Korzystam z internetu od lat. Wyszukiwarki. Feedy społecznościowe. Algorytmy rekomendacji. I gdzieś po drodze zacząłem zadawać pytanie, którego nie mogłem się pozbyć: kto tak naprawdę czerpie zyski z tego wszystkiego?
Bo to nie byłem ja.....
Każde wyszukiwanie, które przeprowadziłem, każdy post, który polubiłem, każdy wzór mojego zachowania... te dane trafiły gdzieś. Zostały zapakowane. Sprzedane. Zbudowane modele warte miliardy dolarów. A ja dostałem darmowy feed i ukierunkowaną reklamę na buty, które już kupiłem.😐
To nie jest giełda. To ekstrakcja.
A najgorsze? Nigdy nie było umowy. Żadnego podpisu. Żadnej zgody. Tylko warunki korzystania, których nikt nie czyta, i system, który postanowił, że twoje dane mają wartość, tylko nie dla ciebie.
OpenLedger wyraźnie na to zwraca uwagę. I szczerze mówiąc, najwyższy czas, żeby ktoś to zrobił.
Oto liczba, która mnie zamurowała. Meta wygenerowała ponad 130 miliardów dolarów przychodu w zeszłym roku. Prawie wszystko z reklamy. Prawie wszystkie te reklamy były zasilane danymi behawioralnymi twoimi, moimi, wszystkich. A ludzie, którzy generowali te dane, nie otrzymali za to ani grosza. Ani ułamka. Ani tokena. Nic.
Nie oddaliśmy tylko naszych kliknięć. Oddaliśmy nasze wzorce uwagi, nasze intencje zakupowe, nasze polityczne skłonności, nasze harmonogramy snu. Firmy AI teraz trenują modele bazowe na dziesięcioleciach tekstów, obrazów i danych głosowych generowanych przez ludzi, zebranych z otwartego internetu.... Ludzie, którzy napisali te słowa, zrobili te zdjęcia, nagrali te głosy, nie mają żadnego prawa.... Żadnego zapisu.... Żadnej drogi odwołania....
