Wszedłem na OpenLedger $OPEN myśląc, że będzie to bezproblemowe. Nie jest.
W momencie, gdy faktycznie to wykorzystujesz, tarcie pojawia się szybko.
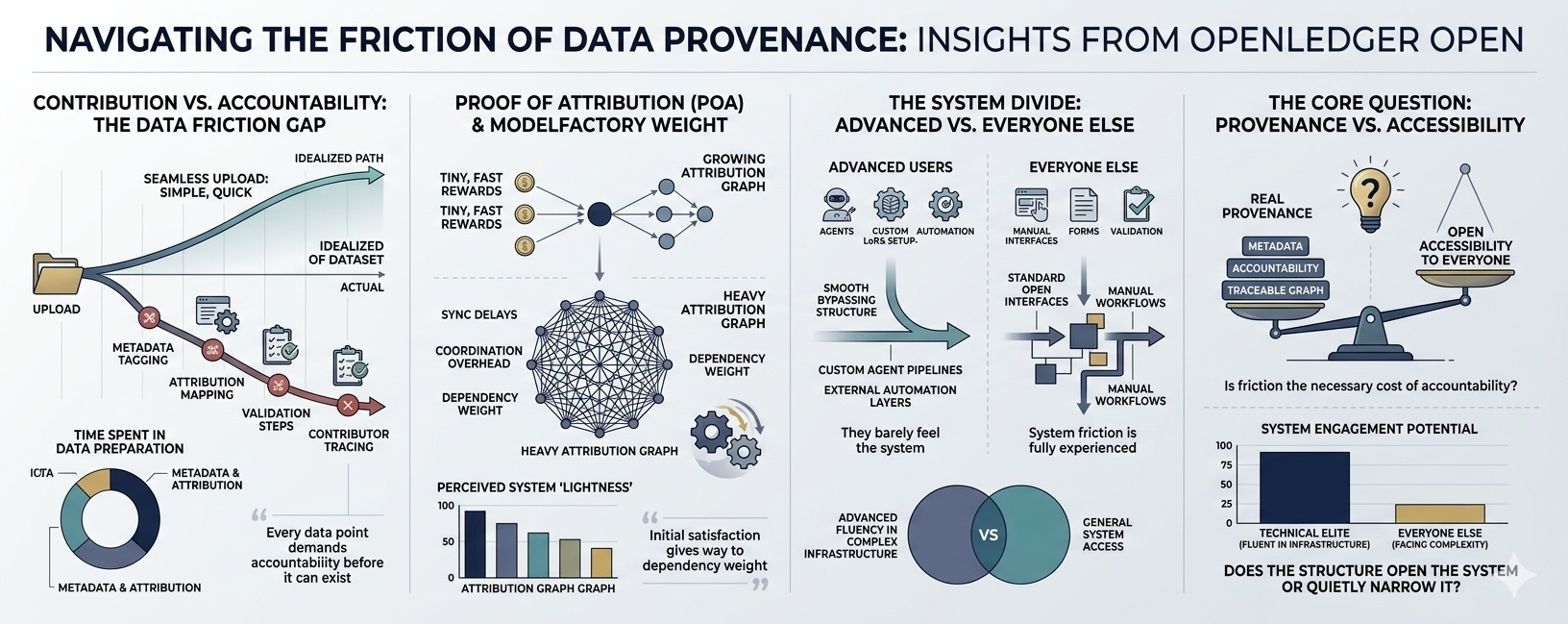
Przesyłanie prostych niszowych zestawów danych do Datanet to nie tylko wrzucenie i jazda. To zamienia się w tagowanie metadanych, mapowanie atrybucji, kroki walidacji, śledzenie uczestników. Każdy kawałek danych zaczyna wydawać się, że potrzebuje papierkowej roboty, zanim będzie mógł istnieć w systemie.
Przestaje to być wkład, a zaczyna być odpowiedzialnością.
Na początku system Proof of Attribution wydaje się być zwycięstwem. Malutkie nagrody przychodzą szybko, a naprawdę satysfakcjonujące jest widzieć, jak twoja praca jest doceniana, zamiast być cicho zeskrobywana jak większość internetu.
Ale to uczucie nie trwa długo.
Gdy graf atrybucji rośnie, zaczyna wydawać się ciężki. W ModelFactory pomysł plug and play AI powoli przekształca się w opóźnienia synchronizacji, obciążenie koordynacją i wagę zależności, którą można naprawdę poczuć podczas pracy.
Nic nie jest zepsute. Po prostu nie jest lekkie.
Co naprawdę wyróżnia się to podział w tym, jak ludzie to odczuwają.
Zaawansowani użytkownicy poruszają się przez to prawie nietknięci, korzystając z niestandardowych pipeline'ów agenta, konfiguracji OpenLoRA i zewnętrznych warstw automatyzacji. Nie odczuwają systemu w ten sam sposób.
Wszyscy inni to robią.
I tam leży prawdziwe pytanie.
Może ta tarcie to koszt prawdziwego pochodzenia. Może systemy AI nie mogą być jednocześnie niewidoczne i odpowiedzialne.
Ale jeśli udział w AI wymaga takiej struktury i technicznego obciążenia, żeby w ogóle uczestniczyć…
czy naprawdę otwiera system dla każdego
lub cicho zawęzić to do tych samych osób, które już są biegłe w złożonej infrastrukturze.
