
Pamiętam, kiedy wszyscy nazywali to "po prostu grą o efektywność"
Pamiętam, jak obserwowałem pierwszą falę hype'u na infrastrukturę serwowania modeli i myślałem, że to po prostu obliczenia w chmurze z lepszym brandingiem. Wspólne GPU, szybsze przełączanie, niższe koszty. Czyste zwycięstwo. Nic głębszego się nie działo. Myliłem się, a zajęło mi to dłużej, niż bym chciał przyznać, by to zrozumieć.
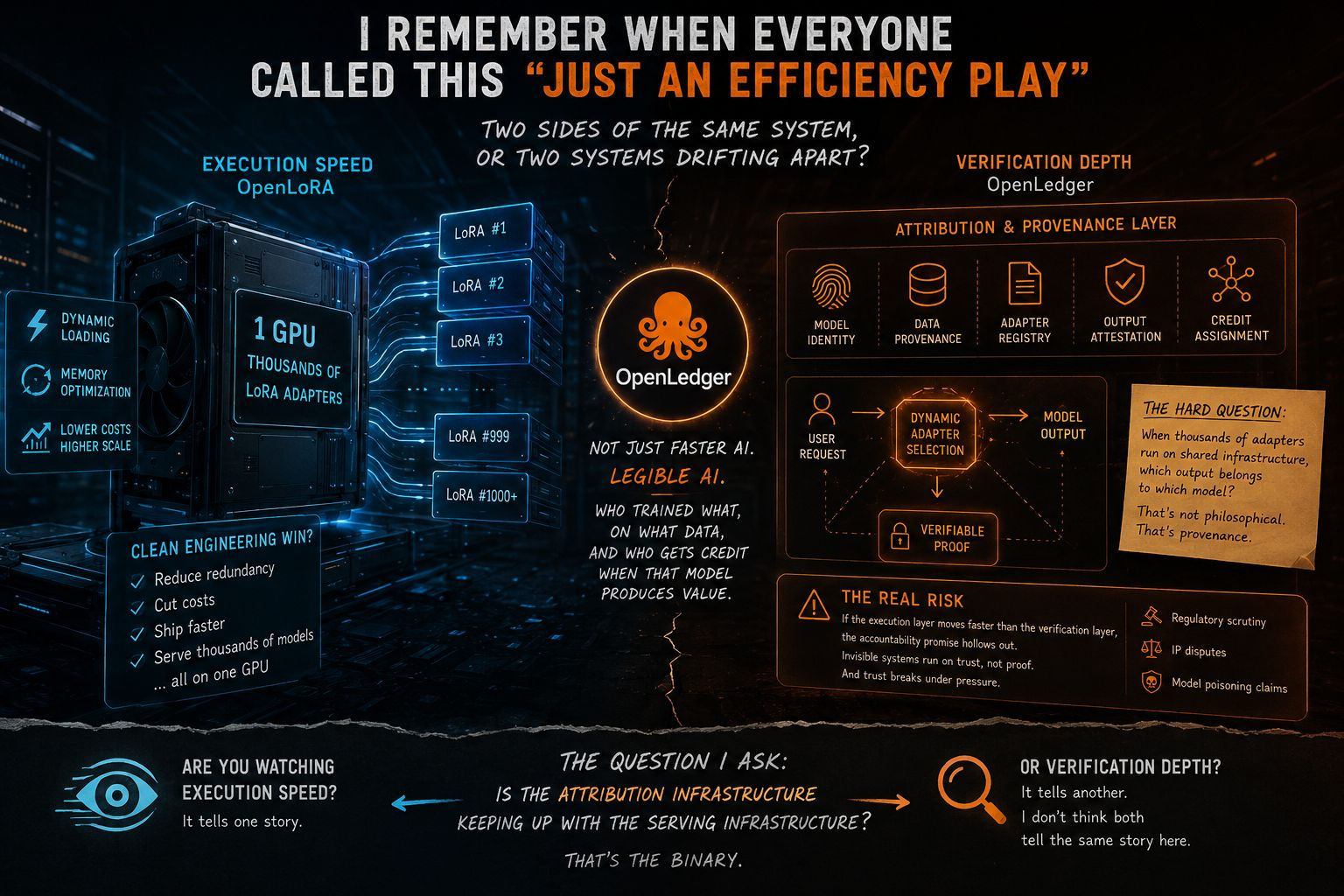
Ale z biegiem czasu zauważyłem coś, co zmieniło moje spojrzenie na ten cały stack. To nie jest historia obliczeń. To historia własności. OpenLedger nie próbuje przyspieszyć AI — próbuje uczynić AI zrozumiałym. Kto trenował co, na jakich danych, i kto dostaje uznanie, gdy ten model generuje wartość. To zupełnie inny problem, i szczerze mówiąc, nikt na to nie zwracał uwagi, podczas gdy wszyscy zajmowali się benchmarkingiem prędkości wnioskowania.
