
Most people think data creates value when it is collected.
I used to think that too.
More data means better models. Better models mean better products. Better products mean more value. It sounds simple when you say it like that.
But the more I look at @OpenLedger, the more that explanation feels unfinished.
Because collecting data is not really the hard part anymore.
The internet solved that years ago.
Every search, every click, every conversation, every image, every preference, every transaction, every small online behavior leaves something behind. We are not living in a world where data is rare. We are living in a world where data is everywhere.
Almost too much of it.
The strange part is not collection.
The strange part is what happens after collection.
Someone takes that data.
A model gets trained.
A product becomes smarter.
An AI agent becomes more useful.
A company builds a business around it.
Value keeps growing from it.
And the original contributor?
Most of the time, they disappear.
That has become so normal that people barely stop to question it anymore.
Data goes in.
Value comes out.
The connection between the two quietly disappears.
That is the part that bothers me.
Because if data helps create intelligence, and that intelligence later creates value, then why does the data become economically dead the moment it enters the system?

That question is why OpenLedger caught my attention.
Not because it is just another AI project.
Not because it is using blockchain language around data.
But because it seems to be asking a deeper question:
What if data could stay connected to the value it helps create?
That changes the whole conversation for me.
In most AI systems, data is treated like raw material. It is collected, used, absorbed, and then forgotten. The model becomes valuable. The platform captures the upside. The contributor becomes invisible.
OpenLedger seems to look at data differently.
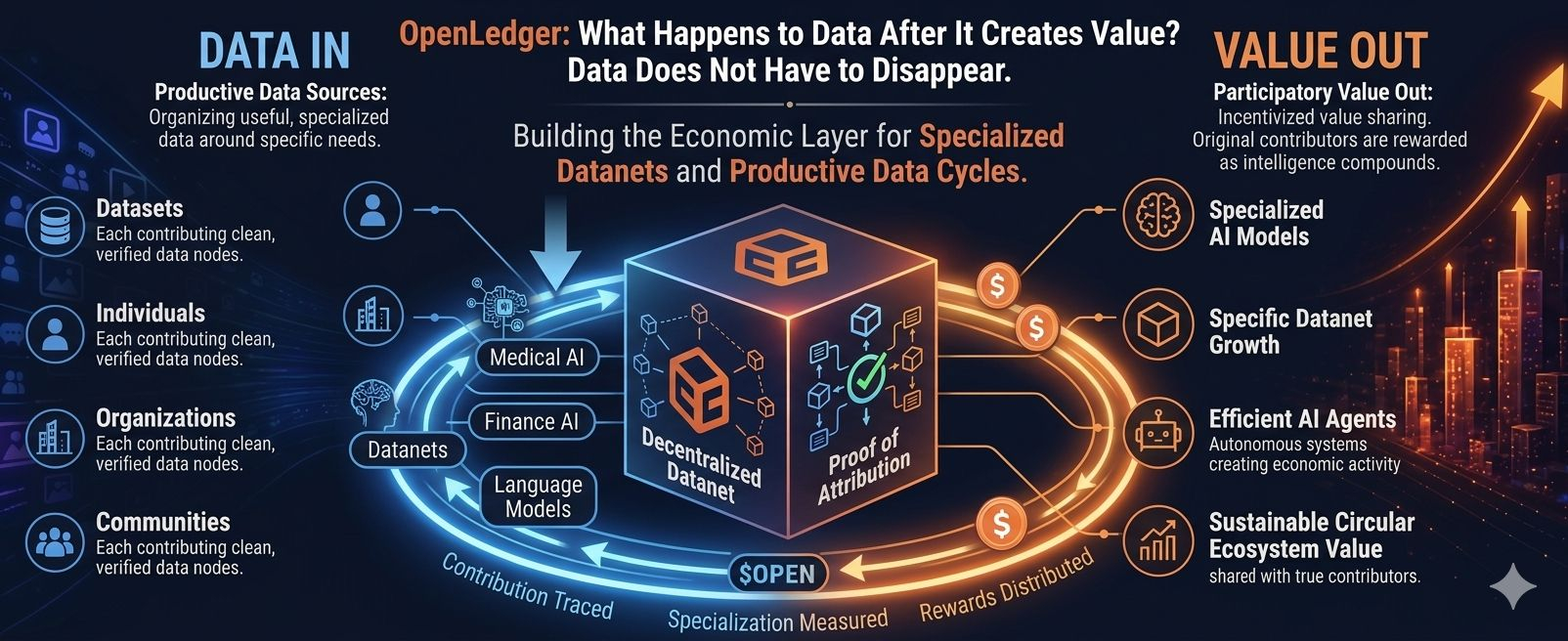
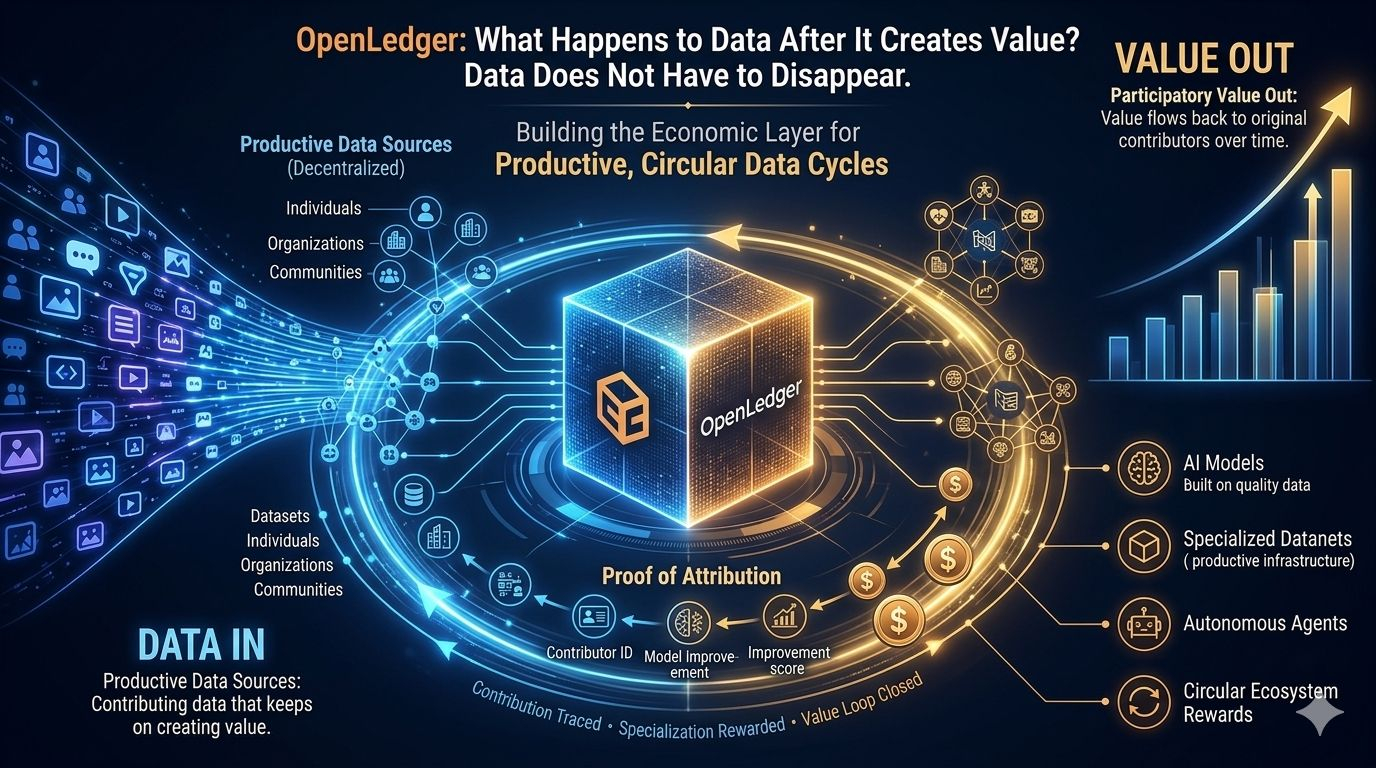
It treats data less like something that gets consumed once and more like something that can keep contributing over time.
