
OpenLedger najpierw przyciągnął moją uwagę, ponieważ stara się rozwiązać problem, który zazwyczaj omawia się w wielkich hasłach, ale rzadko jest realizowany w praktyczny sposób: jak dane, modele i agenci stają się ekonomicznie użyteczni, nie tracąc z oczu tego, kto tak naprawdę stworzył wartość, która za nimi stoi?
To było pytanie, które sprawiło, że spędziłem więcej czasu nad tym projektem. Na początku, OpenLedger wyglądał jak kolejny projekt infrastrukturalny zbudowany wokół tokena i szerokiej narracji technicznej. Ale im więcej badałem, tym bardziej uświadamiałem sobie, że jego prawdziwe skupienie jest węższe i bardziej interesujące. OpenLedger stara się zbudować system, w którym wkład danych, tworzenie modeli, śledzenie użycia i dystrybucja nagród są ze sobą połączone, zamiast być traktowane jako oddzielne elementy.
To brzmi prosto, ale nie jest.
Dziś osoba może dostarczyć użyteczne dane, zespół może użyć tych danych do poprawy modelu, inny deweloper może zbudować produkt na ich podstawie, a pierwotny uczestnik może nigdy nie dowiedzieć się, czy ich praca miała znaczenie. Nawet gdy zestaw danych jest wartościowy, jego wartość często znika, gdy wchodzi do większego systemu. OpenLedger opiera się na idei, że to nie powinno być normą. Jeśli dane pomagają tworzyć wartość, powinna istnieć możliwość śledzenia tego wkładu i nagradzania go.
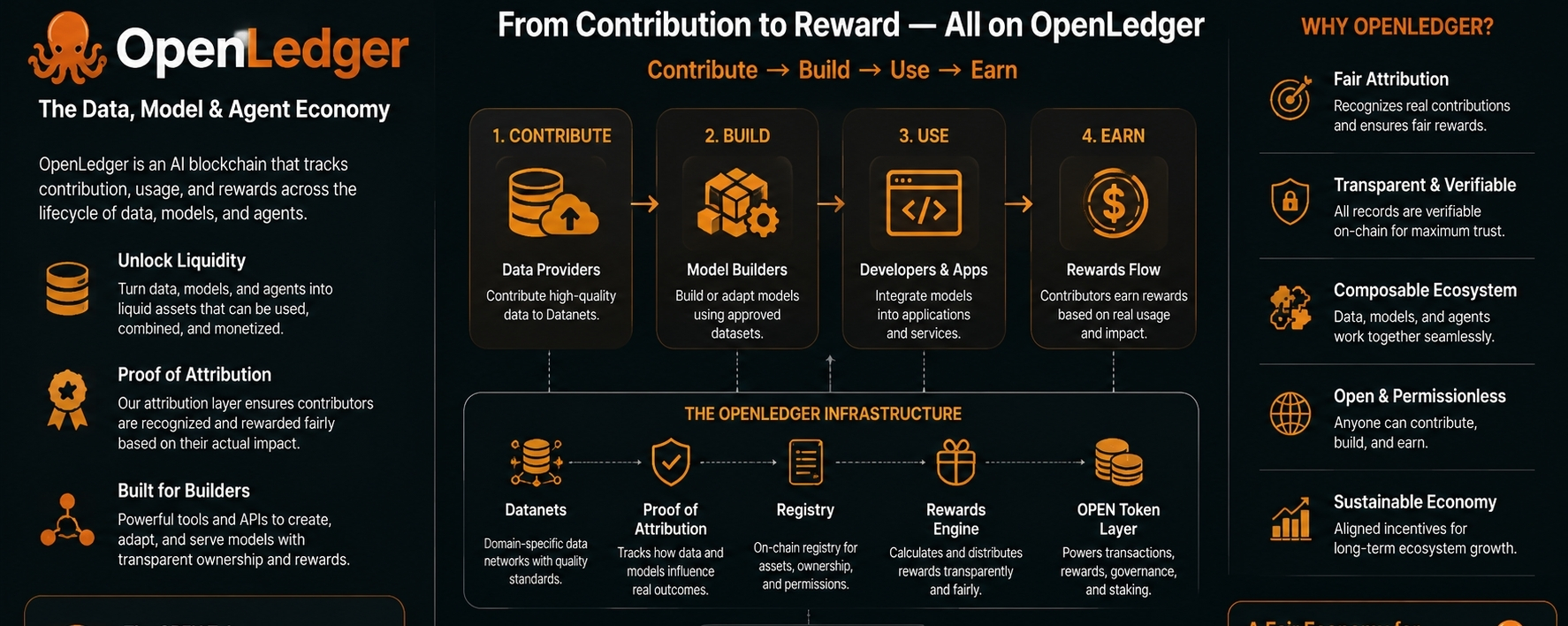
To tutaj projekt staje się dla mnie interesujący. OpenLedger nie tylko prezentuje się jako miejsce do przechowywania lub handlu danymi, ale stara się stworzyć gospodarkę wkładów wokół danych i modeli. Celem jest uczynienie użytecznych wkładów widocznymi, mierzalnymi i płatnymi. To jest sedno projektu.
