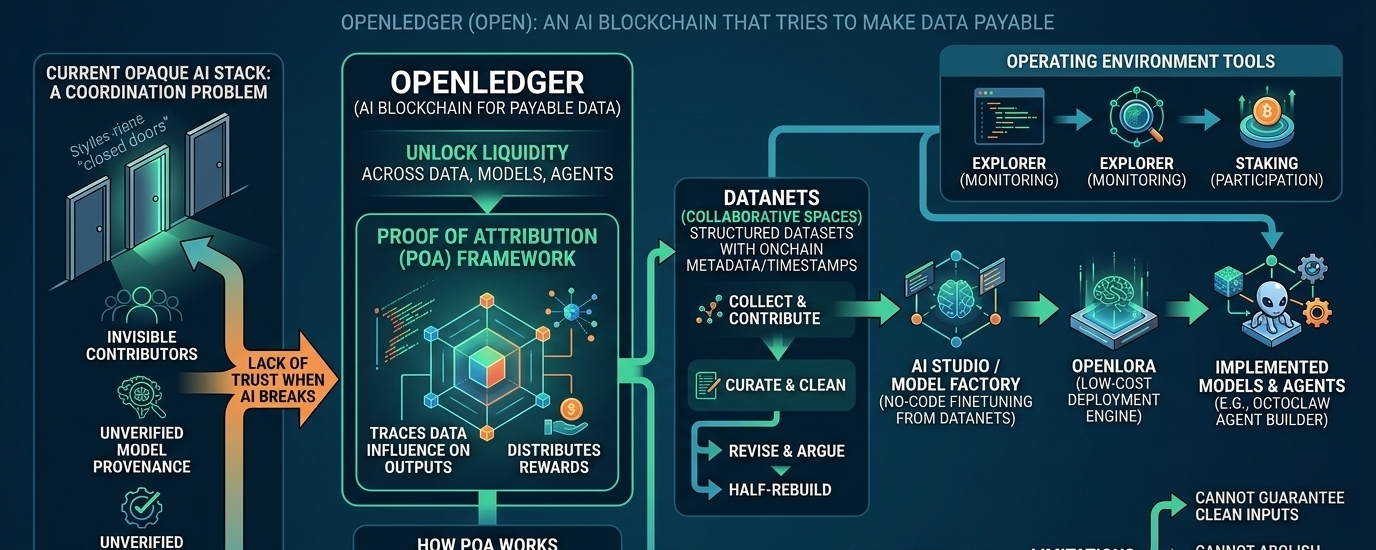

OpenLedger próbuje rozwiązać problem, który jest ignorowany, gdy AI działa płynnie, a staje się oczywisty, gdy coś zaczyna się psuć. Projekt opisuje się jako blockchain AI zbudowany w celu odblokowania płynności w danych, modelach i agentach, z dowodem przypisania w centrum systemu. Mówiąc prościej, stara się stworzyć miejsce, gdzie źródła zasilające AI mogą być śledzone, wyceniane i nagradzane, zamiast znikać w czarnej skrzynce po wytrenowaniu modelu. To poważny cel, i ma znaczenie, ponieważ systemy AI stają się znacznie trudniejsze do zaufania, gdy nikt nie może jasno powiedzieć, skąd pochodzą dane wejściowe lub kto powinien z nich korzystać.
Czytałem, że to odpowiedź na problem koordynacji bardziej niż czysto techniczny problem. W spokojnych warunkach, scentralizowane staki AI wydają się wystarczająco efektywne. Firma posiada dane, szkoli model, wdraża go i prowadzi księgowość w jednej organizacji. Ale gdy dane pochodzą od wielu uczestników, gdy modele są ponownie wykorzystywane, a agenci zaczynają działać w czasie rzeczywistym w różnych przepływach pracy, prosta wersja własności zaczyna się rozpadać. Publiczne materiały OpenLedger wielokrotnie wracają do tego punktu: większość AI działa za zamkniętymi drzwiami, uczestnicy są niewidoczni, a pochodzenie modeli jest trudne do zweryfikowania. Projekt stawia na to, że te luki są nie tylko denerwujące, ale ekonomicznie ważne.
Dlatego język protokołu dotyczący atrybucji jest czymś więcej niż brandingiem. OpenLedger twierdzi, że jego ramy Proof of Attribution pozwalają śledzić, jak dane wpływają na wyniki modeli i rozdzielać nagrody na podstawie tego wpływu. Biała księga opisuje podejście podwójne: metody funkcji wpływu dla mniejszych modeli oraz atrybucję tokenów opartą na tablicach suffixowych dla większych modeli językowych. Mówi również, że system rejestruje pochodzenie treningu, aby nagrody uczestników mogły być powiązane z użyciem modelu w czasie wnioskowania. To istotny wybór projektowy, ponieważ przekształca dane z niejasnego wejścia upstream w coś, co protokół próbuje traktować jak aktywo z zapisem.
Datanety projektu to kolejny główny element obrazu. OpenLedger przedstawia Datanety jako przestrzenie współpracy, gdzie ludzie mogą zbierać, wnosić i kuratować specjalistyczne zbiory danych. Biała księga opisuje każdy DataNet jako strukturalny zbiór danych wniesiony przez jednego lub więcej użytkowników, z metadanymi i znacznikami czasu rejestrowanymi na łańcuchu. Z mojego punktu widzenia, to jedna z bardziej praktycznych części projektu, ponieważ odzwierciedla, jak naprawdę odbywa się praca z danymi. Dobre zbiory danych rzadko powstają dzięki samotnemu geniuszowi w próżni. Są zbierane, czyszczone, poprawiane, omawiane i czasami pół-odbudowywane po tym, jak pierwsza wersja okazuje się mniej użyteczna niż oczekiwano. System, który próbuje zachować tę historię, przynajmniej wskazuje na realną operacyjną potrzebę.
