Rynek dzisiaj był dziwnie płaski. Nie w tym złym sensie — po prostu... czekał. Miałem otwartą kartę z wykresami, na które tak naprawdę nie zwracałem uwagi, a jakoś wylądowałem głęboko w dokumentacji OpenLedger. Nie planowałem tego. Właściwie próbowałem znaleźć coś innego.
Zacząłem czytać o tym, jak $OPEN radzi sobie z atrybucją danych i gdzieś w okolicach trzeciej strony coś zmieniło się w moim myśleniu na ten temat.
Oto rzecz, do której ciągle wracam: źle podchodzimy do problemu danych AI. Rozmowa zawsze kręci się wokół dostępu — kto ma dane, kto może je wykorzystać, kto jest zablokowany. Ale OpenLedger, @OpenLedger , #OpenLedger , cicho wskazuje na inny problem. Nie dostęp. Pochodzenie.
Większość ludzi, którzy obecnie przyczyniają się do systemów AI, nie ma pojęcia, że ich wkład w ogóle miał miejsce. Zbiór danych zostaje zeskrobany, pakowany, sprzedawany, trenowany — a osoba, która pierwotnie stworzyła tę treść, dostaje dokładnie nic. Nie tylko żadnych pieniędzy. Brak zapisu. Brak śladu. To nie jest tak, że system jest niesprawiedliwy. To tak, że system nie ma pamięci.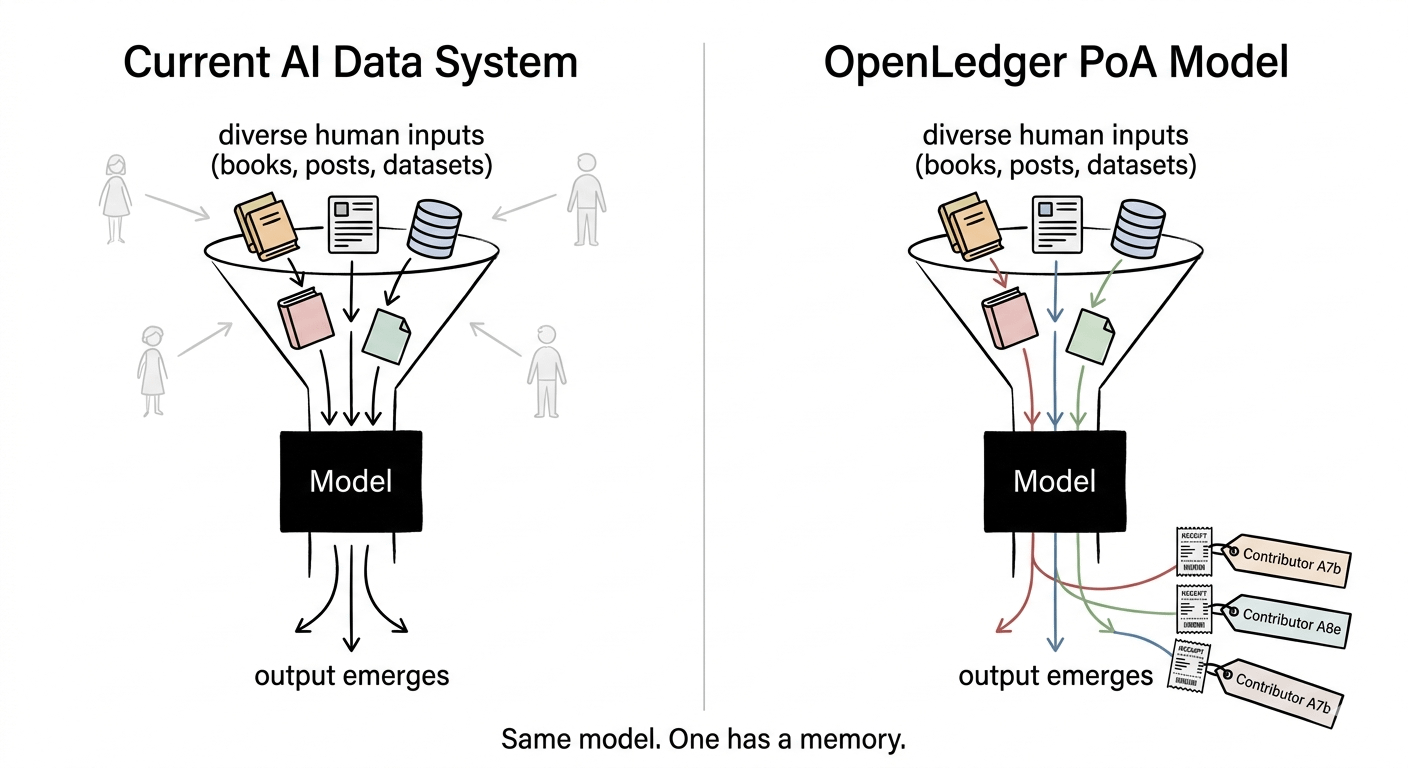
To, co OpenLedger faktycznie buduje — i to jest moment, który mi się ułożył — jest mniej jak rynek, a bardziej jak księga pracy poznawczej. Każdy zbiór danych, każdy krok treningu modelu, śledzony na łańcuchu poprzez to, co nazywają Dowodem Atrybucji. Idea jest taka: jeśli wyniki AI można prześledzić do danych wejściowych, które je ukształtowały, to wynagrodzenie może podążać za tym śladem automatycznie.
