i was playing in the park with my homies the other night and somehow we started talking about AI infraestructure 😂 and i kept thinking about @OpenLedger the whole time because of something that happened to me months ago...
six months after i deployed a domain-specific model, a collegue asked me a simple question.
"what did you train this on exactly?"
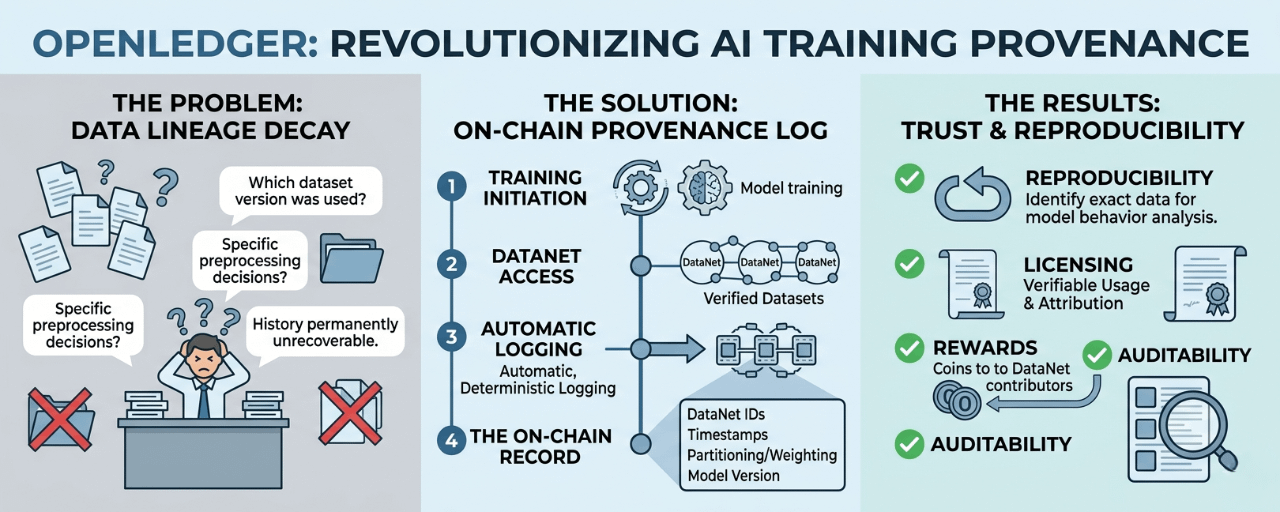
i opened my notes. found a folder name. the folder had been reorganised. the dataset version i'd used was somewhere in a chain of csv exports i couldnt fully reconstruct. the fine-tuning run had a timestamp but no provenance recrod attached to it. the model weights existed. the history of what produced them had essencialy evaporated 😂
i spent an entire afternoon trying to rebuild the data lineage from memory and partial notes. got maybe 70% of the way there. the remaining 30% specific preprocessing decisions, which version of which source, what filtering criteria had been aplied was just gone. permanantly unrecoverable.
that experience fundamentaly changed how i think about model documentation...
and its the exact problem OpenLedger's training provenance log is architected to solve from the ground up.
here's what actualy gets recorded and when. every time a model trains on DataNets in the #OpenLedger ecosystem, the training run commits a provenance recrod on-chain. not a text file in someone's repo. not a notion page that might get deleted. an on-chain record that includes the specific DataNet identifiers used, the timestamps of the training event, how the data was partitioned or weighted, and the model version produced by that run.
this record is deterministic. the same training run always produces the same provenance entry. it cannot be retroactivley edited. and its publicly queryable. any developer, auditor, or contributor can inspect which DataNets a given model version was built on.
the downstream implications of this are more intresting than they first appear...
