewoluowały w CNN, RNN i głębokie uczenie, oraz jak potrzeba mocy obliczeniowej i wąskie gardła w danych ukształtowały scenę dla narodzin transformerów.
OPENLEDGER
\u003ct-338/\u003e\u003cc-339/\u003e