Głównym koncepcją, która pojawiała się w trakcie moich badań, było Dowód Atrybucji. W prostych słowach, OpenLedger chce zidentyfikować, które dane lub uczestnicy wpłynęli na model, a następnie rozdzielić nagrody na podstawie tego wpływu. To jest ta część projektu, która nadaje mu wyraźną tożsamość. Bez atrybucji, OpenLedger wyglądałoby jak kolejny rynek. Z atrybucją staje się próbą zbudowania torów księgowych dla cyfrowych wkładów.
Ale to także najtrudniejsza część.
Atrybucja brzmi czysto, gdy jest wyjaśniana z daleka. W praktyce jest chaotyczna. Model nie zawsze używa danych w bezpośredni lub oczywisty sposób. Jeden mały punkt danych może mieć znaczenie, ponieważ wypełnia brakującą lukę. Duży zestaw danych może wyglądać imponująco, ale dodaje bardzo mało, jeśli powtarza to, co model już wie. Niszowy zestaw danych może być bezużyteczny w większości przypadków, ale niezwykle cenny w konkretnej dziedzinie. Więc prawdziwe pytanie nie brzmi, czy OpenLedger może zarejestrować wkłady. Prawdziwe pytanie brzmi, czy może zmierzyć wkład wystarczająco sprawiedliwie, aby ludzie zaufali systemowi nagród.
To jest moment, w którym stałem się zarówno zainteresowany, jak i ostrożny.
Podejście OpenLedger w dużej mierze zależy od Datanetów. To strukturalne sieci danych zbudowane wokół konkretnych dziedzin lub przypadków użycia. Uważam, że to jedna z sensowniejszych części projektu, ponieważ nie wszystkie dane mają tę samą wartość. Dane finansowe, dane prawne, dane medyczne, dane publiczne, dane deweloperów i dane wsparcia klientów mają różne standardy i różne ryzyka. Traktowanie ich jako jednego ogólnego zasobu nie miałoby sensu.
Organizując dane w bardziej ukierunkowane sieci, OpenLedger daje sobie lepszą szansę na stworzenie użytecznych rynków. Ukierunkowany zestaw danych można oceniać jaśniej. Budowniczowie mogą zrozumieć, nad czym pracują. Uczestnicy mogą zobaczyć, gdzie pasują ich dane. System może rozwijać różne standardy jakości dla różnych obszarów, zamiast udawać, że wszystkie dane są równe.
Jednak Datanety stwarzają również trudne wyzwanie. Jeśli nagrody są dostępne, ludzie będą próbowali je zdobyć w najłatwiejszy możliwy sposób. Niektórzy uczestnicy mogą przesyłać dane niskiej jakości. Niektórzy mogą kopiować istniejące materiały. Niektórzy mogą przesyłać duplikaty lub nieznacznie zmodyfikowane informacje. Inni mogą próbować zrozumieć system oceniania i przesyłać dane, które dobrze wypadają na papierze, ale nie tworzą rzeczywistej wartości.
To poważne ryzyko dla OpenLedger. Każda sieć, która płaci za wkład, musi radzić sobie z osobami, które uczestniczą tylko po to, by wyciągać nagrody. Projekt może mówić o walidacji, reputacji, ocenie i karach, ale prawdziwy test nadejdzie, gdy wystarczająca wartość będzie przepływać przez system, aby przyciągnąć poważne farming i manipulację.
Dlatego nie sądzę, że OpenLedger powinno być oceniane tylko na podstawie tego, ilu użytkowników przyciąga na początku. Wczesna aktywność może być myląca. Zachęty mogą sprawić, że projekt będzie wyglądał na aktywny, zanim pojawi się rzeczywisty popyt. Ważniejsze pytanie brzmi, czy wysokiej jakości uczestnicy pozostaną, czy budowniczowie faktycznie używają danych i czy system nagród nadal ma sens po tym, jak wczesne podniecenie opadnie.
