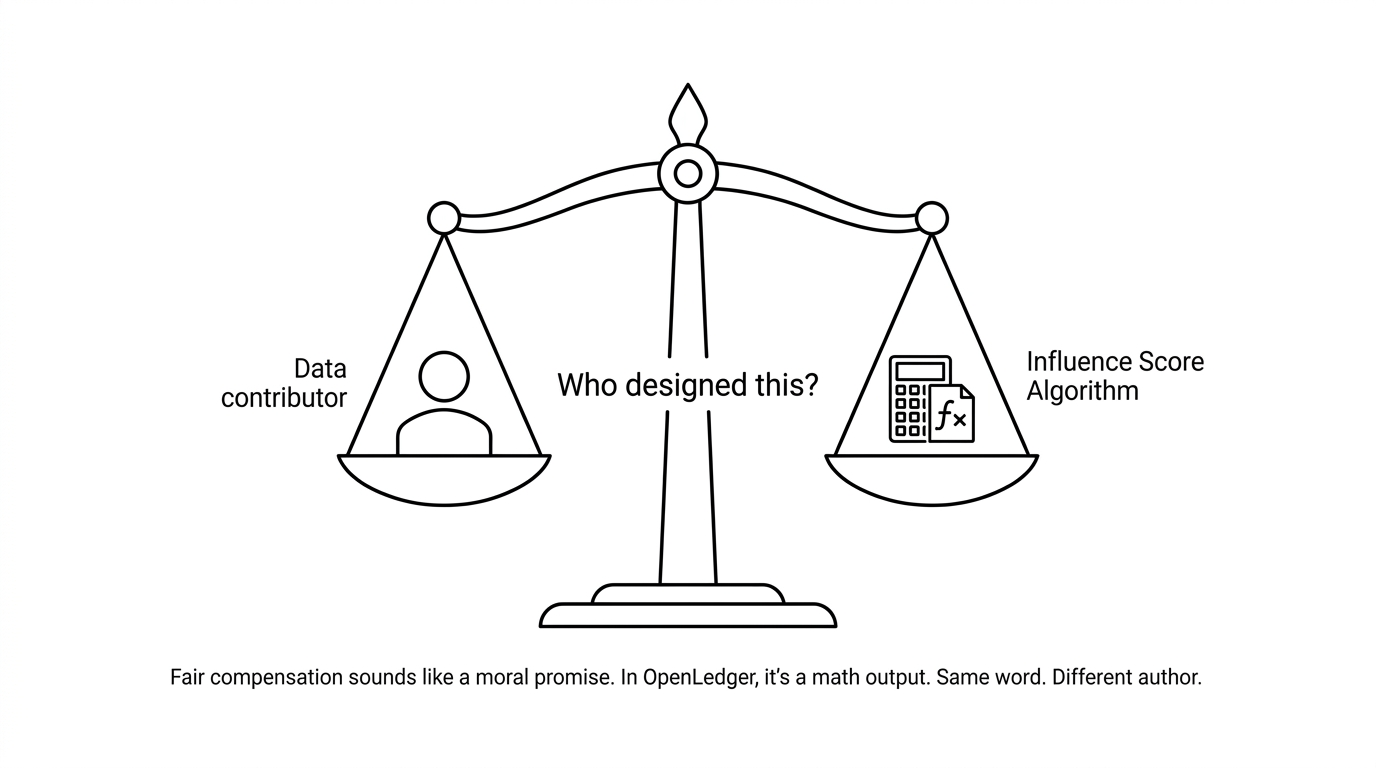
Mam teraz dość wyraźny obraz. Kluczowy wniosek: wszyscy postrzegają roszczenie OpenLedger do uczciwości jako argument moralny — uczestnicy zasługują na wynagrodzenie. Ale niewygodna prawda jest taka, że "uczciwość" w systemie Proof of Attribution nie jest osądem wartościującym. To matematyczny wynik. Algorytm decyduje, co jest uczciwe. A kto zaprojektował funkcję obliczania wpływu, ten w efekcie definiuje uczciwość dla całej gospodarki. To moc projektowa, której większość ludzi nie zauważa.
