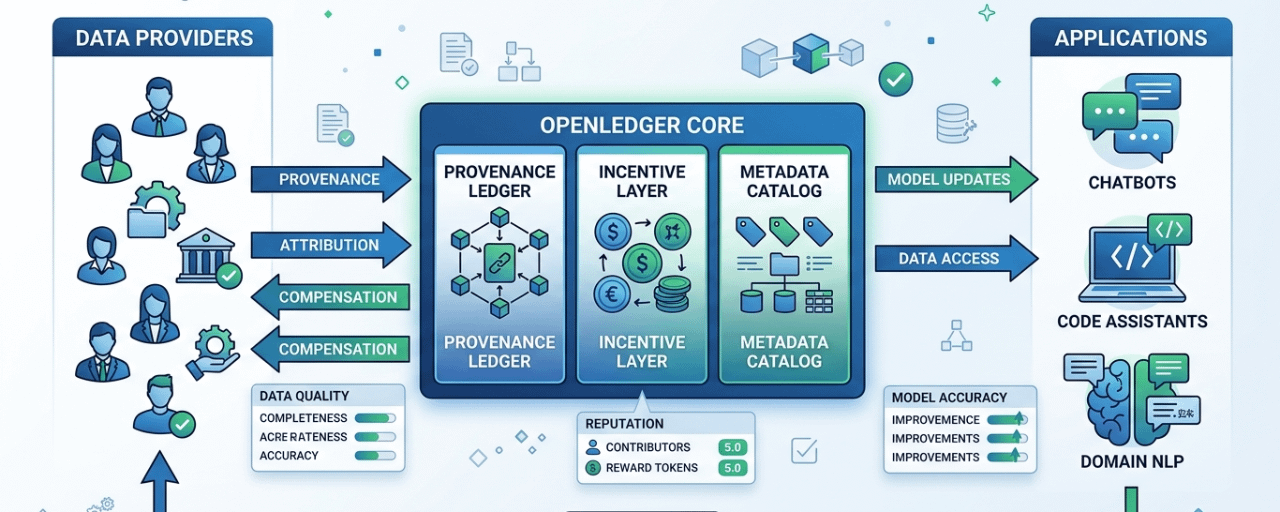

$OPEN Artificial intelligence is moving quickly, but one thing I keep noticing is that the real value of AI does not come from the model alone. It comes from how the model is applied to solve real problems. That is one reason why OpenLedger has caught my attention. Instead of focusing only on AI as a technology, it appears to be creating an ecosystem that can support practical applications such as chatbots, code assistants, and domain-specific natural language processing solutions.
When I think about chatbots, I see a technology that has already become part of everyday life. People use chatbots for customer support, education, shopping assistance, research, and many other tasks. The challenge is that useful chatbots require high-quality data and reliable intelligence behind the scenes. OpenLedger's approach seems interesting because it recognizes that AI systems are only as strong as the data and infrastructure that support them.
What stands out to me is the possibility of creating more transparent AI systems. In many cases, users interact with a chatbot without knowing where the underlying knowledge originated. The answers may be helpful, but the contributions of data providers remain invisible. OpenLedger appears to be exploring ways to make those contributions more visible and measurable, which could help create a healthier AI ecosystem.
Another area that interests me is code assistants. Software development is becoming increasingly dependent on AI-powered tools. Developers now use AI to generate code, review logic, identify bugs, and speed up workflows. While these systems can significantly improve productivity, they still rely heavily on large amounts of training data. The quality of that data often determines how useful the assistant becomes.
I believe code assistants represent one of the clearest examples of AI creating practical value. They save time, reduce repetitive work, and help developers focus on solving more complex problems. If platforms like OpenLedger can improve the way data contributors are recognized and rewarded, it could encourage the creation of even better datasets for future AI development.
What makes this particularly important is that software development continues to evolve. New programming languages, frameworks, and tools appear every year. AI systems need fresh and relevant information to remain effective. A network that encourages continuous data contributions may help ensure that AI assistants stay current rather than becoming outdated.
Beyond general-purpose AI, I find domain-specific NLP solutions especially interesting. Many industries have unique terminology, workflows, and knowledge requirements. Healthcare, finance, law, logistics, and research all use specialized language that general AI models may not fully understand. Domain-specific NLP aims to solve that challenge by training systems on focused datasets.
In my view, this is where some of the biggest opportunities exist. A financial analyst does not need a chatbot that knows a little about everything. They need an assistant that understands market terminology, regulations, reports, and industry-specific concepts. The same applies to doctors, lawyers, engineers, and many other professionals.
The challenge is that specialized datasets are often difficult to obtain. Organizations may be reluctant to share valuable information because they are uncertain about how it will be used or whether they will receive fair compensation. This creates a gap between available knowledge and AI development. OpenLedger seems to be exploring ways to address that gap by building incentives around data contributions.
I think trust is becoming one of the most important issues in artificial intelligence. Companies want to benefit from AI, but they also want visibility into how their data is used. Without trust, many valuable datasets remain locked away. Any platform that can improve transparency and accountability may have an advantage in attracting contributors.
Another reason I find this model compelling is that it aligns incentives more closely. Traditionally, a few large organizations collect data, train models, and capture most of the value. OpenLedger appears to be exploring a structure where contributors can play a more active role in the AI economy. Whether that model reaches its full potential remains to be seen, but the idea itself is worth paying attention to.
I also think this approach could help improve AI quality over time. Better incentives can encourage higher-quality data submissions. Higher-quality data can lead to better-performing models. Better models can support stronger applications. This creates a feedback loop that benefits developers, businesses, and end users alike.
From a broader perspective, AI is becoming part of nearly every industry. Chatbots are changing customer interactions. Code assistants are reshaping software development. Domain-specific NLP is helping professionals work more efficiently. These applications are no longer experimental concepts; they are becoming everyday tools.
What interests me about #OpenLedger is that it focuses on a layer of the AI stack that often receives less attention. People usually talk about models, applications, and user experiences. Far fewer discussions focus on how data is sourced, tracked, valued, and rewarded. Yet that foundation may ultimately determine how sustainable the AI ecosystem becomes.
@OpenLedger is worth watching because it addresses questions that will become increasingly important as AI adoption grows. Chatbots, code assistants, and specialized NLP solutions all depend on quality data. If the industry can create better systems for recognizing and rewarding the people and organizations that contribute that data, the entire AI ecosystem may become stronger, more transparent, and more valuable for everyone involved.