Kolejną częścią OpenLedger, która się wyróżnia, jest to, że projekt nie tylko buduje pomysł. Stara się budować narzędzia wokół tego pomysłu. ModelFactory, na przykład, jest zaprojektowany, aby pomóc użytkownikom tworzyć lub dostosowywać modele przy użyciu zatwierdzonych zestawów danych. To ma znaczenie, ponieważ projekt nie może polegać tylko na wysoko technicznych użytkownikach. Jeśli OpenLedger chce prawdziwych uczestników i budowniczych, proces musi być zrozumiały.
To jedno z największych wyzwań produktowych projektu. Uczestnik danych chce prostej odpowiedzi: co mogę przesłać, jak to będzie oceniane i kiedy dostanę nagrodę? Budowniczy chce czegoś innego: które zestawy danych są dostępne, jak wiarygodne są, jakie prawa się z nimi wiążą i jak łatwo jest je wykorzystać w prawdziwym produkcie? Posiadacz tokenów chce wiedzieć, czy OPEN ma realny popyt, czy tylko tymczasową uwagę. OpenLedger musi obsługiwać wszystkie te grupy, nie wprowadzając w błąd.
To nie jest łatwe.
Projekt obejmuje również OpenLoRA, które koncentruje się na ułatwieniu i zwiększeniu efektywności serwowania wielu dostosowanych modeli. To może brzmieć jak techniczny szczegół, ale ma znaczenie. Jeśli OpenLedger odniesie sukces w stworzeniu wielu specyficznych dla dziedziny modeli, koszty i złożoność ich serwowania mogą stać się wąskim gardłem. System, który zachęca do specjalistycznych modeli, również potrzebuje praktycznego sposobu ich uruchamiania. W przeciwnym razie rynek staje się interesujący w teorii, ale trudny do użycia w produkcji.
To jeden z powodów, dla których uznałem OpenLedger za bardziej znaczący, niż się spodziewałem. Nie tylko mówi o własności i nagrodach. Dotyka również praktycznych części przepływu pracy: organizacji danych, adaptacji modeli, serwowania, użycia i rozliczania nagród. To nadaje projektowi większą głębię.
Ale większa głębokość oznacza również większe ryzyko wykonania.
OpenLedger stara się zbudować łańcuch, warstwę atrybucji, Datanety, narzędzia modelowe, infrastrukturę serwowania, zachęty tokenowe, zarządzanie i partnerstwa w ekosystemie. To dużo obszaru powierzchni. Wizja projektu jest szeroka, ale szerokie wizje są trudne do wykonania. Jeśli zbyt wiele elementów pozostanie niedokończonych, użytkownicy mogą mieć trudności ze zrozumieniem, co tak naprawdę jest najlepsze w produkcie.
Dla mnie najjaśniejszą tożsamością OpenLedger jest atrybucja. To powinno pozostać w centrum projektu. Im bardziej OpenLedger koncentruje się na udowadnianiu i nagradzaniu wkładów, tym łatwiej staje się zrozumieć, dlaczego projekt istnieje. Jeśli spróbuje stać się wszystkim naraz, przekaz stanie się słabszy.
Strona tokena również ma znaczenie, o które należy starannie zadbać. OPEN jest używane do opłat, nagród, zachęt, zarządzania i aktywności w ekosystemie. Nadaje mu to rolę wewnątrz sieci. Podaż jest ograniczona, a duża część jest przydzielona do wzrostu społeczności i ekosystemu. Na papierze to pasuje do celu projektu, ponieważ uczestnicy i budowniczowie potrzebują zachęt.
Ale użyteczność tokenów nie automatycznie tworzy popyt na tokeny.
Aby OPEN miało znaczenie w dłuższej perspektywie, ludzie muszą korzystać z sieci, ponieważ rozwiązuje rzeczywisty problem. Jeśli aktywność zależy głównie od nagród, token może być pod presją, gdy zachęty spowolnią lub odblokowania zwiększą podaż. To powszechny problem z wczesnymi sieciami. Mogą szybko przyciągać uwagę, ale zrównoważony popyt pojawia się tylko wtedy, gdy produkt staje się użyteczny bez ciągłych subsydiów.