Późne popołudnie, tak między sprawami. Rynki już wcześniej zrobiły ruch, a ja ich nie goniłem. Miałem otwartą kartę przeglądarki z notatkami na temat OpenLedger #OpenLedger , które miałem na celu zamknąć od kilku dni.
Zacząłem naprawdę czytać zamiast przeglądać, i coś mnie złapało.
Każdy, kto zajmuje się $OPEN i @OpenLedger używa słowa 'sprawiedliwość.' Sprawiedliwe zachęty. Sprawiedliwe wynagrodzenie. Współtwórcy w końcu dostają swoją sprawiedliwą część. To cała moralna narracja i przez jakiś czas przyjąłem to za pewnik. Ale ciągle przyglądałem się rzeczywistemu mechanizmowi i zacząłem czuć się nieco nieswojo w sposób, którego nie mogłem od razu nazwać.
Zrozumiałem.
W systemie OpenLedger, 'sprawiedliwość' nie jest oceną wartości. To wynik obliczeń. Protokół Proof of Attribution oblicza wynik wpływu – matematycznie określa, jak dużo konkretne dane kształtują konkretny wynik modelu – a ten wynik staje się podstawą wypłaty. System nie pyta, czy nagroda wydaje się sprawiedliwa. Działa na podstawie przybliżeń gradientowych i dopasowania tokenów w tablicach suffix i produkuje liczbę. Ta liczba to sprawiedliwość, według definicji, w tej gospodarce.
Co oznacza, że ten, kto zaprojektował funkcję wpływu, cicho definiuje, co oznacza 'sprawiedliwość' dla wszystkich uczestników.
Myślałem, że twierdzenie o sprawiedliwości dotyczy zastąpienia skorumpowanego systemu uczciwym. W rzeczywistości chodzi o zastąpienie ludzkiego osądu sprawiedliwości algorytmicznym. To zupełnie inna sprawa.
To niekoniecznie jest gorsze. Algorytmy mogą być bardziej spójne i mniej podatne na korupcję niż ludzie podejmujący decyzje na własną rękę. On-chain zapis tego, jakie dane wpłynęły na jaki wynik, jest naprawdę bardziej przejrzysty niż firma decydująca w prywatności, kto dostaje wypłatę. Rozumiem, dlaczego to jest kuszące.
Ale oto część, z którą ciągle się zmagam. Metodologia obliczania wpływu jest opisana jako działająca dobrze dla małych, wyspecjalizowanych modeli, a jako 'wciąż otwarte wyzwanie badawcze' dla dużych modeli ogólnych – własna dokumentacja techniczna projektu to mówi. Co oznacza, że definicja sprawiedliwości jest obecnie węższa niż obietnica sprawiedliwości. Badacz medyczny wnoszący wkład do specjalistycznej diagnostycznej sieci danych może być sprawiedliwie wynagradzany w sposób, który matematyka faktycznie może zweryfikować. Autor, którego praca pomogła w szkoleniu ogólnego modelu językowego, nie może jeszcze.
Więc sprawiedliwy system zachęt działa najlepiej tam, gdzie istniejący ekosystem AI jest najmniejszy. Niesprawiedliwość, którą ma poprawić, leży głównie w części, do której jeszcze nie może dotrzeć.
To mnie niepokoiło odkąd to przeczytałem. Może ta luka się zacieśni, gdy technologia dojrzeje. Obliczanie wpływu na dużą skalę to aktywne badania – nie jest to problem rozwiązany, ani niemożliwy do rozwiązania. Ale 'sprawiedliwość' jako obietnica i 'sprawiedliwość' jako weryfikowalny wynik matematyczny to nie to samo, dopóki matematyka działa wszędzie tam, gdzie obietnica ma zastosowanie.
W każdym razie. Zakładka wciąż jest otwarta. Może ją zamknę, gdy dowiem się, jak naprawdę się z tym czuję.