
Kręcę się w świecie krypto na tyle długo, że moja pierwsza reakcja na prawie każdy nowy projekt AI blockchain to głównie zmęczenie. Nie złość, dokładnie. Raczej to zmęczenie, które czujesz, gdy ktoś wchodzi do pokoju, obiecując "naprawić internet" znowu, z kolejnym tokenem i roadmapą pełną niemożliwych terminów. Większość tych projektów brzmi niesamowicie w spokojnych warunkach rynkowych, ponieważ spokojne rynki wybaczają złe założenia. Płynność przepływa, użytkownicy są optymistyczni, a nikt nie testuje systemu pod presją, aż ta w końcu nadejdzie. Wtedy sprawy szybko się psują.
To częściowo dlatego OpenLedger zwrócił moją uwagę. Nie dlatego, że brzmi idealnie. Szczerze mówiąc, nie sądzę, że idealne systemy istnieją, szczególnie w kryptowalutach. To, co sprawiło, że się zatrzymałem, to fakt, że projekt wydaje się koncentrować mniej na fantazji, a bardziej na rzeczywistym problemie operacyjnym, który staje się coraz gorszy w miarę rozwoju AI. Problem jest prosty do opisania, ale niesamowicie chaotyczny, gdy pieniądze, zachęty i infrastruktura zderzają się ze sobą.
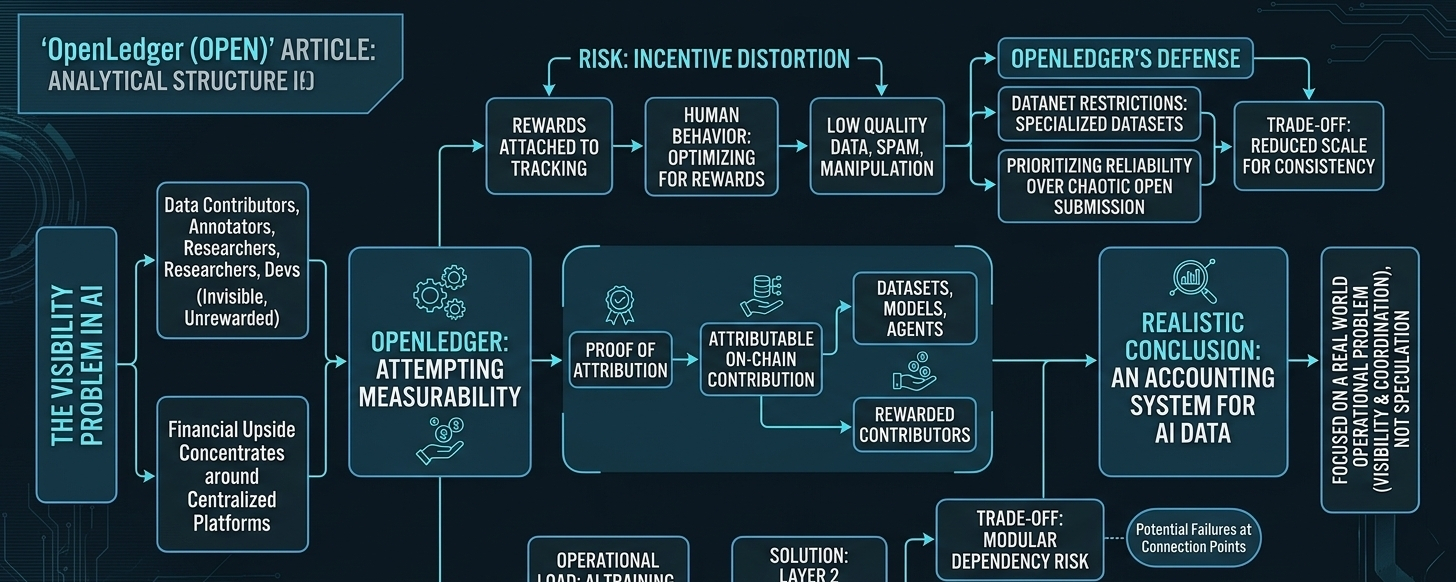
Kto tak naprawdę otrzymuje nagrody, gdy systemy AI tworzą wartość?
