Miałem kilka godzin bez pilnych spraw, więc wróciłem do czegoś, co chciałem dokładnie przeanalizować — @OpenLedger
Zaglądałem do tego wcześniej. Sprawdziłem pulpit, obserwowałem jak blok czy dwa przelatują, widziałem mikro-wypłaty. Było to na tyle interesujące, że dodałem to do zakładek i zapomniałem na chwilę. Tym razem naprawdę spędziłem z tym więcej czasu.
I gdzieś w okolicach drugiej godziny coś się zmieniło w moim sposobie czytania tego.
Sposób, w jaki większość ludzi mówi o OpenLedger — w tym większość treści, które widziałem — jest zasadniczo taki: posiadasz swoje dane, dostajesz wypłatę, gdy AI z nich korzysta. To jest nagłówek. Wkład danych, model się trenuje, wkładca zarabia. Czysta historia. Ma sens na pierwszy rzut oka.
Ale to tak naprawdę nie jest to, co się dzieje mechanicznie.
To, co robi system Proof of Attribution OpenLedger, jest bliższe temu: dostajesz wypłatę, gdy następuje inferencja. Nie trening. Nie przesyłanie. Nie wtedy, gdy twoje dane trafiają do jakiegoś modelu. Wyzwalaczem wypłaty jest bieżąca inferencja — model AI aktywnie wykonujący zapytanie i pobierający z przypisanych źródeł w czasie rzeczywistym.
Myślałem, że to to samo. To nie jest to samo.
Trening jest jednorazowym wydarzeniem. Dzieje się, model przyswaja dane, a twój wkład zostaje w coś, czego naprawdę nie możesz śledzić po fakcie. Inferencja jest ciągła. To każde zapytanie, każde wezwanie, każdy wynik, który model produkuje i który dotyka twojego przypisanego zbioru danych. Mechanizm tantiemowy nie patrzy wstecz na to, co ukształtowało model — obserwuje, czego model sięga teraz.
Ta różnica zostawała ze mną przez chwilę.
Bo oto, co to naprawdę oznacza: wartość twojego wkładu nie jest ustalona w momencie przesyłania. Fluktuuje w zależności od tego, jak często model potrzebuje tego, co mu dałeś. Jeśli wniósłbyś coś bardzo specyficznego — wiedza z niszy, rzadki format, etykietowanie w przypadkach granicznych — a popyt przedsiębiorstw na tę konkretną rzecz wzrośnie, stawka wypłaty wzrośnie wraz z tym. Nie dlatego, że zrobiłeś coś nowego. Po prostu dlatego, że wzorce użytkowania się zmieniły.
To naprawdę różni się od tego, jak dotąd działała monetyzacja danych. Nie sprzedajesz czegoś raz. Trzymasz coś, co wypłaca przy wykorzystaniu. Bardziej przypomina strukturę tantiem niż sprzedaż.
Zacząłem myśleć o tym mniej jak o "rynku danych", a bardziej jak o pasywnej infrastrukturze. Wkładca danych staje się czymś w rodzaju węzła w sieci, który dostaje wypłatę w zależności od ruchu zapytań.
Ale to jest część, która mnie niepokoi.
Ten model działa tylko wtedy, gdy istnieje prawdziwa, utrzymująca się inferencja przedsiębiorstw na dużą skalę. A w tej chwili — z tego, co mogę zaobserwować — strona wkładców rośnie znacznie szybciej niż strona popytu. Są ludzie, którzy przesyłają dane, zarabiają mikrowypłaty, obserwując pulpity. Infrastruktura podażowa działa.
Strona przedsiębiorstw? To ta część, która wciąż wydaje się wczesna. I mam na myśli naprawdę wczesna. Nie "to nadchodzi" wczesna. Bardziej jak: szyny są, ale pociągi jeszcze nie jeżdżą w takiej skali, która uczyniłaby matematykę tantiemową znaczącą dla większości wkładców.
Nie jestem pewien, jak długo ta luka utrzyma się, zanim entuzjazm wkładców zacznie słabnąć. Stawki wypłat, które obserwowałem, nie były niczym — ale nie były też "to zmienia mój miesiąc". A jeśli popyt nie wzrośnie, aby zaspokoić podaż, która już została wniesiona, cały system atrybucji zaczyna wyglądać na eleganckie rozwiązanie problemu, który nie ma jeszcze wystarczającej liczby klientów.