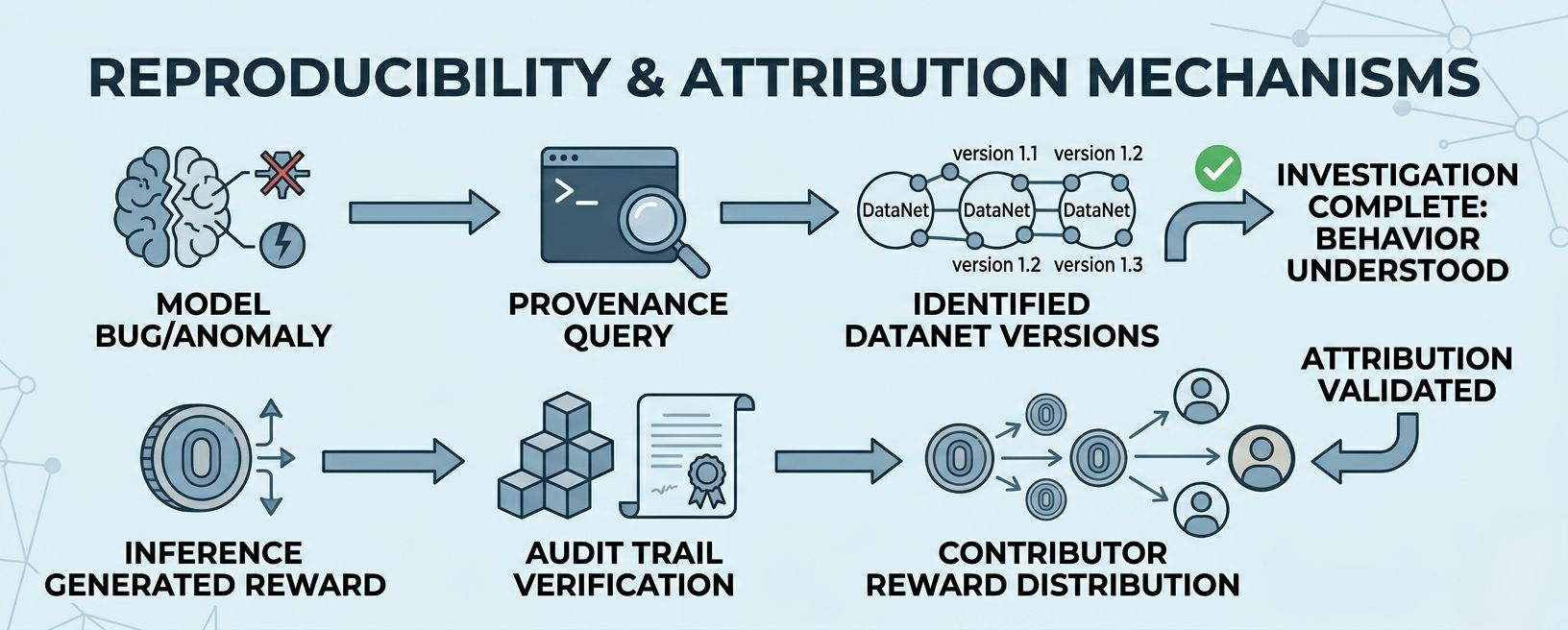
reproducibility becomes tractable. if you need to understand why a model behaves a certain way, you query its provenance record, identify the DataNets that trained it, and you have the exact dataset lineage to investigate. no reconstruction from memory. no folder archaeology.
licensing becomes enforceable. if a contributor's data carries specific usage terms domain restrictions, attribution requirements, commercial limitations the provenance log creates the audit trail that makes those terms verifyable. you can prove which model used which data. before this, that proof simply didnt exist.
and attribution rewards become trustworthy. every inference-level reward that flows back to a DataNet contributor depends on knowing with certainty that the DataNet actualy contributed to the model. the provenance log is the foundation that makes that certainty possible. without it, attribution is a claim. with it, attribution is a verifyable record.
i keep thinking about my folder-archaeology afternoon and what it would have looked like with this infrastructure...
one query. complete lineage. every DataNet, every version, every weighting decision. the collegue would have had their answer in thirty seconds instead of me spending four hours reconstructing something i should have never lost in the first place.
