Moi drodzy obserwatorzy 💓
Więc poszedłem głębiej w @OpenLedger techniczną dokumentację. Nie z jakiegoś szczególnego powodu. Po prostu miałem otwartą kartę.
A gdzieś w okolicy trzeciego przeglądania, jak ich warstwa Proof of Attribution ma działać, coś mnie niepokoiło, czego nie mogłem się pozbyć — i nie było to to, co się spodziewałem znaleźć.
Wszyscy mówią o weryfikowalnej AI, jakby to był problem sprzętowy. Jakby wystarczyło mieć wystarczająco dużo zdecentralizowanych węzłów obliczeniowych, dodać trochę kryptograficznej walidacji, a nagle wyniki AI stają się godne zaufania. Taki jest pitch. Tak prawie każdy projekt "zdecentralizowanej AI" zaczyna.
Jest jednak trochę inaczej z OpenLedger, prawie to przeoczyłem za pierwszym razem.
Ich rzeczywisty kierunek techniczny nie dotyczy weryfikacji, że obliczenia miały miejsce. Chodzi o weryfikację, które dane wpłynęły na wynik — śledzenie wkładu przez procesy treningowe i wnioskowania do konkretnych źródeł danych, modeli i ludzkich adnotatorów, które miały wpływ na wynik. Model Dowodu Atrybucji nie jest mechanizmem konsensusu. Jest bliżej księgi pochodzenia.
I wtedy to zaskoczyło: to są całkowicie różne problemy.
Jedno to problem weryfikacji obliczeń. Drugie to problem pochodzenia danych. Większość branży buduje dla pierwszego. OpenLedger jest, przynajmniej architektonicznie, zorientowany na drugi.
Oto, co to naprawdę oznacza, jeśli działa tak, jak opisują.
Obecnie, gdy model AI produkuje coś — kawałek analizy, decyzję, klasyfikację — nie masz sposobu, aby prześledzić, które dane treningowe wpłynęły na ten wynik. Możesz audytować wagi, jeśli masz dostęp. Nie możesz audytować łańcucha wkładów. To nie jest szara strefa regulacyjna, to fundamentalna nieprzejrzystość wbudowana w to, jak modele są składane dzisiaj.
Gdybyś mógł oznaczyć wkłady podczas wprowadzania, zarejestrować, które zestawy danych i adnotatorzy wpłynęli na jakie zachowania modeli, a następnie udostępnić ten łańcuch na żądanie — miałbyś coś, co naprawdę przyda się przedsiębiorstwom, audytorom i wszystkim, którzy próbują przypisać odpowiedzialność za wyniki AI. To prawdziwy problem rynkowy, a nie tylko narracyjny.
Ale oto część, która mnie niepokoi.
Różnica między "zorientowanym architektonicznie" a "faktycznie działającym na dużą skalę" jest ogromna w tej przestrzeni. Śledzenie pochodzenia na poziomie zestawu danych jest naprawdę trudne — nie teoretycznie, ale praktycznie. W momencie, gdy wprowadzasz jakiekolwiek dostosowania, destylację lub łączenie modeli, łańcuchy atrybucji szybko stają się niejasne. Każdy, kto pracował blisko pipeline'ów ML, wie, jak szybko pochodzenie danych staje się folklorem zamiast zapisem.
Nie mówię, że OpenLedger nie może tego rozwiązać. Mówię, że nie widziałem dowodów, że ktokolwiek rozwiązał to w sposób czysty na poziomie produkcyjnym, na łańcuchu lub poza nim. Badania istnieją. Wdrożenia to głównie dema.
A warstwa nagród dla wkładów, która znajduje się na szczycie tego — gdzie dostawcy danych i adnotatorzy teoretycznie są wynagradzani na podstawie zweryfikowanej atrybucji — ten cały mechanizm jest nośny. Jeśli śledzenie atrybucji ma luki, struktura zachęt dziedziczy te luki. Nie dostajesz tylko nieprecyzyjnego pochodzenia. Otrzymujesz system nagród, który jest systematycznie stronniczy wobec każdego, kto potrafi oszukiwać w logach atrybucji.
To inny rodzaj problemu niż "jeszcze nie skalowaliśmy".
Początkowo myślałem też — że to w zasadzie to samo, co robi kilka innych zdecentralizowanych projektów AI z dowodami zerowej wiedzy dla wnioskowania modeli. Ale w rzeczywistości, nie. Dowody wnioskowania ZK weryfikują, że konkretna obliczenia przebiegły poprawnie, biorąc pod uwagę stały model. Śledzenie atrybucji zadaje inne pytanie: biorąc pod uwagę ten wynik, co przyczyniło się do modelu, który go wyprodukował? Odwrócone pochodzenie versus weryfikacja do przodu. Łatwo to pomylić, naprawdę różne.
