Rynek wydawał się dzisiaj cichszy niż zwykle. Nie martwy — po prostu ta dziwna energia pomiędzy, gdzie nic nie rośnie, ale też nic nie krwawi. W końcu... przewijałem. Patrzyłem na rzeczy, które dodałem do zakładek, ale nigdy ich nie przeczytałem.
W ten sposób wpadłem w OpenLedger.
Nie szukałem tego konkretnie. Myślałem o całym problemie danych AI — wiesz, to nieprzyjemne uczucie, że każdy model, którego używasz, staje się mądrzejszy dzięki konsumowaniu rzeczy, które stworzyli ludzie, a nikt za to nic nie dostał. Pisarze, programiści, badacze. Po prostu... cisi współtwórcy czegoś, czego nigdy nie będą mieli.
Zacząłem czytać o $OPEN , i na początku wydawało się to kolejną "naprawiamy AI" reklamą. Prawie zamknąłem zakładkę.
Ale wtedy coś małego przykuło moją uwagę i nie mogłem tego puścić.
OpenLedger nie tylko próbuje płacić ludziom za dane. Stara się uczynić wkład w dane śledzalnym — na stałe, weryfikowalnie śledzalnym — dla modeli, które faktycznie je wykorzystały.
I musiałem się nad tym zastanowić przez chwilę. Bo to są dwie bardzo różne rzeczy.
Większość ludzi, gdy słyszy "zapłać za swoje dane", wyobraża sobie coś w stylu ankiety. Przesyłasz coś, ktoś płaci ci stałą opłatę, koniec. Transakcyjne. Oderwane od wyniku.
Czego OpenLedger zdaje się dążyć, jest inne: jeśli model trenowany na twoim zbiorze danych staje się mądrzejszy, jest używany więcej, generuje wartość — powinieneś mieć prawo do tego. Nie tylko jednorazowa opłata za przesłanie. Wkład sam w sobie jest rejestrowany w blockchainie, powiązany z wydajnością modelu, śledzalny w czasie.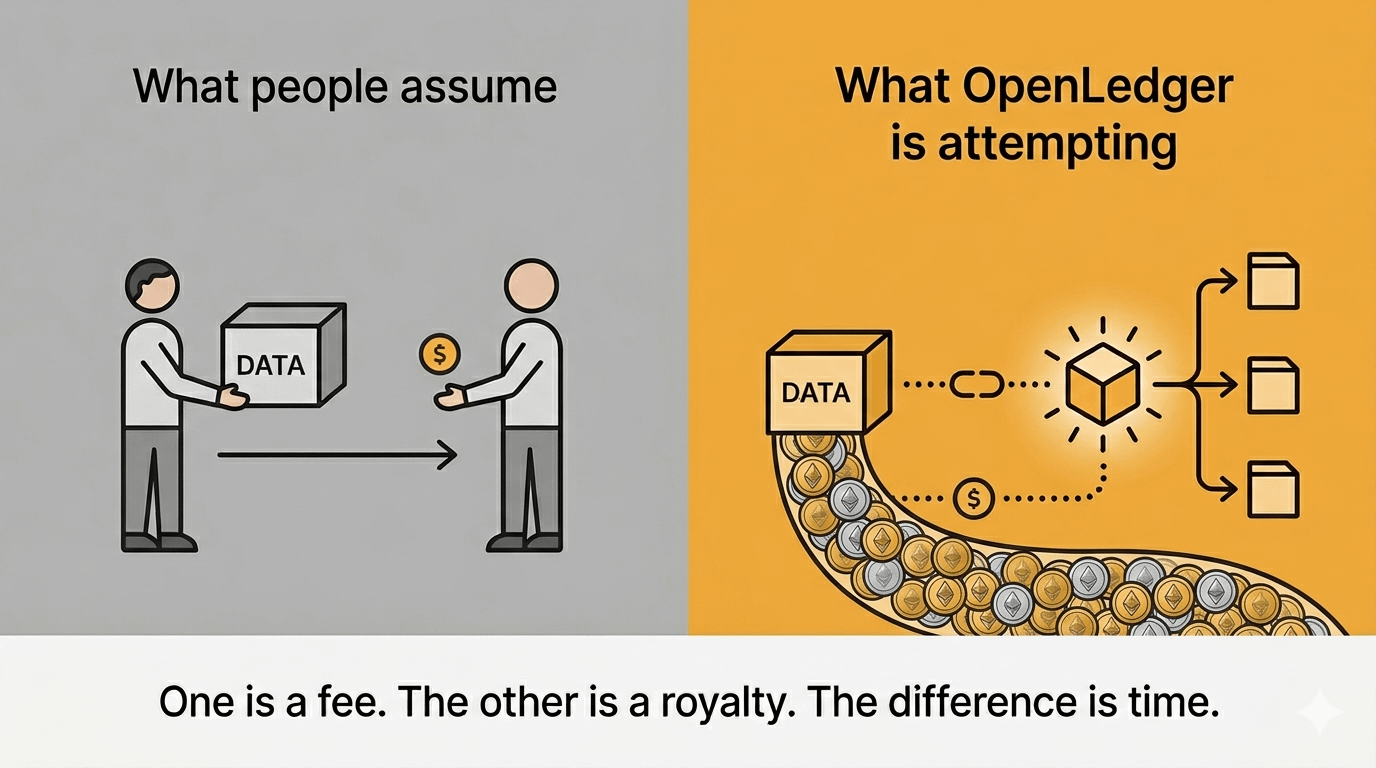
Myślałem, że to tylko ładniejsza wersja tego samego. Ale tak naprawdę to nie jest.