To jest główna niesprawiedliwość, na którą wskazuje tytuł. I myślę, że warto zatrzymać się przy tym słowie niesprawiedliwość..... ponieważ to nie jest przypadek. To wybór projektowy. Obecny internet został zbudowany, aby wydobywać wartość od użytkowników, oddając jak najmniej. To nie była usterka. To był model biznesowy.
Więc dlaczego blockchain nie rozwiązał tego już? To pytanie, które ciągle sobie zadaję. Mamy kryptowaluty od ponad dekady. Mamy portfele, inteligentne kontrakty, DAO, tokenizowane wszystko. A mimo to własność danych pozostała całkowicie nierozwiązana. Szczera odpowiedź jest taka, że większość projektów rozwiązywała problemy z płynnością, a nie problemy z atrybucją. Nikt nie zbudował infrastruktury, aby faktycznie śledzić — na łańcuchu, weryfikowalnie — który człowiek wniósł które dane do którego modelu.
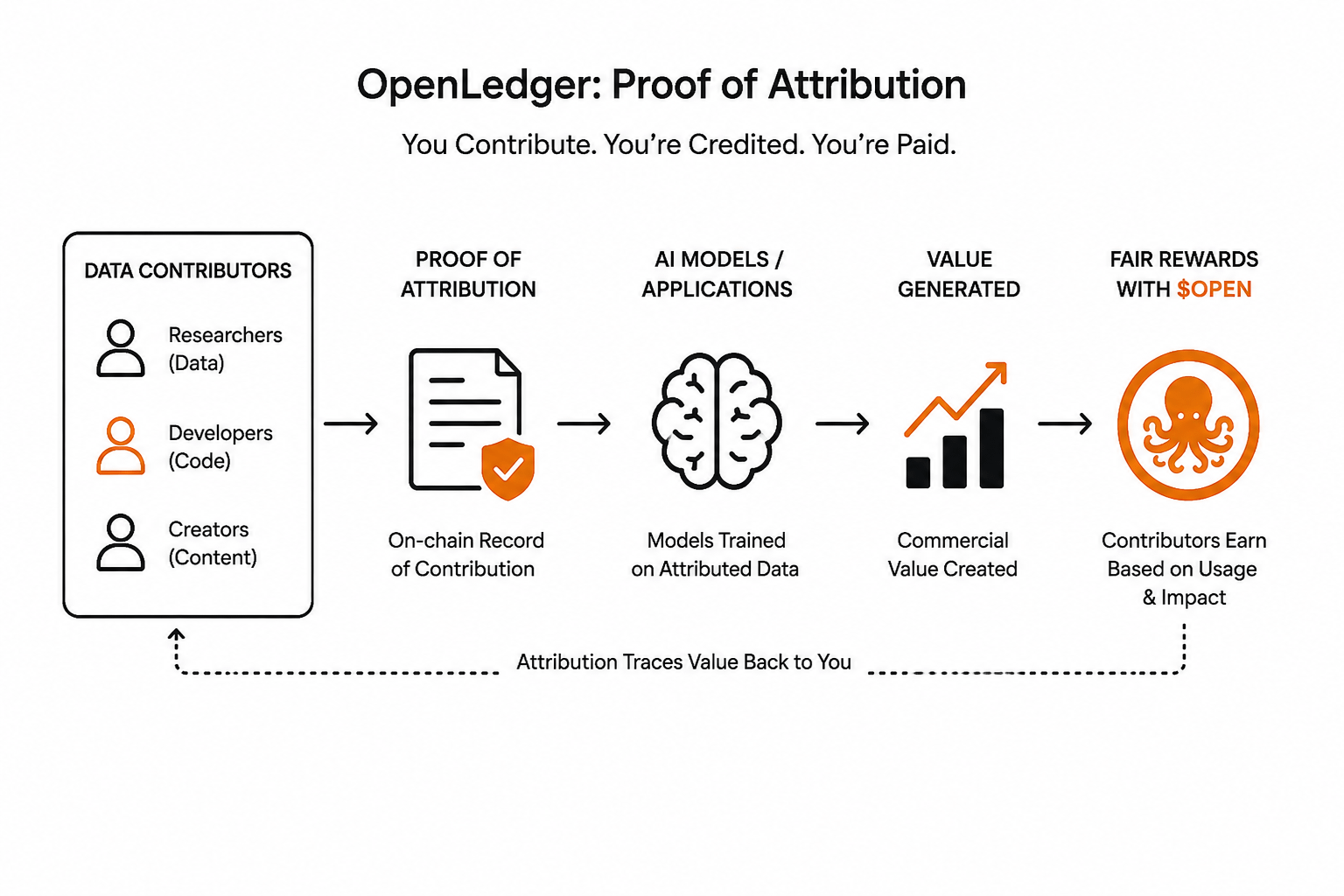
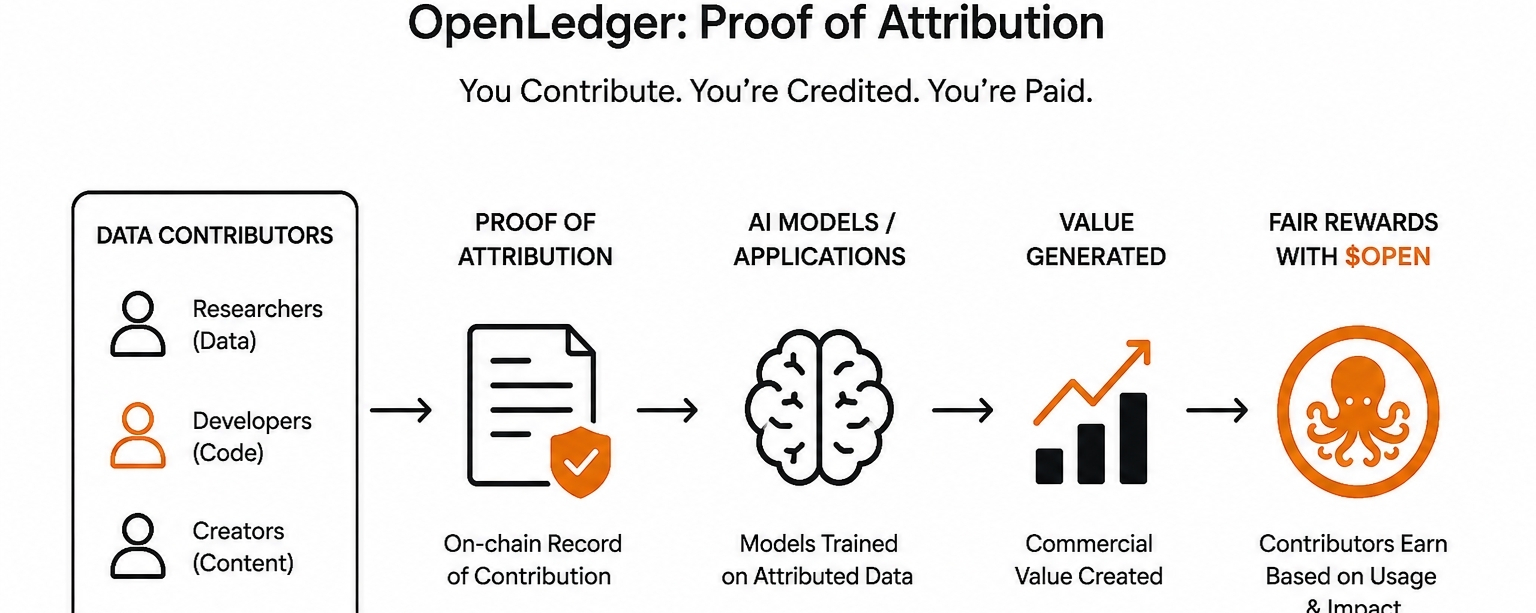
To jest luka, którą OpenLedger próbuje wypełnić.👀
Ich podejście koncentruje się na czymś, co nazywa się Dowodem Atrybucji. Idea jest prosta, nawet jeśli realizacja jest skomplikowana. Kiedy wnosisz dane — czy to dane treningowe, sygnały behawioralne, czy wiedza specyficzna dla danej dziedziny — ten wkład jest rejestrowany na ich blockchainie kompatybilnym z EVM. To nie jest tylko paragon. To żywy, możliwy do zapytania zapis, który łączy twój wkład z jakąkolwiek wartością, która zostaje stworzona z tego. A $OPEN działa jako warstwa użyteczności, która sprawia, że ta atrybucja ma sens ekonomiczny.
Chcę być dokładny, ponieważ różnica ma znaczenie. To nie jest platforma, która płaci ci za przewijanie lub nagradza cię za dzielenie się memami. To twierdzenie jest głębsze. Jeśli twoje dane pomagają trenować model, który generuje wartość komercyjną, łańcuch atrybucji wraca do ciebie. To zasadniczo inna propozycja niż cokolwiek, co widziałem w tej przestrzeni.