W tej chwili większość osób zasilających nowoczesne systemy AI jest niewidoczna. Uczestnicy danych, anotatorzy, niszowi eksperci, budowniczowie społeczności, niezależni badacze, nawet mali programiści dostosowujący modele do wyspecjalizowanych przypadków użycia... większość z nich siedzi pod powierzchnią, podczas gdy większość finansowych zysków koncentruje się wokół scentralizowanych platform lub dużych dostawców infrastruktury. Przypomina mi to, jak czasami działają miasta. Wszyscy zauważają wieżowce, aplikacje, błyszczące przestrzenie publiczne. Prawie nikt nie myśli o podziemnych rurach, trasowaniu energii elektrycznej, systemach kanalizacyjnych czy ekipach konserwacyjnych, chyba że coś się zepsuje. Ale gdy hydraulika zawiedzie, nagle cała iluzja płynnej operacji znika z dnia na dzień.
Infrastruktura AI ma podobny problem. Większość pracy w ukryciu pozostaje ukryta, dopóki zaufanie nie zostanie zachwiane.
A zaufanie ostatecznie się załamuje. Zawsze się załamuje pod wystarczającą presją.
To jest część, którą myślę, że OpenLedger stara się rozwiązać poprzez swoją architekturę blockchain skupioną na AI i system dowodów wkładu. Główna idea wydaje się opierać na tym, aby wkłady były mierzalne i możliwe do śledzenia bezpośrednio w łańcuchu, tak aby zbiory danych, modele i agenci mogli być połączeni z ludźmi, którzy naprawdę pomogli je zbudować. Teoretycznie tworzy to bardziej przejrzystą strukturę ekonomiczną, w której uczestnicy są nagradzani w zależności od tego, jak ich dane lub praca wpływają na szerszy ekosystem.
Czy to brzmi czysto na papierze? Tak, absolutnie.
Ale prawdziwe systemy nigdy nie są czyste, gdy w grę wchodzi ludzkie zachowanie.
W momencie, gdy nagrody są związane z śledzeniem wkładów, sieć musi radzić sobie z zniekształceniem zachęt. Ludzie optymalizują dla nagród, a niekoniecznie jakości. To nie jest nawet problem specyficzny dla kryptowalut. To po prostu, jak ludzie reagują na systemy. Jeśli miasto zacznie płacić mieszkańcom na podstawie raportów o ruchu drogowym, w końcu ktoś zacznie zalewać system fałszywymi raportami, ponieważ mechanizm nagród staje się celem. Sieci AI zachowują się w ten sam sposób. Gdy nagrody tokenowe pojawiają się w obrazie, niskiej jakości zbiory danych, zgłoszenia spamowe, powielone informacje, manipulowane przypisania i skoordynowane próby farmingu stają się nieuniknione.
Myślę, że OpenLedger rozumie to przynajmniej częściowo, co jest powodem, dla którego jego struktura Datanet wydaje się bardziej restrykcyjna, niż niektórzy mogą się spodziewać. System wydaje się zaprojektowany wokół wyspecjalizowanych zbiorów danych, a nie chaotycznych otwartych kanałów zgłoszeń, gdzie wszystko jest dozwolone. Szczerze mówiąc, myślę, że to ograniczenie jest prawdopodobnie konieczne. Otwarte systemy dobrze brzmią w materiałach marketingowych, ale zazwyczaj stają się operacyjnymi koszmarami później. Każda sieć w końcu musi zdecydować, czy priorytetuje skalę, czy niezawodność, ponieważ utrzymanie obu jednocześnie jest brutalnie trudne.
Można to zobaczyć wszędzie w infrastrukturze. Drogi. Lotniska. Systemy wodne. Łańcuchy dostaw. Im szerszy i bardziej elastyczny staje się system, tym trudniej utrzymać spójność pod presją. Infrastruktura AI nie jest inna. Sieć akceptująca nieograniczone niskiej jakości dane może szybko rosnąć na początku, ale w końcu koszty weryfikacji stają się przytłaczające. Ktoś wciąż musi posprzątać bałagan.
