Szczera myśl... kiedy Steve Jobs ogłosił iPhone'a w 2007 roku, wielu ludzi pytało "kto tego potrzebuje, Nokia działa świetnie." To pytanie nie było błędne. Po prostu zajęło kilka lat, aby zrozumieć odpowiedź. Kiedy po raz pierwszy zobaczyłem OpenLedger, to pytanie znów wróciło do mnie, a tym razem celowo odmówiłem szybkiej odpowiedzi.🤔
Więc pozwól, że przemyślę to dokładnie.
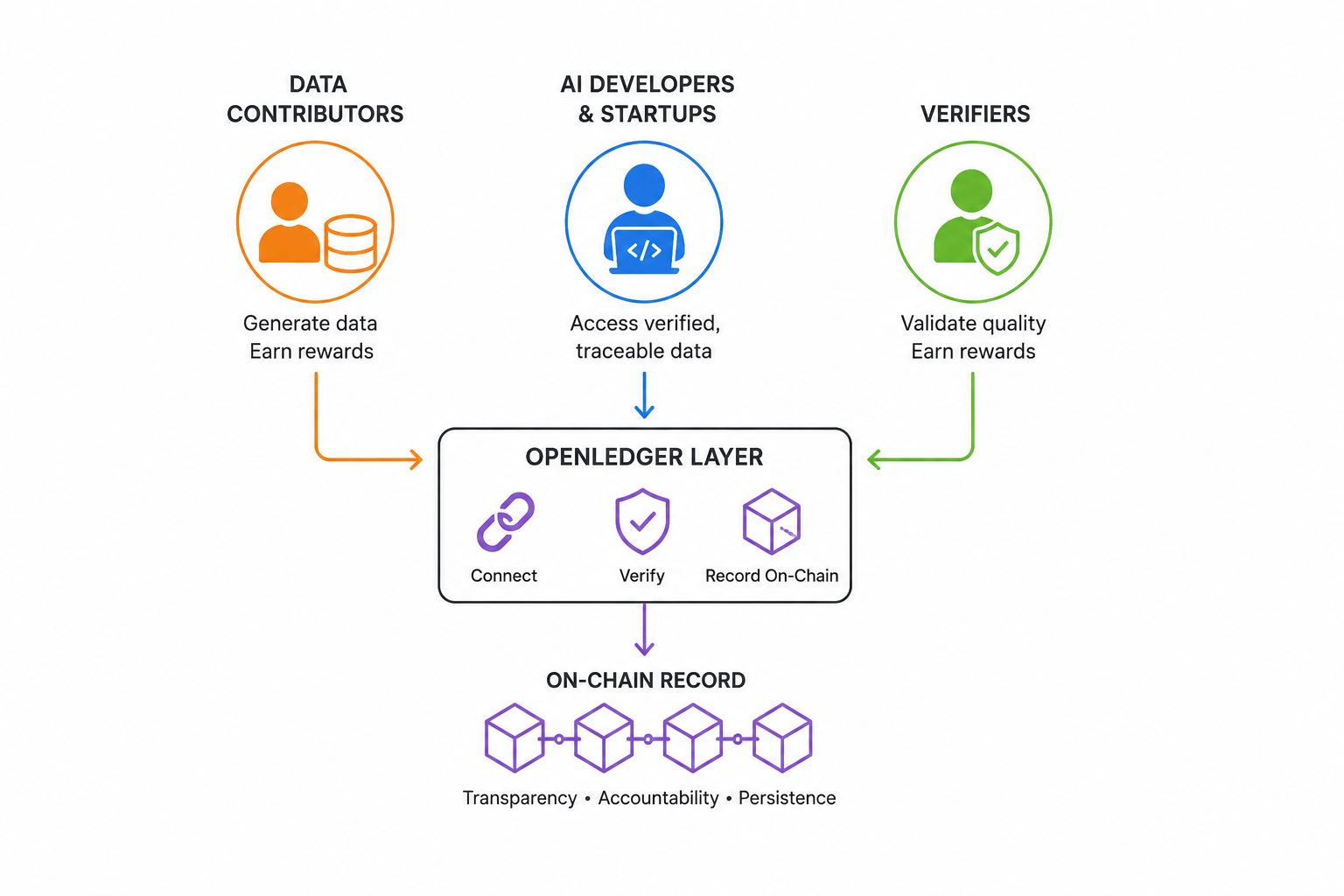
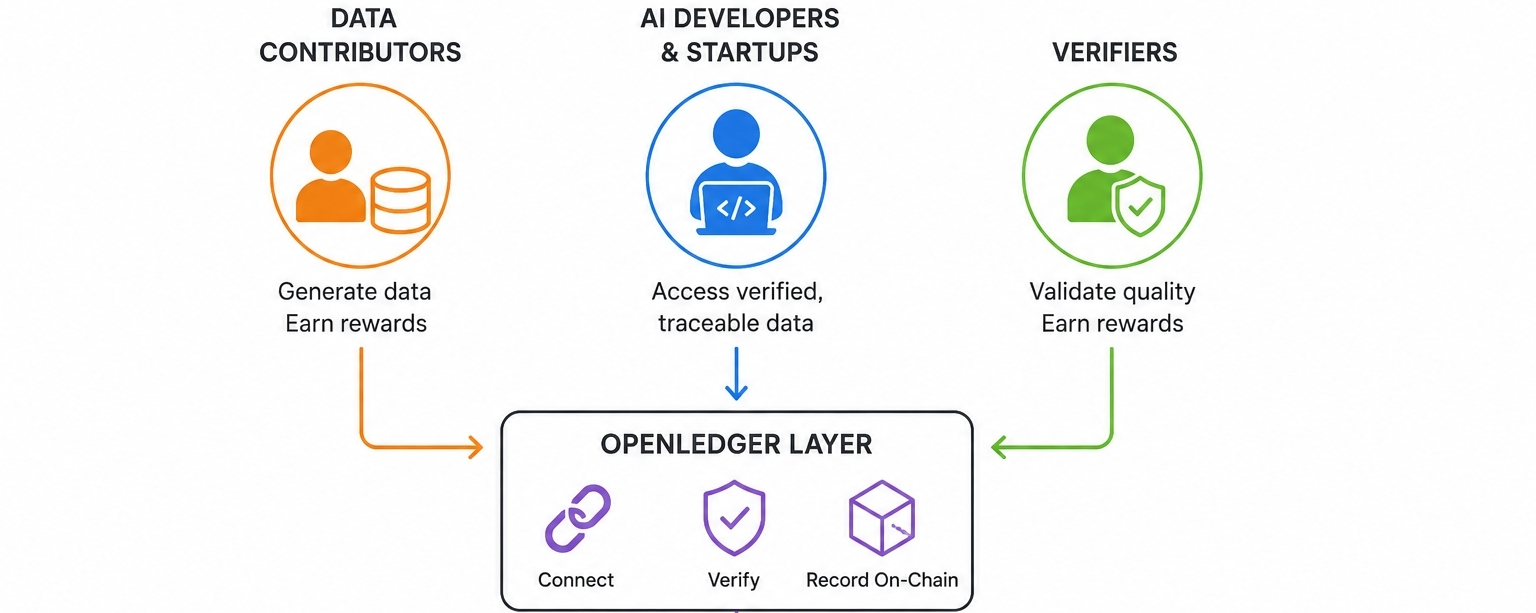
Problem, na który odpowiada OpenLedger, jest rzeczywisty i to ma znaczenie. Teraz... pipeline'y treningowe AI konsumują ogromne ilości danych, ale prawie nikt nie mówi o tym, skąd te dane tak naprawdę pochodzą. Kto je dostarczył, jak zostały zweryfikowane i czy dostawca otrzymał coś w zamian, to pytania, na które zwykle nie ma odpowiedzi... Ta cisza nie jest przypadkowa. To strukturalna luka, z której korzystają zcentralizowane systemy, utrzymując ciszę. OpenLedger pozycjonuje się bezpośrednio w tej luce, co jest albo odważne, albo ambitne, w zależności od tego, jak na to spojrzysz.
Oto, co uważam za naprawdę interesujące w tej architekturze. OpenLedger nie próbuje tylko stworzyć rynku. Stara się połączyć trzy odrębne grupy, które obecnie nie mają wspólnej infrastruktury: deweloperów, którzy potrzebują czystych i weryfikowalnych danych, dostawców, którzy produkują te dane bez wynagrodzenia, oraz weryfikatorów, którzy mogą potwierdzić jakość. Element zapisu on-chain sprawia, że to różni się od standardowej wymiany danych. Zapis on-chain nie oznacza tylko przejrzystości. Oznacza odpowiedzialność, która trwa. To istotna różnica.
Teraz szczera część.
Dla twórców AI i startupów propozycja wartości jest najjaśniejsza. Dostęp do zweryfikowanych, śledzonych danych bez polegania na jednym scentralizowanym dostawcy to coś, czego wiele zespołów naprawdę pragnie. Pytanie brzmi, czy ekosystem OpenLedger osiągnie skalę, w której to stanie się praktyczne.