To bliżej tego, jak działają tantiemy w muzyce. Piszesz piosenkę raz, jest używana tysiące razy, wciąż zarabiasz. Tylko "piosenka" tutaj to zbiór danych. A "czasy, kiedy jest używana" to każde uruchomienie wnioskowania w dół.
To zrozumienie było trochę niekomfortowe. Bo jeśli to naprawdę działa — jeśli wkład jest faktycznie śledzalny na tym poziomie — to całe nasze myślenie o rynkach danych AI wydaje się dziwnie prymitywne w tej chwili.
Ale oto część, która mnie niepokoi.
Śledzenie danych brzmi czysto w teorii. W praktyce modele nie używają danych jeden do jednego. Mieszają je, transformują, łączą dziesięć tysięcy wkładów w aktualizację wagi, która nie przypomina żadnego pojedynczego źródła. Jak więc właściwie śledzić swój wkład przez to? Kto decyduje, ile kredytu dostaje twój zbiór danych w porównaniu do pozostałych 40 000, które trenowały obok?
Nie jestem całkowicie przekonany, że to wytrzyma presję. Problem atrybucji w uczeniu maszynowym jest naprawdę trudny — nie "musimy mieć lepszych narzędzi", raczej bardziej jak "to może być filozoficznie nierozwiązywalne". A jeśli model atrybucji jest chociaż trochę możliwy do zmanipulowania, to wszystko zaczyna wyglądać mniej jak system tantiemowy, a bardziej jak system punktowy, który wydaje się sprawiedliwy, ale taki nie jest.
To nie znaczy, że mówię, że to nie wyjdzie. Naprawdę jeszcze nie wiem. Ale myślę, że ludzie, którzy wskakują w $OPEN bez zadania tego pytania, pomijają najważniejsze.
To, co sprawia, że to jest interesujące — i ciągle wracam do tego — to kto to dotyczy, jeśli to działa.
To nie są inwestorzy detaliczni, naprawdę. To ludzie, którzy faktycznie produkują zorganizowane, wysokiej jakości dane. Badacze. Eksperci w niszowych dziedzinach. Ludzie w obszarach, gdzie dobre dane do treningu są naprawdę rzadkie i rzeczywiście cenne. Jeśli ci ludzie zaczną być wynagradzani proporcjonalnie do tego, jak bardzo ich dane poprawiają wyniki modelu... to zmienia strukturę zachęt wokół rozwoju AI w sposób, który trudno w tej chwili w pełni przemyśleć.
To cicho przekształca $OPEN "token AI w krypto" w coś, co może mieć rzeczywiste, powtarzalne zapotrzebowanie związane z rzeczywistym wykorzystaniem modelu. Nie hype demand. Zapotrzebowanie na użyteczność. Tego rodzaju, które nie znika, gdy narracja się zmienia.
Myślałem, że to tylko kolejny rynek danych. Właściwie stara się być czymś bliższym warstwie atrybucyjnej pod AI.
Czy to jest osiągalne, to inna kwestia.
W każdym razie. Wykresy nadal wyglądają dla mnie nieprzekonująco. Prawdopodobnie po prostu będę obserwować to z daleka na razie — zobaczę, jak strona z wkładami danych się rozwija, zanim wyrobię sobie silniejsze zdanie.
Wciąż myślę o tej kwestii tantiem. Ta część nie opuszcza mnie.