Będę szczera, Brak dostępu do chatbotów.
Ta część już stała się normą.
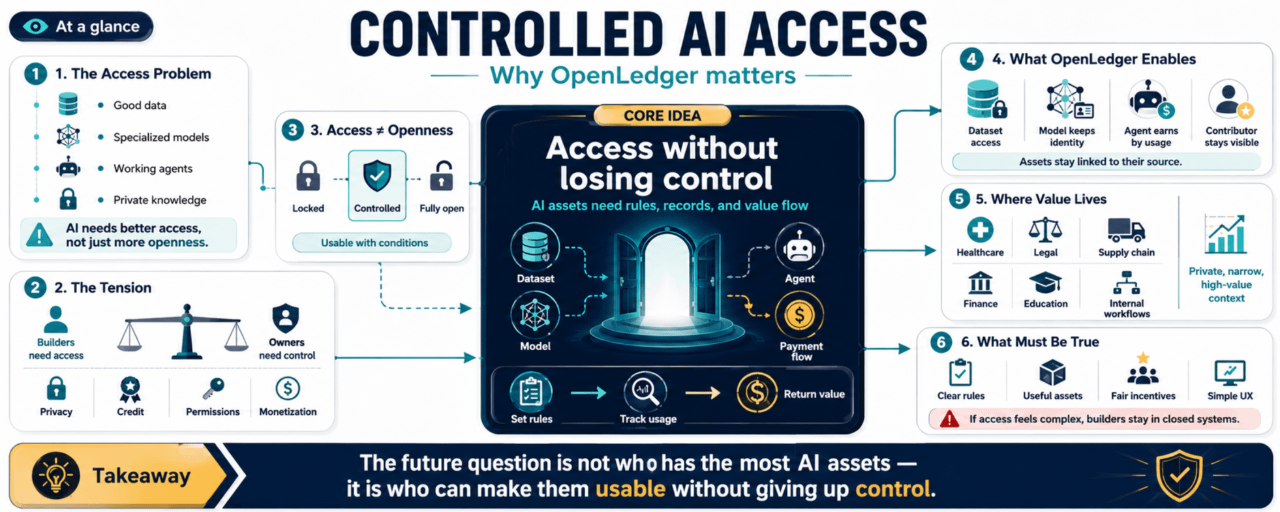
Głębszym problemem jest dostęp do rzeczy, które sprawiają, że AI jest użyteczne.
Dobre dane.
Specjalistyczne modele.
Działające agenty.
Czyste pętle feedbackowe.
Wiedza z domeny, która nie pochodzi z otwartego internetu.
Te rzeczy nie są równomiernie dostępne.
Niektóre firmy mają lata prywatnych informacji w swoich systemach. Niektóre zespoły zbudowały małe modele, które rozwiązują bardzo specyficzne problemy. Niektórzy deweloperzy mają agentów, którzy dobrze działają w wąskich przepływach pracy. Niektóre społeczności stworzyły wiedzę dzięki powtarzanym dyskusjom, korekcjom i użyciu.
Ale większość tych aktywów nie porusza się łatwo.
Są przydatne, ale nie zawsze dostępne.
W tym miejscu @OpenLedger warto spojrzeć na to z innej perspektywy.
Nie chodzi tylko o monetyzację aktywów AI. Chodzi także o bardziej uporządkowany dostęp.
Bo dostęp to nie to samo co otwartość.
To ważna różnica.
Zbiór danych nie musi być całkowicie publiczny, aby był użyteczny.
Model nie musi być darmowy dla wszystkich, aby mieć wartość.
Agent nie musi działać wszędzie, aby wywrzeć wpływ.
Czasami lepszym pytaniem jest nie to, 'Czy ktokolwiek może to użyć?'
Ale 'Czy odpowiednie osoby mogą to używać pod jasnymi zasadami?'
W tym miejscu zaczyna się interesująca część.
Budowniczowie AI często potrzebują konkretnych danych wejściowych. Nie tylko więcej danych, ale lepiej dopasowanych danych. Nie tylko większych modeli, ale modeli przeszkolonych do konkretnego zadania. Nie tylko ogólnych agentów, ale agentów, którzy rozumieją dany proces roboczy.
Jednocześnie właściciele tych aktywów mogą nie chcieć po prostu ich oddać.
I to ma sens.
Firma może nie chcieć ujawniać surowych danych klientów.
Badacz może nie chcieć, aby model był wykorzystywany bez uznania.
Programista może chcieć zarobić, jeśli agent nadal będzie używany.
Społeczność może chcieć mieć kontrolę nad tym, jak jej wspólna wiedza jest stosowana.
Więc istnieje napięcie.
AI potrzebuje dostępu.
Właściciele aktywów potrzebują kontroli.