Dla codziennych dostawców danych teoria jest przekonująca, a rzeczywistość trudniejsza. Pomysł, że ktoś generujący przydatne dane powinien otrzymać część ich wartości, jest filozoficznie uzasadniony. Ale przyjęcie wśród użytkowników niebędących natywnymi w krypto wymaga zmniejszenia tarcia, z którym większość protokołów infrastrukturalnych wciąż ma problemy.😤
Dla $OPEN jako rozważania inwestycyjnego, teza wartości tokena zależy od tego, czy ta warstwa jest faktycznie wykorzystywana w znaczącej objętości. To nie jest krytyka; to po prostu szczera sekwencja tego, jak tokeny infrastrukturalne czerpią wartość.
A sceptycyzm, którego nie mogę zignorować: warstwy infrastruktury obiecujące decentralizację pojawiły się w różnych cyklach krypto. Kilka z nich miało solidne whitepapery i realne problemy do rozwiązania. Przyjęcie pozostało niskie, ponieważ dopasowanie zachęt rozpadło się gdzieś pomiędzy teorią a praktyką. OpenLedger stanie przed tym samym testem. Pytanie o zarządzanie również pozostaje nierozwiązane w mojej głowie. Zdecentralizowana w architekturze nie oznacza automatycznie zdecentralizowanej w praktyce, a to, kto faktycznie kontroluje decyzje na poziomie protokołu w czasie, jest warte obserwacji.
Wracając do odniesienia do Steve'a Jobsa, ponieważ zasługuje na swoje miejsce tutaj. Problem iPhone'a był realny, zanim istniało rozwiązanie. Ludzie po prostu nie mogli jeszcze dostrzec pełnego kształtu problemu. Problem pochodzenia danych w treningu AI jest dzisiaj realny, widoczny dzisiaj i rosnący. Czy OpenLedger stanie się rozwiązaniem, czy tylko wczesną próbą, która informuje o czymś lepszym później, szczerze mówiąc, nie mogę powiedzieć. Ale mogę powiedzieć, że problem, który rozwiązuje, nie zniknie. To przynajmniej utrzymuje moją uwagę na $OPEN.
Uwaga: NFA ~ DYOR...