Patrzyłem znowu na @OpenLedger . Szczególnie na ten koncept, wokół którego ciągle wszystko się kręci: pochodzenie danych. Idea, że każdy kawałek danych treningowych użytych w modelu AI powinien mieć możliwe do śledzenia pochodzenie. Że wkładnicy powinni być uznawani, wynagradzani i weryfikowalni on-chain.
Brzmi czysto. Brzmi prawie oczywiście, gdy to mówisz na głos.
Ale potem zacząłem myśleć — chwila, co właściwie znaczy "on-chain" w tym kontekście?
Bo oto rzecz, która mnie zbiła z tropu. Kiedy OpenLedger mówi o pochodzeniu, opisują przypisanie. Kto dostarczył jakie dane. Ale przypisanie i weryfikacja to nie to samo. Ciągle je myliłem i myślę, że większość ludzi też.
Atrybucja to twierdzenie. Weryfikacja to dowód.
Jeśli powiem ci, że przyczyniłem się do modelu 10,000 wierszy oznaczonych danych finansowych, to jest to atrybucja. Jeśli istnieje mechanizm, który niezależnie potwierdza jakość, unikalność i faktyczne wykorzystanie tych wierszy w treningu modelu — to jest to weryfikacja. Jedno to zapis. Drugie to dowód.
Model Proof of Attribution OpenLedger rejestruje to pierwsze. To drugie... wciąż jest dla mnie nieco mętne.
Szukam, gdzie dokładnie odbywa się walidacja. System przyznaje nagrody dla wkładów na podstawie wyników jakości danych. Ale te wyniki — o ile mogę śledzić — pochodzą z obliczeń off-chain. Liczba ląduje on-chain, ale proces generujący tę liczbę nie. Co oznacza, że to, co jest rejestrowane jako pochodzenie, to tak naprawdę tylko zweryfikowany paragon za nieweryfikowany proces.
I nie mówię, że to jest oszustwo. Mówię, że to jest specyficzny wybór projektowy, który większość ludzi czytających dokumentację techniczną prawdopodobnie pomija. Przejrzystość reklamowana jest prawdziwa, ale dotyczy wyników, a nie wejść.
Oto część, która mnie bardziej niepokoi.
Pochodzenie danych jako koncepcja zostało zapożyczone z badań naukowych. W tym kontekście oznacza to, że możesz prześledzić zestaw danych przez każdą transformację, którą przeszedł — czyszczenie, etykietowanie, łączenie — z oryginalnym źródłem nienaruszonym. Łańcuch dowodowy, zasadniczo. OpenLedger używa tego terminu w węższym sensie: kto przesłał dane i czy przeszedł przez filtr jakości.
To nie jest błędne. Ale to również nie jest to, co ktoś z doświadczeniem w naukach danych uznałby za pełne pochodzenie. A luka między tymi dwoma definicjami to miejsce, gdzie zaufanie jest implicitnie lokowane.
Pomyślałem o tym więcej i myślę, że uczciwa wersja tego, co OpenLedger buduje, to księga wkładów z stakingiem reputacji, a nie pełny system pochodzenia danych. Co wciąż jest użyteczne. Wciąż potencjalnie cenne dla rozwoju AI. Ale to coś innego niż to, co sugeruje słowo "pochodzenie".
Czy ta różnica ma znaczenie dla przeciętnej osoby trzymającej $OPEN — Nie wiem. Cena tokena nie rusza się na podstawie definicyjnych niuansów. Ale prawdopodobnie ma to znaczenie, gdy przedsiębiorcy zaczynają przeprowadzać due diligence na modelach AI trenowanych w tym systemie i zadają dokładnie te pytania.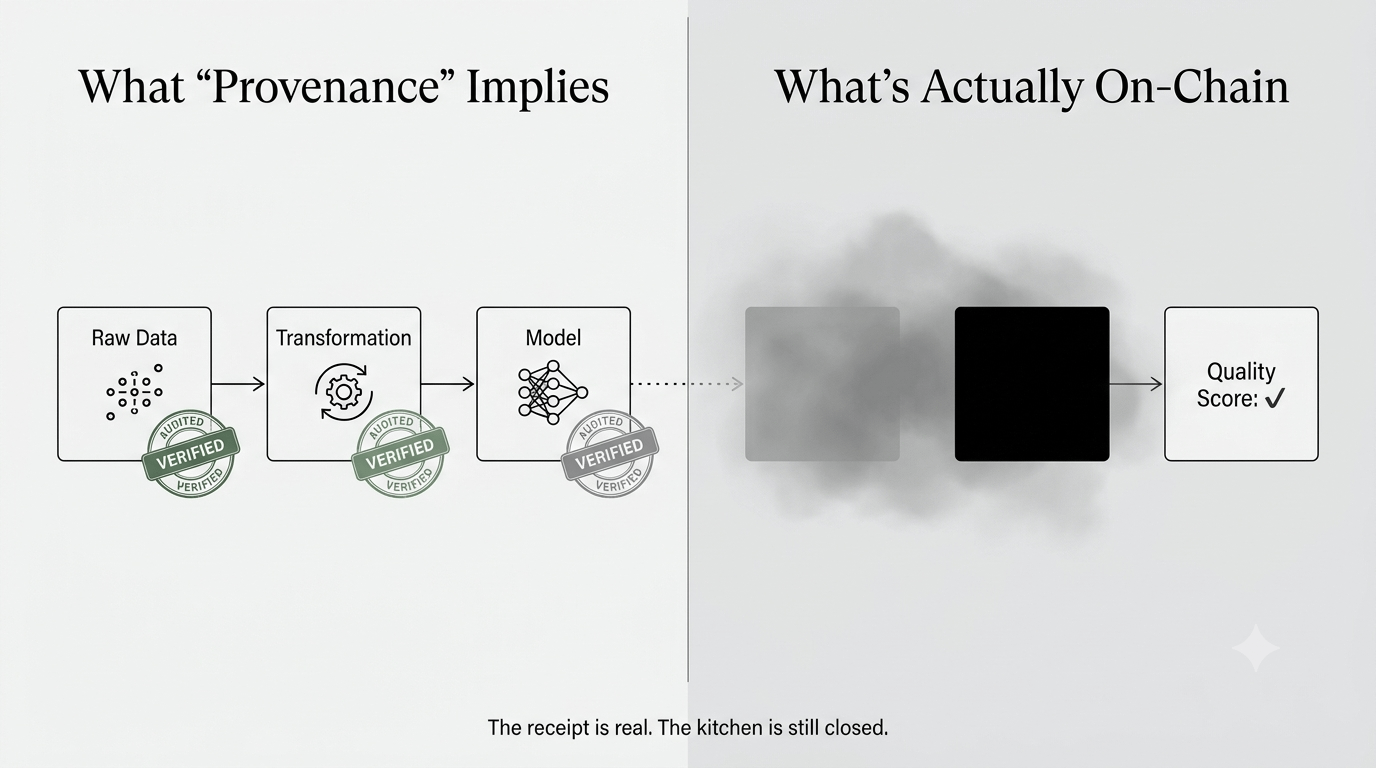
Nie jestem do końca przekonany, że to wytrzyma poważną kontrolę ze strony instytucjonalnych nabywców danych. Oferta dla nich brzmi: korzystaj z modeli AI z weryfikowalnymi, etycznie pozyskiwanymi danymi do treningu. Ale jak weryfikowalnymi? Przez własny system ocen OpenLedger? To nie jest weryfikacja przez stronę trzecią. To dostawca mówiący, że jego łańcuch dostaw jest czysty.