To nie jest koniecznie śmiertelna wada. Ale to jest coś, na co bym zwracał uwagę.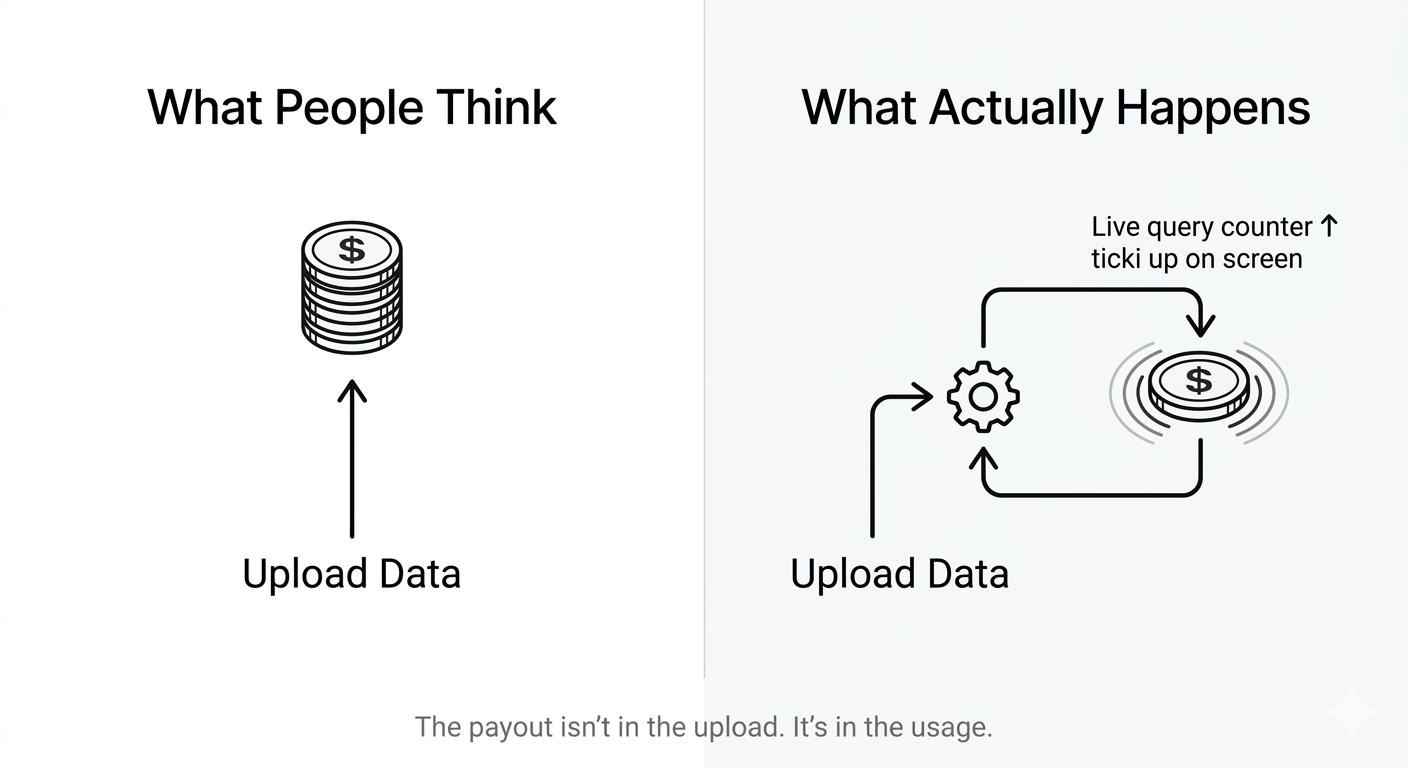
Jest też warstwa, do której ciągle wracam: kto tak naprawdę teraz czerpie największe korzyści z tego? Przypadkowy uploader — ktoś, kto wrzuca jeden lub dwa dokumenty do systemu — prawdopodobnie ma więcej doświadczenia niż dochodu. Krzywa wypłat zdecydowanie faworyzuje wkładców, którzy działają na dużą skalę, z uporządkowanymi danymi, w formatach, które model aktywnie potrzebuje. Jest sufit na pasywnym uczestnictwie, którego większość ludzi nie osiągnie.
Może to i w porządku. Większość wczesnej infrastruktury ma taki kształt. Ale warto wiedzieć, że "możesz zarabiać na swoich danych" i "wkrótce będziesz zarabiać znacząco na swoich danych" to wciąż dość różne zdania.