OpenLedger mówi także o szerszym zestawie narzędzi wokół tych zbiorów danych. Jego publiczny blog i strona odnoszą się do AI Studio, Model Factory, OpenLoRA, Explorer, Staking i OctoClaw. Blog mówi, że Model Factory to interfejs bez kodu do dostosowywania modeli z Datanetów, a OpenLoRA jest opisany jako silnik wdrożeniowy mający na celu drastyczne obniżenie kosztów uruchamiania modeli. OctoClaw jest przedstawiony jako warstwa budowy i realizacji agentów w czasie rzeczywistym. W połączeniu, to próbuje wyglądać mniej jak pojedyncza funkcja blockchaina, a bardziej jak środowisko operacyjne dla przepływów pracy AI. To ma znaczenie, ponieważ infrastruktura staje się użyteczna, gdy redukuje tarcia dla rzeczywistych budowniczych, a nie tylko rejestruje aktywność po fakcie.
Jednak trudna część nie polega na normalnej operacji. Trudna część to to, co się dzieje pod presją. W cichym rynku zespoły mogą udawać, że atrybucja to głównie kwestia rejestrowania właściwych zdarzeń. Pod presją historia się zmienia. Uczestnicy zaczynają pytać, czy nagrody są sprawiedliwe. Budowniczowie martwią się, czy formuła nagrody zachęca do jakości, czy tylko do gier. Społeczności pytają, czy model jest naprawdę zrozumiały, czy tylko możliwy do prześledzenia w wąskim sensie. Własna ramka OpenLedger uznaje te napięcia, wiążąc zrozumiałość, pochodzenie i rekompensatę razem. To ma sens, ale oznacza również, że protokół bierze na siebie wiele odpowiedzialności, której żaden rejestr nie może w pełni zrealizować samodzielnie. Łańcuch może rejestrować dane wejściowe. Nie może zagwarantować, że dane wejściowe były czyste, zachęty były dobrze zaprojektowane, ani że zarządzanie pozostanie uczciwe na zawsze.
Ta ograniczenie warto jasno określić, ponieważ język blockchaina często obiecuje zbyt wiele w kwestii tego, co zapisy mogą zrobić. OpenLedger może uczynić atrybucję bardziej widoczną, ale nie może zapobiec wejściu niskiej jakości danych do Datanetu. Może rejestrować pochodzenie, ale nie może zmusić każdego uczestnika do uczciwej interpretacji tego pochodzenia. Może rozdzielać nagrody, ale nie może zapewnić, że model nagrody nigdy nie zostanie wykorzystany. Innymi słowy, może zmniejszyć niektóre rodzaje nieprzejrzystości, ale nie może znosić ludzkich zachęt ani eliminować nieporozumień. Myślę, że to tam projekt staje się bardziej wiarygodny, a nie mniej. Systemy, które przyznają się do swoich ograniczeń, są zazwyczaj bliższe rzeczywistemu zachowaniu infrastruktury.
Za tym wszystkim kryje się także szersze pytanie rynkowe. OpenLedger mówi, że to nie jest łańcuch ogólnego przeznaczenia. Jest wyraźnie skoncentrowany na AI i przepływach pracy modeli, a jego materiały ekosystemowe opisują społeczność i zestaw produktów zbudowany wokół tej węższej misji. Ta specjalizacja jest przydatna, ponieważ nadaje projektowi jasne zadanie. Ale to również oznacza, że adopcja zależy od tego, czy użytkownicy rzeczywiście dbają o atrybucję, pochodzenie i przepływy płatności na tyle, by zmienić swoje zachowanie. Wielu to robi, gdy stawka jest wysoka. Wielu nie robi, gdy wygodniej jest po prostu skorzystać. To jest prawdziwy kompromis. OpenLedger może rozwiązać problem, który rynek ostatecznie doceni bardziej, ale czas jest równie ważny jak projekt.
Myślę także, że pomocne jest oddzielić ideę od wyniku. Idea jest spójna: zbudować infrastrukturę AI, gdzie wkłady danych są rejestrowane, linia modeli jest widoczna, a wartość może wracać do ludzi i grup, które dostarczyły surowy materiał. Wynik jednak będzie zależał od realizacji, adopcji i tego, czy ekonomia pozostanie stabilna, gdy system nie będzie już mały. Własna dokumentacja OpenLedger sugeruje, że chce wspierać budowanie modeli, wnioskowanie i realizację agentów, jednocześnie czyniąc podstawową gospodarkę danych bardziej przejrzystą. To ambitne, ale wciąż jest zakładem infrastrukturalnym, a zakłady infrastrukturalne zazwyczaj odnoszą sukcesy, będąc cicho użytecznymi, a nie głośno transformacyjnymi.
Moje szczere odczucie jest takie: OpenLedger nie próbuje być odpowiedzią na AI w ogóle. Próbuje uczynić jedną część stosu AI mniej nieprzejrzystą i bardziej ekonomicznie zrozumiałą. To może brzmieć wąsko, ale wąsko często tam, gdzie jest prawdziwa praca. Jeśli system może ułatwić inspekcję pochodzenia, uzasadnienie nagród i organizację współpracy, to rozwiązuję rzeczywistą awarię w obecnych rynkach AI. Jeśli nie, to i tak udokumentuje rzeczywisty problem, nawet jeśli nie rozwiąże go w pełni. To nie jest mała sprawa. W infrastrukturze zrozumienie, gdzie systemy zawodzą, jest często pierwszym użytecznym krokiem w kierunku ich poprawy.
