
@OpenLedger Złapał moją uwagę z powodu, który zajęło mi żenująco długi czas, aby w pełni wyartykułować. Wciąż powtarzałem sobie, że chodzi o tokenomikę, czy kąt AI, a może po prostu ogólną ciekawość. Ale kiedy usiadłem i naprawdę o tym pomyślałem, prawdziwy haczyk stanowiło pytanie, które projekt zmusza cię do skonfrontowania: kto tak naprawdę posiada twoje dane, a co ważniejsze, kto przechwytuje wartość, którą generują? Te dwie rzeczy zostały cicho oddzielone w erze AI, a większość ludzi, w tym ja, nie zauważyła tego aż do niedawna.
Własność danych brzmi jak rozwiązany problem na powierzchni. Ludzie kiwają głowami, gdy to się porusza, zakładają, że ramy prawne się tym zajmują i przechodzą dalej. Ja też tak robiłem przez długi czas. To właśnie przechodzenie przez dokumentację OpenLedger sprawiło, że to dla mnie kliknęło w sposób, w jaki nigdy wcześniej. Własność prawna i korzyść ekonomiczna to zupełnie różne rzeczy. Możesz posiadać swoje dane w sensie technicznym, podczas gdy każdy dolar wartości, który generuje, płynie gdzie indziej. W kontekście systemów AI, to nie jest przypadek marginalny. To jest domyślny wynik. Każdy oznaczony zestaw danych, każda kolekcja wiedzy z danej dziedziny, każda skuratowana historia interakcji trafia do modeli, które są wdrażane na dużą skalę, a ludzie, którzy dostarczali ten surowy materiał, niemal nigdy nie widzą zwrotu proporcjonalnego do tego, co wnieśli.
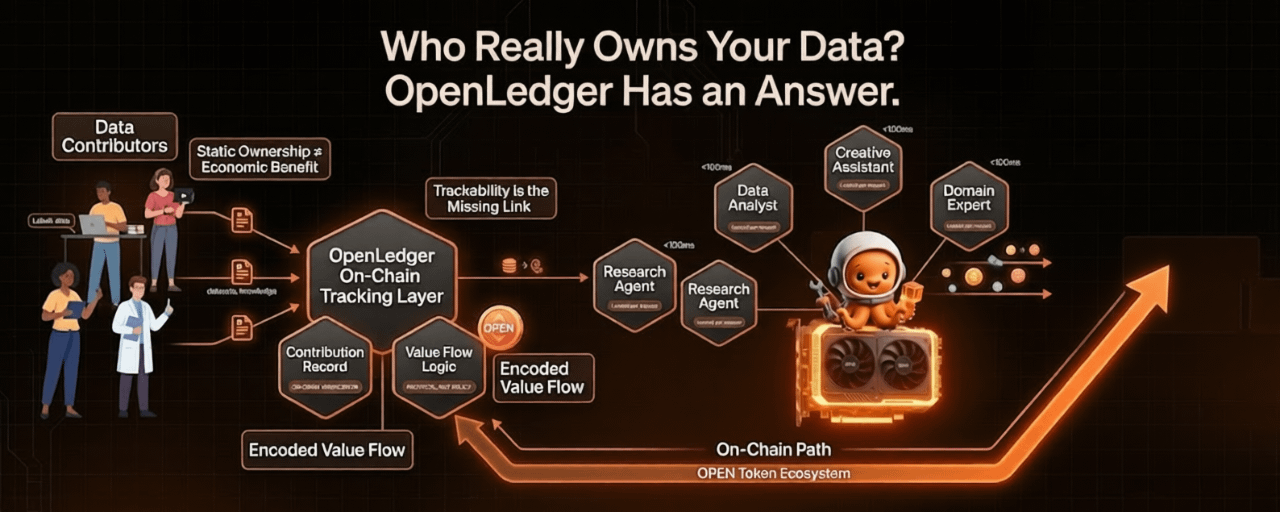
OpenLedger przedstawia to lepiej niż widziałem gdziekolwiek indziej - problem nie dotyczy własności, ale możliwości śledzenia. Wartość znika w górę rzeki. Płynie do tego, kto kontroluje model, a dalej w górę rzeki do tego, kto kontroluje infrastrukturę, na której model działa. W momencie, gdy nagrody ekonomiczne są dystrybuowane, pierwotni dostawcy są na tyle daleko od procesu, że ich rola stała się niewidoczna. To nie jest przypadek ani nadzór. To naturalny rezultat systemu, w którym dane nie mają niezawodnego mechanizmu do śledzenia swojego wkładu w tworzenie wartości w dół rzeki. Gdy nie możesz zmierzyć wkładu, nie możesz go wycenić. Gdy nie możesz go wycenić, nie możesz za niego wynagrodzić. Nie wiem, dlaczego to nie denerwuje więcej ludzi.