Ta różnica ma ogromne znaczenie dla tego, jak faktycznie użyjesz tego w praktyce.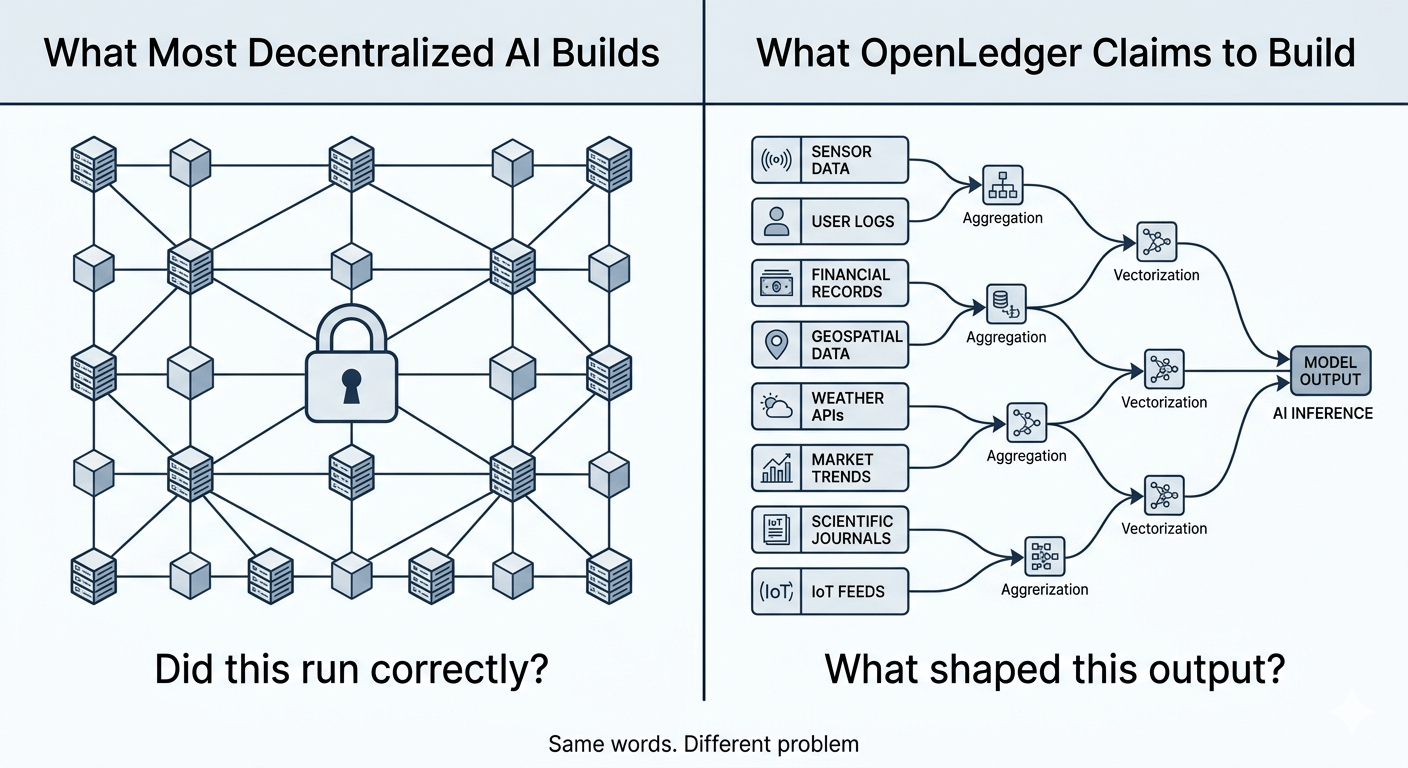
Tak czy inaczej. Wciąż obserwuję, jak rozkład odblokowania wpłynie na rynek w najbliższych miesiącach — to prawdopodobnie powie więcej o sentymencie rynku na ten temat niż jakakolwiek dokumentacja techniczna.
Atrybucja to prawdziwy problem, który warto rozwiązać. Czy ta architektura go rozwiązuje, czy po prostu przekonująco opisuje jego rozwiązanie, naprawdę nie wiem jeszcze.
Prawdopodobnie po prostu będę dalej obserwować.