#OpenLedger wydaje się siedzieć pomiędzy tymi dwoma potrzebami.
Wskazuje na system, w którym dane, modele i agenci mogą być udostępniani bez całkowitego odłączenia od ich źródła. Aktywa mogą mieć zasady. Użycie może być rejestrowane. Wartość może wracać, jeśli aktywo pomaga stworzyć coś użytecznego.
To może brzmieć niepozornie, ale zmienia relację.
Zamiast traktować aktywa AI jako rzeczy, które muszą być albo zablokowane, albo całkowicie oddane, istnieje środkowa droga. Kontrolowany dostęp. Śledzenie użycia. Ciągła monetyzacja.
To prawdopodobnie tam, gdzie blockchain ma bardziej praktyczną rolę.
Nie jako zastępstwo dla AI.
Nie jako slogan przywiązany do AI.
Raczej jak warstwa koordynacyjna dla aktywów, które potrzebują zezwoleń, zapisów i płatności.
Zwykle można zauważyć, kiedy brakuje koordynacji, ponieważ ludzie zaczynają budować wokół problemu ręcznie. Prywatne umowy. Niestandardowe licencje. Zamknięte partnerstwa. Jednorazowe integracje. Długie cykle zatwierdzania. Udostępnianie oparte na zaufaniu.$AIA
Te rzeczy mogą działać, ale nie skalują się łatwo.
AI rozwija się zbyt szybko, aby każdy użyteczny aktyw wymagał prywatnych negocjacji.
Jeśli OpenLedger może pomóc w wyjaśnieniu zasad, to więcej aktywów może stać się użytecznych bez zmuszania właścicieli do oddania wszystkiego. To praktyczna idea pod powierzchnią.
I ma to znaczenie, ponieważ przyszłość AI może nie być budowana tylko na podstawie publicznych danych i ogromnych modeli.
Wiele z następnej wartości może pochodzić z prywatnej, wąskiej, trudnej do uzyskania wiedzy.
Procesy robocze w opiece zdrowotnej.
Dokumenty prawne.
Dane z łańcucha dostaw.
Wzorce finansowe.
Logi przemysłowe.
Opinie w edukacji.
Rozmowy wsparcia.
Procesy wewnętrzne w firmach.
To nie zawsze są efektowne źródła. Ale często tam tkwi prawdziwa użyteczność.
Problem polega na tym, że są wrażliwe, fragmentaryczne i trudne do wycenienia.
Więc pozostają za murami.
Podejście OpenLedger sugeruje, że te mury nie zawsze muszą być usuwane. Może po prostu potrzebują lepszych drzwi.$PLAY
To spokojniejszy sposób myślenia o tym.
Nie wszystko powinno być otwarte. Nie wszystko powinno być ukryte. Niektóre rzeczy powinny być dostępne na warunkach.
A kiedy warunki można jasno określić, nowe rynki stają się możliwe.
Budowniczy mógłby uzyskać dostęp do zbioru danych bez posiadania go na własność.
Model mógłby być używany w większym systemie, zachowując swoją tożsamość.
Agent mógłby działać w ramach procesu roboczego i zarabiać na rzeczywistym użyciu.
Współtwórca mógłby uczestniczyć, nie znikając w końcowym produkcie.
Oczywiście, system musi się wykazać.
Zasady muszą być zrozumiałe. Aktywa muszą być użyteczne. Zachęty muszą być wystarczająco sprawiedliwe, aby ludzie się tym interesowali. A doświadczenie musi być na tyle proste, aby budowniczowie nie unikali go.
To zawsze jest trudna część.
Niemniej jednak problem dostępu jest realny.
AI chce więcej kontekstu, ale najlepszy kontekst jest często zamknięty w miejscach, które nie mogą po prostu wszystko otworzyć. To jest luka, którą OpenLedger stara się obejść.#BNBBreaks740USDTUp12Percent
Może to jest kąt, który ma najwięcej sensu.
Nie dane AI jako coś do wydobycia.
Nie modele jako pliki do sprzedaży raz.
Nie agenci jako izolowane narzędzia.
Raczej jak warstwa kontrolowanego dostępu do użytecznych elementów AI, które są obecnie trudne do osiągnięcia.
A jeśli ta warstwa działa, nawet cicho, pytanie zaczyna się przesuwać.
Z 'Kto ma najwięcej aktywów AI?'
do
'Kto może uczynić swoje aktywa AI użytecznymi, nie tracąc kontroli?'
To wydaje się być prawdziwą rozmową, która zaczyna się kształtować.
$OPEN
Artykuł
Jednym z cichych problemów w AI jest dostęp.
Zastrzeżenie: zawiera opinie osób trzecich. To nie jest porada. Binance AI może być używane bez gwarancji. Zobacz Regulamin