I will be honest, Everyone notices the two ends.
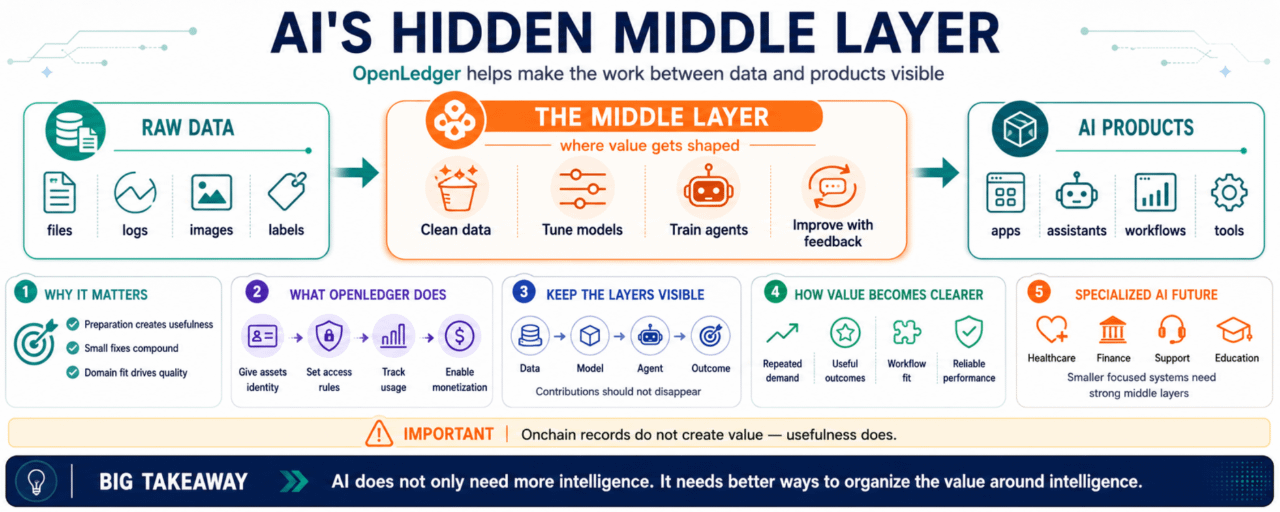
On one side, there is raw data.
Files, text, records, images, logs, conversations, labels, signals.
On the other side, there are finished AI products.
Apps, agents, assistants, workflows, dashboards, tools.
The middle is less visible.
That is where data gets cleaned.
Where models get shaped.
Where agents learn a process.
Where feedback becomes improvement.
Where domain knowledge becomes something a machine can actually use.
And honestly, that middle layer may be where a lot of the real value sits.
@OpenLedger becomes interesting when seen from this angle.
Not only as an AI blockchain. Not only as a place for data, models, and agents to be monetized. More as a system trying to give structure to the part of AI that usually disappears between input and output.
Because raw data by itself is often not enough.
A company may have years of support tickets, but that does not automatically make it useful for AI. Someone has to clean it. Someone has to remove noise. Someone has to organize it in a way that makes sense. Someone has to connect it to a model or workflow.
The value is not just in the data.
It is in the preparation.
The same thing happens with models.
A base model can do many things, but it may not understand a narrow task well. So a team fine-tunes it. Tests it. Corrects it. Adds examples. Connects it to tools. Builds a process around it. Slowly, the model becomes useful for one specific job. $PLAY
That work is not always visible from the outside.
But without it, the final product may not work.
That is where things get interesting.
AI value is not created in one clean moment. It builds up through small adjustments. A better dataset. A cleaner label. A sharper model. A more reliable agent. A workflow that removes friction. A feedback loop that keeps improving results.
These are not dramatic things. They are quiet things.
But quiet things compound.
#OpenLedger seems to be asking whether those pieces can become recognizable assets instead of hidden steps. If a prepared dataset improves a model, maybe that contribution should be traceable. If a specialized model powers an agent, maybe its usage should not vanish. If an agent keeps completing useful tasks, maybe it should have its own economic record.
That is a different way to think about liquidity.
Liquidity is not only about trading something. Sometimes it is about making something that was previously invisible easier to use, price, and reward. $PORTAL
And the middle layer of AI has a visibility problem.
People see the final tool and assume the value sits there. But often, the tool is only good because of the work underneath it. The cleaned data. The narrow training. The rules. The examples. The human corrections. The agent behavior that was refined over time.
You can usually tell when something has gone through that middle layer because it feels less generic.
It understands the task.
It makes fewer strange mistakes.
It fits the workflow.
It responds in the right context.
It does not need constant babysitting.
That kind of usefulness rarely appears by accident.
So the question changes.
Instead of asking, “Who owns the final AI product?”
Maybe we also need to ask, “Who shaped the intelligence that made the product work?”
That is a more careful question.
OpenLedger’s focus on data, models, and agents sits right there. It is not only about the asset itself, but about the connection between assets. The data that shaped the model. The model that powered the agent. The agent that created the outcome. The outcome that generated value. #StrategyHintsNewBTCBuy
A normal system may flatten all of that into one product.
A ledger can at least try to keep the layers visible.
Not perfectly.
Not without trade-offs.
But better than pretending the layers do not exist.
This matters because AI is becoming more specialized.
The next useful systems may not always be the biggest general models. They may be smaller combinations of good data, focused models, and agents trained around specific workflows. Healthcare workflows. Finance research. Customer support. Education. Logistics. Compliance. Developer tools.
In each case, the middle layer matters.
The public may only see the assistant or the agent. But builders know the real work is making the system fit the environment.
OpenLedger seems to be building for that reality.
A place where the parts behind AI can carry identity, access rules, and monetization paths. A place where contributors are not only rewarded at the final product level, but potentially through the pieces they help create.
Of course, this only works if the assets are actually useful.
A bad dataset does not become valuable because it is onchain.
A weak model does not become important because it has a record.
An agent that does not solve anything will not matter just because it can be tracked.
The market still has to judge usefulness.
But that may be the point.
If usage can be recorded, then value can slowly become clearer. Not through loud claims, but through repeated demand.
After a while, it becomes obvious that AI does not only need more intelligence. It needs better ways to organize the value around intelligence.
OpenLedger is one attempt to organize that middle layer.
The part between raw material and finished product.
The part where many small improvements turn into something that finally works.
@OpenLedger #OpenLedger $OPEN
Artykuł
There is a middle layer in AI that people do not talk about enough.
Zastrzeżenie: zawiera opinie osób trzecich. To nie jest porada. Binance AI może być używane bez gwarancji. Zobacz Regulamin