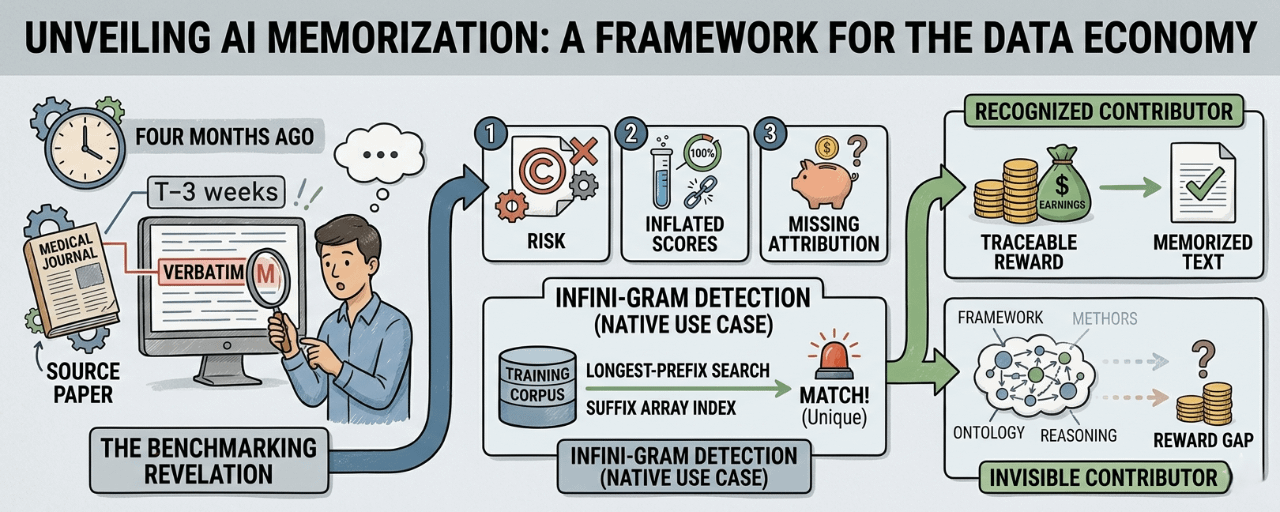
this hapened during a benchmarking session maybe four months ago.
i was evaluating a fine-tuned model on a set of domain questions. medical literature stuff. the model produced an answer that stopped me cold — not becuase it was wrong, but becuase it was word for word correct in a way that felt impossibly precise 😂
i'd read that exact sentance in a paper three weeks earlier. not paraphrased. not synthesized. lifted. verbatim. the phrasing was too specific to be coincidental, the structure too intact to be genuine reasoning.
i spent the next two hours trying to verify it manualy. cross-referencing the output against papers i remembered. found two more instances in the same session. the model wasn't reasoning through domain knowledge. it was reciting chunks of its training data with the confidence of someone who genuinely understood what they were saying.
that's memorization. and it's a genuinly serious problem that most people outside ML research dont think about carefully enough...
here's why it matters more than it might seem.
when a model memorizes training data and reproduces it at inference, three things break simultaneously. first, licensing. if the memorized content is copyrighted, reproduction at inference is a potential violation --- regardless of whether the model owner knows it's hapening. second, evaluation integrity. if benchmark test sets overlap with training data, performance scores are inflated by recitation not reasoning. you're measuring memory not intelligence. third, attribution fairness. if a contributor's exact text is being reproduced verbatim, they deserve credit and compensation- but without a detection mechanism, that link is invisble.
