there's a specific kind of dem0tivasion that sets in when you contribute something and hear nothing back.
not rejection. not criticism. just silence.
i went through this for nearly two years contributng to a few open-source ML datasets. labeling work, curation decisions, domain-specific annotations that took real expertise and real time .i believed the contributions wEre valuable.but i had absolutley no mechanism to verify that belief.no signal that my labels were being used.no feedback that my curation choices had influenced anything downstream.no reputation that accumulated from the work 😂
i eventually stopped. not because the work stopped mattering. becAuse the invisibilty became unsustainable.
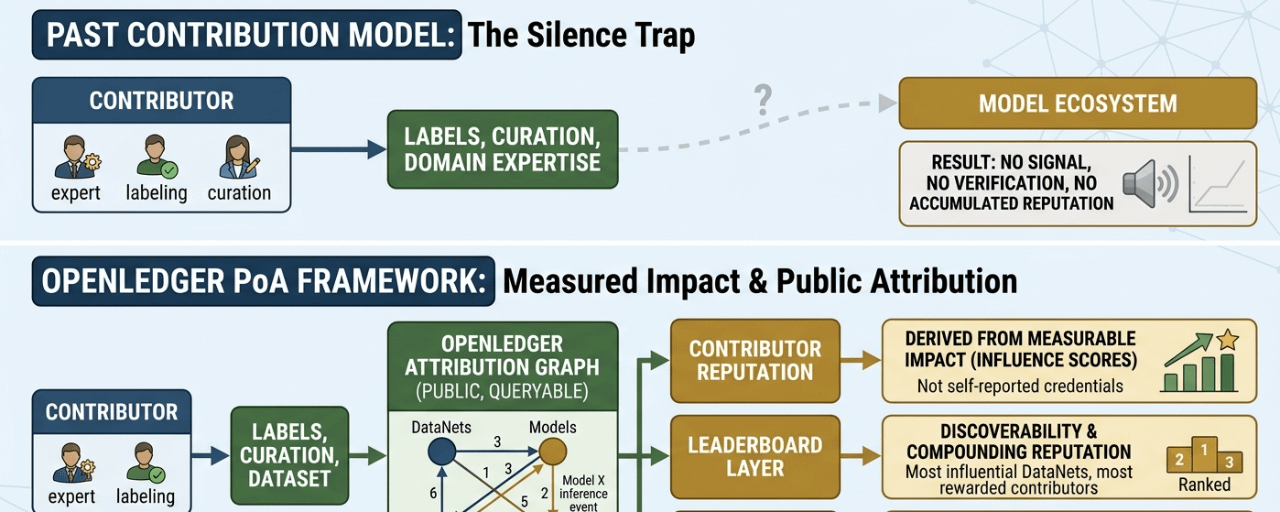
the attribution graph in OpenLedger's PoA framework is the direct answer to that exact experience...
Section 8.4 of the whitepaper describes a public attribution graph where all influence weights,model-data relations, and inference events are stored and queryable in real time. every connection between a DataNet and a model,every influence score from every inference, every reward flOw -all of it structured as a traversable graph that anyone can inspect.
what this actualy enables is something most data ecosystems have never had. contributor reputation that is derived from measurable Impact rather than self-reported credentials...
think about what that means concretely.two contributors submit data to the same DataNet. one submits 500 high-quality domain-specific records. the other submits 2000 generic records with low influence scores.the attribution graph shows exactly which contributor's data consistently scored higher influence weights across mUltiple model inferences. reputation emerges from the data itself.not from follower counts, not from credentials, not from how loudly someone advocated for their own contribution.
the leaderboard layer makes this even more intersting...
leaderboards rank the most influential DataNets per model family. most used adapters. most rewarded contributors per domain. this isnt just a transparency feature. its a discoverabilty mechanism. if your DataNet consistently topstheleaderboard for a particular model family, other model developers find you.other contributors want to add to y0ur DataNet. the reputation compounds into network effects.
and dataset saturation analytics are perhaps The most underrated piece of this whole system...
the graph can identify which spans of training data are being triggered repeatedly- which DataNets are overrepresented in attribution events. this tells model developers where the training corpus is becOming redundant and where there are genuine data gaps. underutilised niches show up as areas with low attribution density. that's a signal for where new DataNet contributions would have disproportionately high impact.
i keep thinking about my two years of silent open-source work and how diferently i would have engaged with that systEm if i'd had this infrastructure...
every label i applied would have had a traceable influence score. i would have known within weeks whether my contribution style was producing high-attribution data or low-attribution noise.
i could have adjusted.
improved.
built a reputation that was verifyable rather than just asserted
the thing i cant fully resolve is the gaming question. public leaderboards with real economic stakes are magnets for manipulation. if atribution scores determine leaderboard position and leaderboard position drives discoverability and discovrability drives staking and staking drives future influence - the whole l0op can be gamed by anyone who figures out how to inflate scores strategicaly...
honestly dont know if the attribution graph becomes the transparency layer that makes genuine contributor reputation poSsible, or if the public leaderboard dynamics produce the same influencer-capture problems that plague every other reputation system with real money attached to it?? 🤔
