Rynek dzisiaj wydawał się trochę na bocznej fali. Nie ten straszny rodzaj płaskiego — po prostu taki, gdzie nic się nie rusza i kończysz klikając w rzeczy, którymi normalnie byś się nie przejmował.
Tak właśnie trafiłem głębiej w OpenLedger — $OPEN . Nic nieplanowanego. Ktoś rzucił to w grupowym czacie z czymś niejasnym jak "blockchain spotyka dane do treningu AI" i nie mogłem zrozumieć, co to w ogóle znaczy. Więc poszedłem to sprawdzić.
Pierwsze założenie: standardowy pitch. Zdecentralizować AI, dać użytkownikom kontrolę nad swoimi danymi, otworzyć wszystko na open-source. Słyszałem to już setki razy. Prawie zamknąłem zakładkę.
Ale potem coś zaczęło się inaczej układać.
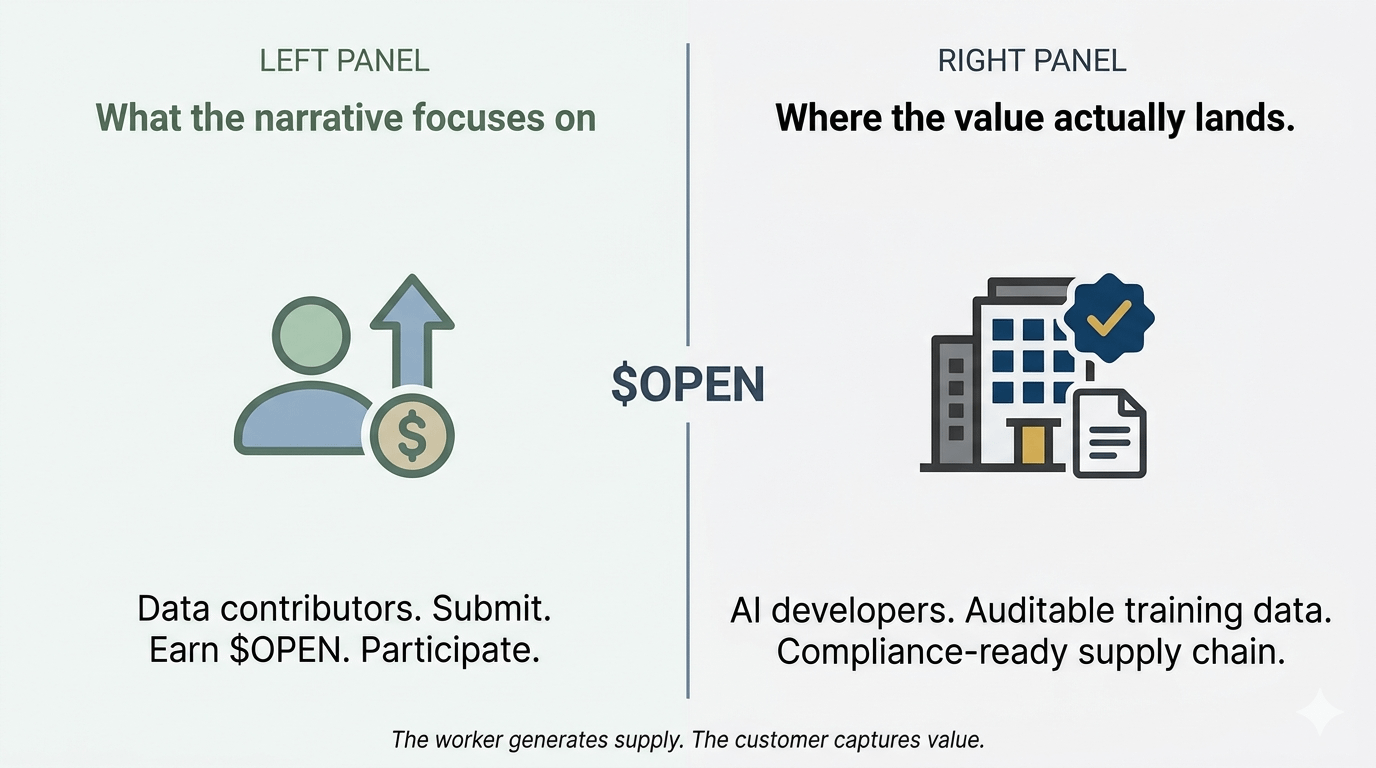
Wszyscy mówią o OpenLedger jako o zwycięstwie dla dostawców danych. Zwykli ludzie przesyłają dane, zarabiają tokeny, uczestniczą w budowaniu AI. I ta część jest technicznie dokładna. Ale to nie jest najciekawsza część.