Myślałem, że to po prostu ładniejszy sposób na licencjonowanie danych. Ale to jest w rzeczywistości dziwniejsze i bardziej interesujące niż to. Jednostką wartości nie jest sam zbiór danych. To wpływ, jaki dane miały na wynik modelu. To fundamentalnie inny system księgowy niż cokolwiek, co używaliśmy wcześniej.
Ale oto część, która mnie niepokoi.
Wpływ jest naprawdę trudny do zmierzenia. Biała księga PoA opisuje dwa podejścia — przybliżenia funkcji wpływu dla mniejszych modeli oraz atrybucję tokenów opartą na tablicach suffixowych dla LLM. Przeczytałem ten akapit trzy razy. Metodologia jest realna, matematyka istnieje, ale w skali? Wśród miliardów tokenów treningowych? Atrybucja, która część danych wpłynęła na który wynik, zaczyna wydawać się mniej księgowością, a bardziej archeologią.
I nie jestem całkowicie przekonany, że to wytrzyma presję. Kiedy model produkuje coś wartościowego, czyste prześledzenie tego do dostawcy danych zakłada rodzaj czystej przyczynowości, która może nie istnieć. Trening jest chaotyczny. Wpływ się rozmywa. Dwaj współtwórcy mogą dostarczyć niemal identyczne dane — kto dostaje kredyt za atrybucję? Jak to podzielić? Biała księga dotyka tego, ale nie rozwiązują tego w pełni.
Co oznacza, że system, który ma w końcu wynagradzać ludzkich pracowników wiedzy, może skończyć nagradzając tych, którzy dostarczyli dane najłatwiejsze do atrybucji, a nie najbardziej wartościowe. To subtelna, ale ważna różnica.
Obecnie najaktywniejszą warstwą zaangażowania w ekosystemie OpenLedger jest Yapper Arena — pula nagród w wysokości 2 milionów tokenów OPEN dla najlepszych 200 społecznych współtwórców na liście liderów Kaito. To nie jest krytyka, budowanie społeczności przed dojrzałością infrastruktury to po prostu sposób, w jaki to działa. Ale oznacza to, że ludzie, którzy obecnie zarabiają $OPEN , to głównie osoby mówiące o OpenLedger, a nie dostarczające mu danych.
Aktualne datanety, ModelFactory, system atrybucji — to jest długoterminowa gra. Pytanie brzmi, czy społeczność, która teraz się buduje, to ta, która stawi czoła trudniejszej, mniej błyszczącej pracy polegającej na faktycznym dostarczaniu wysokiej jakości danych treningowych, gdy infrastruktura będzie gotowa.
Ta luka — między tymi, którzy są nagradzani jako pierwsi, a tymi, dla których system teoretycznie został zbudowany — to rzecz, nad którą ciągle się zastanawiam.
Bo jeśli Dowód Atrybucji działa, to jest to naprawdę jedna z bardziej interesujących zmian strukturalnych w sposobie, w jaki buduje się AI. Model przestaje być czarną skrzynką, która cicho konsumuje ludzką wiedzę, i staje się czymś, co nosi paragon. Każdy wynik z możliwym do prześledzenia pochodzeniem. Każdy współtwórca z weryfikowalnym roszczeniem.
To nie jest mały pomysł. To całkowicie inny związek między ludzką wiedzą a wyjściem maszyny.
Prawdopodobnie po prostu będę obserwować, jak rozwija się aktywność datanetów przez następne kilka miesięcy. Zobaczyć, czy ślady atrybucji na łańcuchu zaczną pokazywać prawdziwą głębokość, czy pozostaną głównie na warstwie społecznej. Zespół i odblokowania inwestorów nie nastąpią do września, więc jest czas na rozwój.
Rynek wciąż wygląda, jakby decydował o czymś. Nie jestem pewien, o co jeszcze.