Teraz tutaj staję się szczery, a nie promocyjny. Wizja jest spójna. Problem, który rozwiązuje, jest realny. Ale spójne wizje i realne problemy istniały już w kryptowalutach wcześniej, a wiele projektów z oboma nadal nie osiągnęło znaczącej adopcji. Pytanie, do którego wracam, to czy ci, którzy wnoszą dane, których OpenLedger potrzebuje — ci z prawdziwie wartościowymi danymi do treningu — rzeczywiście skorzystają z tego systemu na dużą skalę. Atrybucja ma wartość tylko wtedy, gdy firmy AI są skłonne zapłacić za dane udowodnionego źródła. Ten rynek musi istnieć. Obecnie większość laboratoriów AI nadal działa pod założeniem, że mogą swobodnie korzystać z danych publicznych. Czy regulacje lub presja rynku zmienią tę kalkulację, nie jest gwarantowane.
To, co uważam za naprawdę interesujące, to że OpenLedger nie czeka na tę zmianę. Budują infrastrukturę teraz, aby gdy ta zmiana nastąpi.... a myślę, że w końcu nastąpi — tory już istnieją.
Wyobraź sobie rok 2030 przez chwilę. Badacz w Lagos wnosi oznaczone dane medyczne do modelu diagnostycznego. Programista w Dżakarcie wnosi próbki kodu do systemu generowania kodu. Obaj otrzymują weryfikowalne zapisy o atrybucji i nagrody w postaci $OPEN proporcjonalne do tego, jak często ich wkłady są wykorzystywane. To nie jest fantazja. To tylko to, jak ten system wygląda, jeśli działa.
Internet zbudowano na twojej uwadze. Pytanie brzmi, czy następna wersja zostanie zbudowana na twoich warunkach..... czy po prostu znajdziemy bardziej wyrafinowany sposób, aby znowu oddać tę wartość za darmo.
Obserwuję OpenLedger uważnie. Nie dlatego, że tego wymaga hype. Ale dlatego, że pytanie, które stawia, to coś, na co nikt inny jeszcze nie odpowiedział.🤔
@OpenLedger #OpenLedger #CryptoVibes