Oto, co naprawdę zaskoczyło.
Największym problemem w rozwoju AI obecnie nie jest moc obliczeniowa. To nie rozmiar modelu. To to, że dane treningowe nie mają ścieżki dokumentacyjnej. Firmy AI budują systemy na danych, których nie mogą w pełni zweryfikować — kto je zebrał, kiedy, w jakich warunkach, czy były zmieniane po drodze. To cicha kryzys, którego branża stara się ignorować, bo przyznanie się do tego stwarza odpowiedzialność.
OpenLedger umieszcza pochodzenie na łańcuchu. Każde przesłanie danych niesie ze sobą niezmienny, opatrzony datą, przypisany rekord.
I oto rzecz — to nie jest przede wszystkim wartościowe dla osoby przesyłającej dane. To przede wszystkim wartościowe dla programisty AI po drugiej stronie, który musi powiedzieć klientowi korporacyjnemu, regulatorowi lub audytorowi: ten model był trenowany na danych, które można zweryfikować i śledzić.
Więc narracja mówi "wzmocnij dostawców". Rzeczywisty mechanizm to "dostarczenie firmom AI zgodnego łańcucha dostaw danych."
To nie to samo.
Dostawca to pracownik. Programista AI to klient. Ekonomia tokenów tworzy podaż. Ale wartość jest przechwytywana po stronie popytu.
Myślałem, że to subtelna różnica. Potem zdałem sobie sprawę — nie, to całkowicie zmienia, jak czytasz projekt.
Ale oto część, która mnie niepokoi.
Pochodzenie danych na łańcuchu ma sens tylko wtedy, gdy przyjęcie jest uczciwe. Blockchain potwierdza, że transakcja miała miejsce. Nie potwierdza jakości ani legalności tego, co zostało przesłane. Możesz umieścić śmieciowe dane na łańcuchu i odejść z idealnie czystym rekordem pochodzenia.
Więc "zweryfikowany przez blockchain" może stać się po prostu odznaczeniem, które nie ma większego znaczenia. Firma AI mogłaby reklamować model jako wytrenowany na "danych zweryfikowanych przez OpenLedger", a to wyrażenie mogłoby stać się teatralnym spełnieniem wymogów zamiast rzeczywistej gwarancji jakości.
Nie jestem przekonany, że warstwa weryfikacji jest tak mocna, jak sugeruje pozycjonowanie. Jeszcze nie. Może staking, systemy reputacyjne, kuracja społeczności zlikwidują tę lukę — te rzeczy rzekomo są w planie rozwoju. Ale punkty w planie i działająca infrastruktura to dwie różne sprawy, a teraz problem jakości wydaje się bardziej przypuszczany niż rozwiązany.
Ta część wciąż nie jest dla mnie w porządku.
Odstaw to na chwilę.
Regulacje dotyczące AI poruszają się szybciej, niż większość ludzi dostrzega. Ustawa o AI w UE. Zasady sektorowe dotyczące medycznego AI, prawnego AI, finansowego AI. Wszystkie zaczynają zadawać to samo pytanie: skąd pochodzą dane treningowe i czy możesz to udowodnić? To już nie jest hipotetyczne pytanie. To rzeczywisty wymóg zgodności, który się kształtuje.
Jeśli ta presja osiągnie skalę w ciągu najbliższych kilku lat — co wydaje się bardziej prawdopodobne niż nie — audytowalne pochodzenie danych treningowych zmienia się z "miłej cechy" na "nie możesz wdrożyć bez tego." A firmy, które zbudowały infrastrukturę przed wymogiem, są w zupełnie innej pozycji niż te, które się z tym spieszą.
To jest scenariusz, w którym $OPEN matters. Nie dlatego, że adopcja kryptowalut się rozszerzyła. Ale dlatego, że rozwój AI napotyka ścianę zgodności i nagle potrzebuje dokładnie tego, co ten protokół cicho budował.
Czy ten harmonogram się utrzyma… szczerze mówiąc, nie jestem pewien. Wiele musi pójść dobrze. Luka weryfikacyjna jakości musi się naprawdę zamknąć. Klienci korporacyjni AI muszą wybierać pochodzenie blockchainowe zamiast budować własne systemy audytu wewnętrznego. A zegar regulacyjny musi działać wystarczająco szybko, żeby nie było łatwiejszej alternatywy.
To są realne zmienne. Wciąż myślę, które z nich naprawdę się liczą.
Tak czy inaczej. Rynek wciąż płaski. Prawdopodobnie po prostu będę obserwować, jak to się rozwija przez chwilę.
@OpenLedger #OpenLedger