Rynek był dzisiaj wolny. Taki wolny, że zamykasz wykresy, otwierasz trzy zakładki, których nie zamierzałeś, i kończysz na czytaniu czegoś, czego nie planowałeś.
Tak właśnie trafiłem na OpenLedger. Ktoś wrzucił wzmiankę $OPEN w grupie na Telegramie, do której ledwo zaglądam, bez żadnego kontekstu. Zero wyjaśnienia, zero celu cenowego, tylko link. I z jakiegoś powodu kliknąłem.
Nie spodziewałem się wiele.
Potem coś mnie zaskoczyło. Nie technologia. Nie tokenomia. Coś bardziej podstawowego — i szczerze mówiąc, trochę niewygodnego do przetrawienia.
Internet generuje dane o nas od trzydziestu lat. Nasze wzorce wyszukiwania, nasze nawyki czytania, nasze mikro-decyzje. Wszystko to wpływa w górę — do platform, do trenerów modeli, do reklamodawców. Wiedzieliśmy o tym. Akceptowaliśmy to. Większość ludzi pogodziła się z byciem produktem.
Ale oto co mi naprawdę kliknęło:
Nie tylko oddaliśmy nasze dane. Oddaliśmy surowy materiał, który trenował systemy AI warte setki miliardów dolarów. I nie dostaliśmy za to nic.
Nie udział. Nie token. Nawet nie dziękuję.
OpenLedger buduje coś, co przewraca to konkretne założenie. Pomysł polega na tym, że dane mają pochodzenie — co oznacza: pochodzą skądś, od kogoś — a ta osoba powinna mieć pewne roszczenie do wartości, którą tworzy. $OPEN to mechanizm, który budują, aby uczynić tę wymianę realną.
Myślałem, że to tylko kolejna prezentacja monetyzacji danych. To nie do końca to.
Co większość ludzi zakłada: dane to coś, co chronisz (gra prywatności) lub sprzedajesz (centralny broker). Binarne. Albo je bronisz, albo ktoś je kupuje hurtowo, nie widząc ani grosza.
Na co wydaje się wskazywać OpenLedger: trzecia ścieżka. Dane, które niosą przypisanie przez cały proces. Jeśli twoje treści, twoje interakcje, twoje wzorce zachowań są używane do trenowania modelu — istnieje księga, która to śledzi. A $OPEN ma siedzieć na warstwie rozliczeniowej tej wymiany.
Mniej "sprzedawaj swoje dane raz," bardziej "twoje dane wciąż pracują i masz pozycję w tym, co produkują."
To jest część, która mnie zatrzymała.
Ale oto część, która mnie niepokoi.