Almost like productive infrastructure.
If a dataset helps improve a model, that contribution should not vanish. If a Datanet strengthens a specific domain of intelligence, that work should not be treated like background noise. If an AI agent becomes more useful because of certain data, then the source of that usefulness should not be erased.
This is where Datanets become important.
To me, Datanets are not just about collecting more information. The world already has enough random information. The real issue is organizing useful data around specific needs, specific models, and specific communities.
Better data.
Cleaner data.
Relevant data.
Data that can actually improve intelligence.
That is a very different thing from just gathering as much as possible.
And this is where Proof of Attribution becomes the real backbone.
Because without attribution, everything becomes blurry.
A contributor helps.
A model improves.
An application creates value.
But nobody can clearly see the connection.
With Proof of Attribution, OpenLedger is trying to make that connection visible. It gives the ecosystem a way to trace how data, models, agents, and contributors are connected to outcomes.
And honestly, that feels important.
Because today, the relationship between contributors and AI platforms is mostly one-way.
People contribute information.
Models improve.
Platforms benefit.
OpenLedger is trying to make that relationship more circular.
Data providers, model builders, validators, developers, and application creators can become part of the same value loop. Not perfectly. Not magically. But at least in a more visible and accountable way.
That is where $OPEN starts to make sense.
If contribution can be traced, then incentives can be built around it. $OPEN can support the value layer where data, models, agents, attribution, and rewards are connected instead of being separated into different worlds.
For me, the interesting part is not only the technology.
It is the incentive shift.
Because incentives change behavior more than speeches ever do.
If contributors know their data may stay connected to future value, they have a reason to care about quality.
Developers have a reason to use better datasets.
Model builders have a reason to build more specialized systems.
Communities have a reason to contribute something useful instead of just adding more noise.
The system starts moving away from extraction and closer to participation.
At least, that is the idea.
And I think it is important to be honest here.
This is not easy.
Tracking contribution is hard.
Measuring value is hard.
Bad data can enter.
People can try to game incentives.
Markets may not care at first.
Attribution only matters if the intelligence being produced actually has demand.
So no, I do not see OpenLedger as something to blindly hype.
But I do think it is pointing at a problem that keeps getting bigger.
AI is becoming more capable every month. AI agents are moving closer to real workflows. Models are creating more economic value. Automated systems are starting to influence finance, content, research, development, and decision-making.
Yet the people and data behind that intelligence are still mostly disconnected from the value it creates.
That feels unfinished.
And maybe that is the real point.
The future of AI will not only be about bigger models or faster agents.
It will also be about trust.
Where did the intelligence come from?
Who helped shape it?
What data made it better?
Who deserves to stay connected to the value?
These questions may sound slow compared to the hype around AI. But over time, I think they become harder to avoid.
Because if intelligence becomes one of the most valuable assets of the next decade, then understanding who helped create that intelligence should matter.
That is why #OpenLedger stays in my mind.
Not because it promises a perfect solution.
But because it is asking a question that feels overdue.
Can the relationship between contribution and value be rebuilt?
If OpenLedger can make that relationship more visible, more traceable, and more economically connected, then the impact could reach beyond one protocol.
It could change how we think about data itself.
Not as something collected once and forgotten.
But as something that can keep participating in the value it helps create.
And maybe that is the real shift.
Data should not disappear after it becomes useful.