To tam warstwa przypisania OpenLedger staje się dla mnie interesująca. Nie dlatego, że gwarantuje sprawiedliwość, ale ponieważ przynajmniej próbuje uczynić przepływ wartości widocznym, zamiast ukrywać go za nieprzejrzystymi systemami korporacyjnymi, w których nikt tak naprawdę nie rozumie, jak podejmowane są decyzje. Widoczność ma większe znaczenie, niż ludzie zdają sobie sprawę. Niewidzialne systemy mają tendencję do cichego gromadzenia władzy, ponieważ użytkownicy nie mogą łatwo audytować, gdzie płyną zachęty.
Jednak przypisanie wkładu jest znacznie trudniejsze, niż czasami przyznają projekty kryptowalutowe.
Modele AI nie zachowują się jak arkusze kalkulacyjne. Wyniki wyłaniają się z warstw połączonych informacji, gdzie wpływ staje się trudny do izolowania. Jeden z uczestników może dostarczać podstawowe dane. Inny może poprawić dokładność w przypadkach brzegowych. Jeszcze inny może zoptymalizować samą architekturę modelu. Próba obliczenia dokładnej wartości wkładu w dynamicznym systemie AI jest chaotyczna i prawdopodobnie zawsze będzie chaotyczna. Rejestry blockchain mogą pomóc w dokumentowaniu aktywności, ale nie mogą magicznie usunąć niejednoznaczności z złożonych systemów.
Myślę, że ludzie nie doceniają, jak dużo niejednoznaczności istnieje w nowoczesnych środowiskach szkoleniowych AI.
I szczerze mówiąc... część tej niejednoznaczności może nigdy całkowicie nie zniknąć.
Strona infrastrukturalna OpenLedger również wiele mówi o tym, jak zespół postrzega problemy ze skalowalnością. Zamiast zmuszać każdą interakcję bezpośrednio na głównym łańcuchu Ethereum, projekt wykorzystuje architekturę Layer 2 opartą na OP Stack z EigenDA obsługującym dostępność danych. To praktyczna decyzja, a nie efektowna. Systemy AI generują ogromne obciążenia operacyjne w porównaniu do normalnej aktywności blockchain. Żądania szkoleniowe, użycie inferencji, śledzenie wkładów, zarządzanie zbiorami danych i walidacja tworzą wymagania dotyczące przepustowości, które tradycyjne systemy Layer 1 mają trudności z efektywnym obsługiwaniem na dużą skalę.
W spokojnych warunkach dyskusje o przepustowości blockchain zwykle brzmią abstrakcyjnie. Ludzie debatują nad liczbami TPS, warstwami rozliczeniowymi, metodami kompresji i architekturą modułową, jakby były teoretycznymi problemami inżynieryjnymi. W rzeczywistej presji jednak słabości infrastruktury stają się boleśnie ludzkie. Opóźnienia frustrują użytkowników. Zator podnosi koszty. Walidatorzy zostają w tyle. Aplikacje stają się niezupełnie niezawodne w momencie, gdy popyt wzrasta. To podobne do systemów ruchu drogowego podczas sytuacji awaryjnych. Drogi, które funkcjonują idealnie w normalnych warunkach, nagle zapadają się w korki, gdy panika wkracza w środowisko.
Dlatego dyskusje o skalowalności mają większe znaczenie niż narracje marketingowe.
Warstwowa architektura OpenLedger może zmniejszyć niektóre z tych wąskich gardeł, ale systemy warstwowe wprowadzają również ryzyko zależności. To jest kompromis, o którym ludzie nie zawsze chcą rozmawiać. Większa modularność tworzy więcej punktów połączeń, a punkty połączeń to miejsca, w których zazwyczaj występują awarie. API zawodzą. Mosty zawodzą. Założenia dotyczące dostępności danych zawodzą. Zewnętrzni dostawcy infrastruktury doświadczają awarii. System może wydawać się stabilny, aż jedna wspierająca warstwa napotka niespodziewany stres i nagle aplikacje downstream dziedziczą problem, niezależnie od tego, czy są na to przygotowane, czy nie.
Projektowanie infrastruktury to głównie sztuka wyboru, jakie ryzyka jesteś gotów tolerować.
Token OPEN sam w sobie również mieści się w tej równowadze. Napędza opłaty, uczestnictwo w zarządzaniu, aktywność inferencyjną i nagrody dla uczestników. Z jednej strony, połączenie tych funkcji w jednym systemie ekonomicznym może stworzyć zgodność między użytkownikami, programistami i uczestnikami. Z drugiej strony, naraża to aktywność operacyjną na zmienność rynku. Jeśli ceny tokenów drastycznie się zmieniają, koszty użytkowania mogą stać się nieprzewidywalne, a nieprzewidywalność jest wyczerpująca dla normalnych użytkowników próbujących budować niezawodne usługi.