To jest konkretna luka, na którą OpenLedger zwraca uwagę. Podejście koncentruje się na budowaniu weryfikowalnej warstwy śledzenia pomiędzy dostawcami danych, twórcami modeli a operatorami agentów, gdzie wkład jest rejestrowany na łańcuchu, a wynagrodzenie podąża za rzeczywistym użyciem, a nie za tym, kto akurat kontroluje otaczającą infrastrukturę. Token OPEN jest jednostką, przez którą ta ekonomiczna logika działa. Nie jest ozdobny. To mechanizm, który umożliwia bezzaufane wynagradzanie uczestników bez potrzeby centralnej władzy do zarządzania dystrybucją. Będę szczery, kiedy pierwszy raz to przeczytałem, szukałem haczyka. Na razie go nie znalazłem.
To, co uważam za najciekawsze w ujęciu OpenLedger, to jak całkowicie redefiniuje pytanie o własność. Statyczna własność - kto ma prawa do pliku lub zbioru danych - jest niemalże bez znaczenia. Pytanie, które naprawdę ma znaczenie, to kto korzysta, gdy dane coś robią. Gdy trenują model. Gdy ten model jest wywoływany tysiące razy. Gdy wyniki tego modelu tworzą wartość dla kogoś poniżej, kto nigdy nie miał kontaktu z pierwotnym dostawcą. OpenLedger buduje infrastrukturę do śledzenia całego tego łańcucha i zapewnienia, że wartość przepływa z powrotem przez niego proporcjonalnie. To znacznie trudniejszy problem niż deklaracja własności, a to problem, który ma prawdziwe konsekwencje ekonomiczne w skali.
To właśnie dlatego podejście OpenLedger oparte na łańcuchu ma większe znaczenie, niż może się wydawać na początku. Centralna platforma może składać te same obietnice: sprawiedliwe wynagrodzenie, przejrzyste śledzenie użycia, proporcjonalne nagrody. Ale obietnica od centralnego podmiotu jest trwała tylko tak długo, jak trwałe są zachęty tych, którzy ją prowadzą. Gdy zmieniają się warunki biznesowe, gdy presje wzrostowe zmieniają priorytety, gdy pojawia się model bardziej zyskowny, te obietnice są cicho modyfikowane. OpenLedger koduje zasady wynagradzania bezpośrednio w protokole, a nie w dokumencie polityki. Warunki nie istnieją gdzieś, gdzie można je zaktualizować z trzydziestodniowym wyprzedzeniem. Żyją w logice systemu, egzekwowane przez łańcuch, a nie przez dobrą wolę.
Dla każdego, kto poważnie myśli o dostarczaniu wartościowych danych lub modeli do ekosystemu OpenLedger na długi horyzont czasowy, ta różnica to różnica między uczestnictwem w czymś a byciem przez to wyzyskiwanym. Myślę o tym więcej, niż prawdopodobnie powinienem. Ale im dłużej się nad tym zastanawiam, tym bardziej wydaje się to być najważniejszą decyzją projektową, jaką podjęto...
Szerszy kontekst ma również znaczenie. Przemysł AI jest na wczesnym etapie tego, co w końcu zostanie uznane za jedno z największych skoncentrowań wartości w historii gospodarczej - konwersja ludzkiej wiedzy i danych na zautomatyzowane systemy, które przechwytują większość wynikowej wartości dla niewielkiej liczby scentralizowanych graczy. OpenLedger buduje infrastrukturę, która mogłaby znacząco przekierować część tej wartości z powrotem do ludzi, którzy rzeczywiście dostarczali dane. Czy to w pełni się powiedzie, nikt nie może powiedzieć z pewnością w tej chwili. Ale architektura jest poważna, a problem, który jest celem, jest realny.
Własność danych w erze AI nie jest rozwiązanym problemem. W większości rozmów, które mają miejsce w tej chwili, jest to ledwie dobrze zdefiniowany problem. To, co robi OpenLedger - budowanie infrastruktury ekonomicznej, aby uczynić własność znaczącą, a nie symboliczną, jest dokładnie tym rodzajem fundamentalnej pracy, która wydaje się oczywista w retrospektywie, gdy już istnieje. Nie spodziewałem się, że tak bardzo się tym zainteresuję, gdy po raz pierwszy zacząłem to badać. Oto jesteśmy.
\u003cm-6/\u003e
\u003cc-41/\u003e
\u003ct-3/\u003e