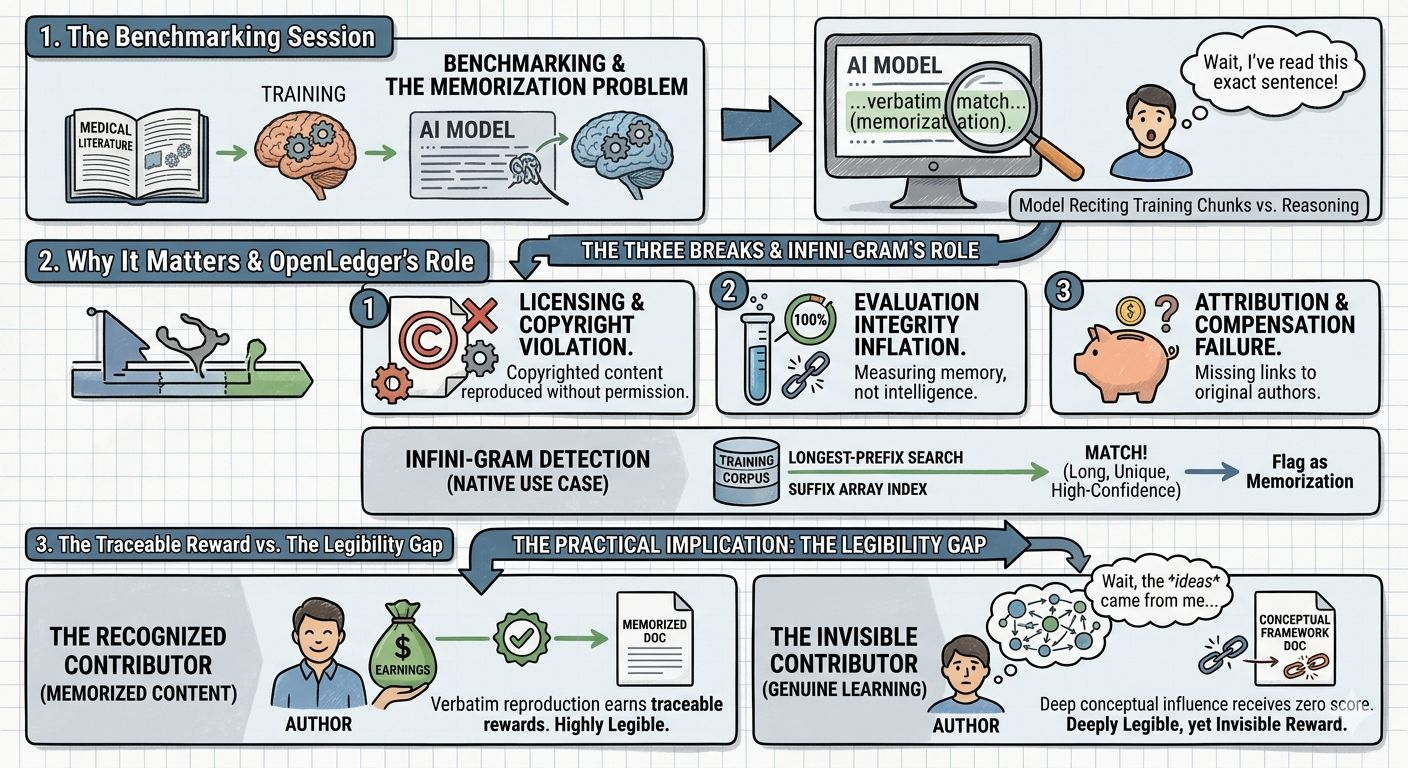
OpenLedger's Infini-gram system handles memorization detection as a native use case...
the suffix-array index built over the training corpus makes this tractable in a way gradient methods simply cant match. when a model produces output, Infini-gram runs a longest-prefix search against the indexed corpus. if the match is l0ng, unique, and high-confidence —if the output span appears essentialy once in the training data—the system flags it as memorization. near-deterministic attribution to a single source.
the practical implication is significant for the data economy specifically...
if a contributor's document is being reproduced verbatim at inference, the attribution score for that document should be high. the contributor should earn from every call that triggers that memorized span. Infini-gram makes that reward flow traceable and verifyable — not a approximation but a match against a permanent index.
the flip side is the one i keep returning to...
memorization detection via suffix matching only catches verbatim or near-verbatim reproduction. a model can internalize an entire conceptual framework from a contributor's work— their reasoning structure, their taxonomic choices, their domain ontology— without reproducing a single exact phrase. that deep influence is invisble to suffix matching. it scores zero on Infini-gram even though the contributor's intellectual contribution shaped every output the model produces in that domain.
so you end up in a strange situation where the contributor whose text got memorised earns more than the contributor whose ideas got learned. memorization is more legible than genuine intellectual influence. and legibility becomes the currency...
honestly dont know if memorization detection ends up protecting contributors whose work is being reproduced, or if it inadvertently creates an incentive to write training data in ways that are more likely to be memorised rather than genuinly learned?? 🤔