To jest coś, z czym kryptowaluty wciąż mają problem.
Większość ludzi nie chce myśleć o inżynierii finansowej za każdym razem, gdy korzystają z infrastruktury. Nikt nie myśli o kontraktach futures na energię elektryczną, zanim włączy włącznik światła. Dojrzała infrastruktura staje się nudna dokładnie dlatego, że użytkownicy ufają systemowi podstawowemu na tyle, aby przestać o nim myśleć. Infrastruktura kryptowalutowa często pozostaje emocjonalnie wyczerpująca, ponieważ zmienność nieustannie przenika do samego doświadczenia użytkownika.
Myślę, że skupienie OpenLedger na wyspecjalizowanych modelach AI zamiast na ogólnych narracjach 'super AI' jest kolejnym powodem, dla którego projekt wydaje się bardziej ugruntowany niż wielu konkurentów. Wąskie systemy z starannie zarządzanymi zbiorami danych często przewyższają szersze systemy w środowiskach o wysokiej niezawodności, ponieważ specjalizacja redukuje szum operacyjny. Model analizy prawnej, asystent danych medycznych lub narzędzie AI skoncentrowane na badaniach niekoniecznie potrzebuje nieskończonej ogólnej inteligencji. Potrzebuje dokładnych wyników w danej dziedzinie i godnych zaufania danych wejściowych.
Ale specjalizacja ma też swoje ograniczenia.
Im węższy staje się ekosystem, tym bardziej staje się zależny od mniejszych grup uczestników i skoncentrowanej wiedzy. Ta koncentracja może tworzyć wąskie gardła, ryzyko przechwycenia zarządzania lub stagnację, jeśli zachęty uczestników osłabną z czasem. Specjalizowane ekosystemy mają tendencję do bycia bardziej precyzyjnymi, ale czasami mniej odpornymi, ponieważ mniejsza liczba uczestników ma większe znaczenie operacyjne.
Jeszcze raz, kompromisy. Wszędzie.
To prawdopodobnie najbardziej realistyczny sposób patrzenia na OpenLedger jako całość. Nie jako jakiś cudowny system, który na zawsze naprawia własność AI, ale jako infrastruktura, która próbuje zredukować niepowodzenia koordynacji wokół wkładów danych, przypisania i dystrybucji wartości, zanim te problemy staną się całkowicie nie do opanowania.
A te problemy zdecydowanie rosną.
W miarę jak systemy AI stają się coraz bardziej komercyjnie wartościowe, napięcie między centralizowaną kontrolą a rozproszonym wkładem będzie się tylko pogarszać, a nie poprawiać. Firmy chcą defensywy. Uczestnicy chcą wynagrodzenia. Programiści chcą skalowalności. Użytkownicy chcą niezawodności. Regulatorzy chcą odpowiedzialności. Żadne z tych bodźców nie zgrywają się naturalnie przez długi czas.
Więc gdy patrzę na OpenLedger, nie widzę naprawdę gwarantowanego zwycięzcy ani jakiegoś magicznego monopol na infrastrukturę AI. Widzę próbę zbudowania systemów księgowych wokół branży, która obecnie zachowuje się jak czarna skrzynka. Może to działa na dłuższą metę. Może nie. Rynki są brutalne, a projekty infrastrukturalne często zawodzą z powodów, których nikt nie przewiduje wystarczająco wcześnie.
Ale powiem tyle.
Przynajmniej projekt wydaje się skoncentrowany na problemie, który rzeczywiście istnieje w rzeczywistym świecie, zamiast wymyślać fałszywe problemy, aby uzasadnić kolejny spekulacyjny cykl tokenów. I szczerze mówiąc, po latach obserwowania, jak hype kryptowalutowy załamuje się pod własnym nonsensownym ciężarem, to samo w sobie sprawia, że zwracam na to uwagę nieco dłużej niż zwykle.
\u003cm-27/\u003e \u003cc-29/\u003e \u003ct-31/\u003e