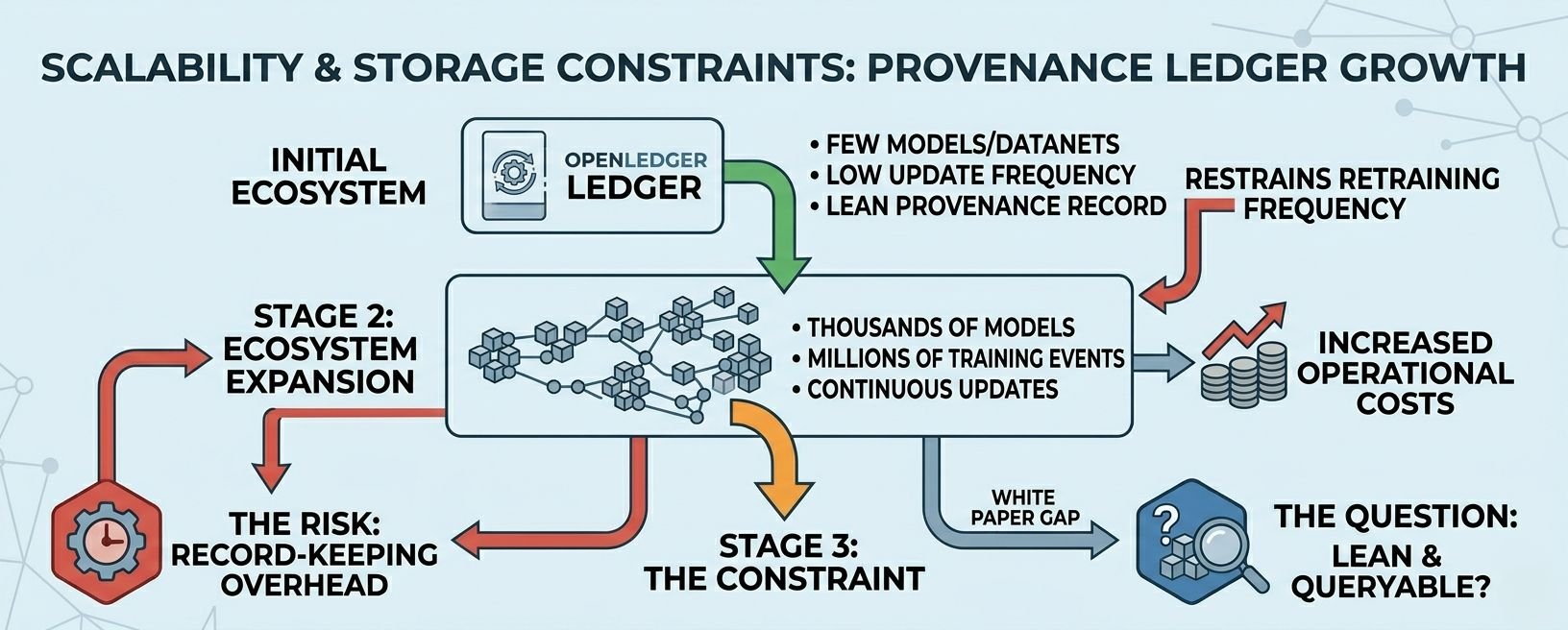
the thing i genuinly wonder about is the long-term storage question. on-chain records are permanant but storage isnt free. as the ecosystem scales thousands of models, millions of training events, continuously updating provenance records the cost and complexity of maintaining that ledger grows in ways the whitepaper doesnt fully adress...
honestly dont know if the training provenance log stays lean and queryable at ecosystem scale, or if the record-keeping overhead becomes a meaningfull constraint on how frequently models can be updated and retrained?? 🤔