Przypisanie w treningu AI jest szczerze nie rozwiązane. Jak, badacze wciąż się spierają, jak zmierzyć indywidualny wkład danych w wyniki modelu. To nie jest czysty problem. Jeśli OpenLedger obiecuje czyste pochodzenie i uczciwe rozliczenie za dane treningowe — chcę zrozumieć, jak to rzeczywiście robią, nie machając rękami w stronę blockchaina.
Bo "twoje dane na łańcuchu" i "twoje dane właściwie przypisane w treningu modelu" to zupełnie różne rzeczy. Jedno to zapis. Drugie to problem pomiarowy, którego laboratoria na granicy jeszcze nie rozwiązały.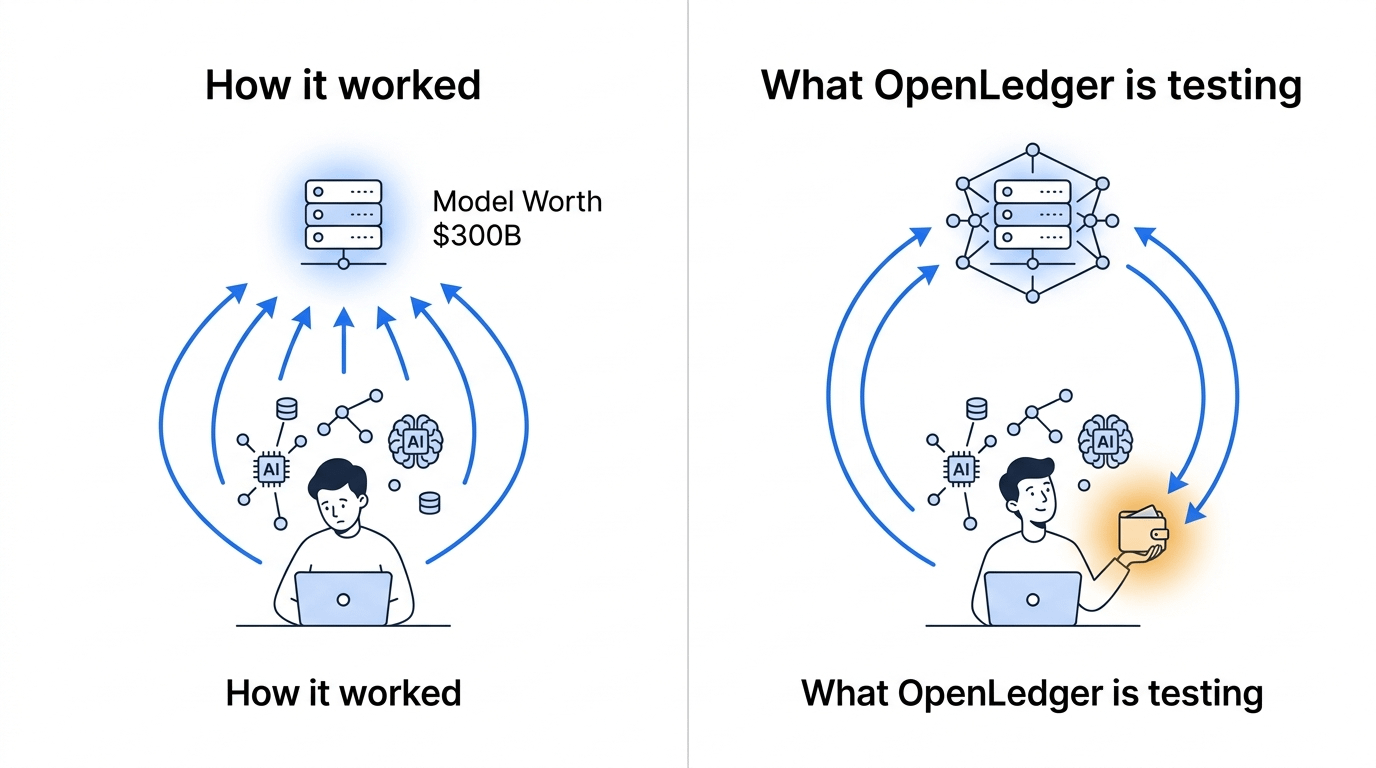
Nie mówię, że nie mają odpowiedzi. Po prostu nie widziałem tego wyjaśnionego w sposób, który by mnie zadowolił. I ta luka bardziej mnie niepokoi, niż się spodziewałem.
Inna rzecz — adopcja. Żeby to działało, kto trenuje modele, musi dbać o pochodzenie. Na razie większość nie dba. Zachęta do pozyskiwania czystych, przypisanych danych istnieje tylko wtedy, gdy regulacje to wymuszają, lub gdy dane nieprzypisane stają się prawnie ryzykowne. Żadne z tych nie jest gwarantowane.
Więc timing tutaj zależy od regulacyjnego otoczenia, które może, ale nie musi się zmaterializować. To prawdziwe ryzyko.
Mimo to — wciąż o tym myślę.
Nie przez ruch cenowy (w zasadzie nie ma o czym mówić). Ale dlatego, że podstawowe założenie jest jedną z tych rzeczy, które, gdy już je zobaczysz, nie możesz ich potem nie widzieć. Gospodarka AI jest budowana na danych generowanych przez ludzi, a ludzie nie są przy stole.
To nie utrzyma się wiecznie. Coś się zmieni — czy to regulacje, presja publiczna, dynamika konkurencji, czy coś innego. Pytanie brzmi, czy OPEN jest wystarczająco wcześnie, aby być w odpowiedniej pozycji na ten zwrot, czy tak wcześnie, że to nie ma znaczenia.
Szczerze mówiąc, jeszcze nie wiem.
Przyjaciel napisał do mnie, gdy pisałem to, pytając, co moim zdaniem warto obserwować w tym tygodniu. Powiedziałem mu, że przez ostatnie dwie godziny czytałem o przypisywaniu danych i nie mogłem w pełni wyjaśnić dlaczego.
Powiedział, że to była najnudniejsza rzecz, jaką kiedykolwiek słyszał.
Może. Rynek wciąż cichy. Prawdopodobnie skończę w kolejnej dziurze jutro.