Dlatego oddzielam swoje spojrzenie na projekt od mojego spojrzenia na token. OpenLedger może być technicznie interesujący, podczas gdy OPEN wciąż niesie ryzyko rynkowe. Projekt może mieć silną ideę, podczas gdy token wciąż stoi przed zmiennością, rozwodnieniem i spekulacją. Oba te aspekty mogą być prawdziwe jednocześnie.
Gdy porównuję OpenLedger z innymi projektami, jego pozycja staje się jaśniejsza. Bittensor koncentruje się szerzej na rynkach zachęt dla inteligencji maszynowej. Ocean Protocol spędził lata na pracy nad monetyzacją danych i prywatnym dostępem do danych. Story Protocol koncentruje się na programowalnej własności intelektualnej i licencjonowaniu. Grass skupia się bardziej na zbieraniu rozproszonych danych publicznych.
OpenLedger pokrywa się z częściami tych pomysłów, ale jego główny cel jest inny. Stara się połączyć dane, modele, atrybucję i nagrody w jeden system. To jest jego przewaga. To również jego największe ryzyko, ponieważ atrybucja jest znacznie trudniejsza niż po prostu stworzenie rynku.
Najbardziej obiecująca wersja OpenLedger to taka, w której dane wysokiej jakości specyficzne dla dziedziny wchodzą do Datanetów, budowniczowie używają tych danych do tworzenia lepszych modeli, użycie jest jasno śledzone, a uczestnicy otrzymują nagrody na podstawie rzeczywistego wpływu. W tej wersji OpenLedger staje się użyteczną warstwą ekonomiczną dla osób, które tworzą wartość pod powierzchnią.
Słabsza wersja to taka, w której zachęty przyciągają niskiej jakości zgłoszenia, atrybucja staje się niejasna, budowniczowie nie ufają zestawom danych, a aktywność zanika, gdy nagrody stają się mniej atrakcyjne. To jest wersja, której projekt musi unikać.
Co mi się najbardziej podoba w OpenLedger, to fakt, że jest ukierunkowane na rzeczywisty problem. Obecna gospodarka cyfrowa często nagradza końcowy produkt, ukrywając wkłady, które to umożliwiły. Uczestnicy danych, kuratorzy, eksperci dziedzinowi i budowniczowie modeli mogą tworzyć wartość, nie otrzymując trwałego uznania. OpenLedger stara się uczynić ten wkład widocznym.
Co mnie najbardziej niepokoi, to czy system może pozostać sprawiedliwy, gdy w grę wchodzą pieniądze. Każdy mechanizm nagradzania staje się celem. Jeśli wyniki atrybucji mogą być manipulowane, system traci zaufanie. Jeśli dane niskiej jakości wchodzą do sieci, budowniczowie odchodzą. Jeśli nagrody nie odzwierciedlają rzeczywistej użyteczności, uczestnicy tracą pewność siebie. Jeśli gospodarka tokenów staje się ważniejsza niż produkt, projekt ryzykuje przyciągnięcie niewłaściwego rodzaju aktywności.
Spędzając czas z OpenLedger, nie widzę go jako gotowego rozwiązania. Widzę to jako ambitną próbę zbudowania infrastruktury wokół wkładu, atrybucji i płatności. To sprawia, że warto to obserwować, ale z ostrożnością.
Podstawowa idea projektu jest silna: uczestnicy dostarczający dane i modele nie powinni znikać, gdy ich praca staje się użyteczna. Trudna część to dokładne udowodnienie wkładu, sprawiedliwe nagradzanie i budowanie produktów wystarczająco prostych, aby prawdziwi użytkownicy mogli je przyjąć.
Przyszłość OpenLedger będzie zależała od tego, czy uda mu się przekształcić atrybucję z miłego pomysłu w zaufany system. Jeśli to się uda, projekt może zająć ważną pozycję w ekonomii danych i modeli. Jeśli nie, może pozostać kolejnym ambitnym projektem infrastrukturalnym z dobłą tezą, ale ograniczonym realnym zasięgiem.
Na razie to, co wyróżnia OpenLedger, to nie hype, ale powaga problemu, który próbuje rozwiązać. Projekt pyta, kto stworzył wartość, jak tę wartość można udowodnić i jak nagrody powinny się przemieszczać, gdy cyfrowe systemy opierają się na wielu niewidocznych uczestnikach.
To pytanie jest trudne. Ale to właśnie dlatego OpenLedger zasługuje na uwagę.
\u003cm-74/\u003e\u003cc-75/\u003e \u003ct-77/\u003e\u003ct-78/\u003e