Reframe ma znaczenie, ponieważ OpenLoRA naprawdę robi wrażenie na pierwszy rzut oka. Jedna GPU, tysiące dostosowanych adapterów LoRA, dynamiczne ładowanie, optymalizacja pamięci. Kiedy pierwszy raz czytasz o architekturze, wydaje się, że to czyste zwycięstwo inżynieryjne — zmniejszenie redundancji, obniżenie kosztów, szybsza dostawa. I prawdopodobnie to wszystko jest prawdą. Ale oto, co mnie wciąż zastanawia: kiedy dynamicznie przełączasz się między tysiącami adapterów na wspólnej infrastrukturze, które wyjście należy do którego modelu? To nie jest pytanie filozoficzne. To pytanie o pochodzenie, a w świecie, w którym wyniki AI mają realne znaczenie komercyjne i prawne, ma to ogromne znaczenie.
Z perspektywy rynku, to jest miejsce, gdzie$OPEN nosi prawdziwą kruchość. Jeśli warstwa wykonawcza stanie się wystarczająco abstrakcyjna, a OpenLoRA mocno pcha się w tym kierunku, przypisanie staje się naprawdę trudne. Nie politycznie trudne. Technicznie trudne. Zmiany kontekstu adapterów, stany pamięci współdzielone, cykle dynamicznego ładowania… im szybciej działa system, tym mniej widoczny staje się wkład każdego indywidualnego modelu. Niewidoczne systemy działają na zaufaniu, a nie na dowodach. A zaufanie łamie się pod presją regulacyjną, sporami o IP, roszczeniami o zatrucie modeli. Jeśli warstwa weryfikacji OpenLedger nie nadąża za tym, jak abstrakcyjna staje się warstwa wykonawcza, obietnica odpowiedzialności zaczyna się wydrążać. To jest prawdziwe ryzyko. Nie konkurencja. Nie odblokowanie tokenów. Wewnętrzna spójność między tym, co system robi, a tym, co może faktycznie zweryfikować.

Więc oto, co ja właściwie obserwuję w przypadku$OPEN nie ceny, nie zapowiedzi ekosystemu, nie tweety o partnerstwie. Obserwuję, czy infrastruktura przypisania nadąża za infrastrukturą serwowania. Czy twórcy dostarczają narzędzia weryfikacyjne w tym samym tempie, co narzędzia efektywnościowe? Czy warstwa koordynacyjna staje się z czasem bardziej czytelna, czy bardziej abstrakcyjna? To dla mnie jest binarne. Albo OpenLedger buduje warstwę odpowiedzialności, która sprawia, że OpenLoRA jest godne zaufania na dużą skalę, albo buduje narrację weryfikacyjną na systemie, który już porusza się zbyt szybko, by w pełni zweryfikować.
Dwie strony tego samego systemu, czy dwa oddzielne systemy dryfujące w przeciwnych kierunkach? Naprawdę jeszcze nie wiem. Ale to jest pytanie, które zadałbym każdemu programiście budującemu na tym stosie w tej chwili.
Czy obserwujesz prędkość wykonania, czy głębokość weryfikacji? Bo nie sądzę, żeby obie opowiadały tę samą historię tutaj 👇
