Wziąłem dzisiaj pół dnia wolnego. Rynki były w porządku, nic nie wymagało mojej uwagi, więc po prostu buszowałem online przez chwilę. Zakończyło się na jednym z tych króliczych nor, które zaczyna się od artykułu i kończy w miejscu, którego się nie spodziewałeś.
Czytałem o "problemie danych" wartym 500 miliardów dolarów, o którym ciągle wspomina OpenLedger. $OPEN . Ich propozycja jest taka, że wysokowartościowe zestawy danych są zamknięte w instytucjach i firmach, niezmienione na pieniądze, bez rekompensaty. Kiwałem głową, bo słyszałem tę narrację wystarczająco wiele razy, żeby ją przyswoić bez większego zastanowienia.
Potem coś się zmieniło.
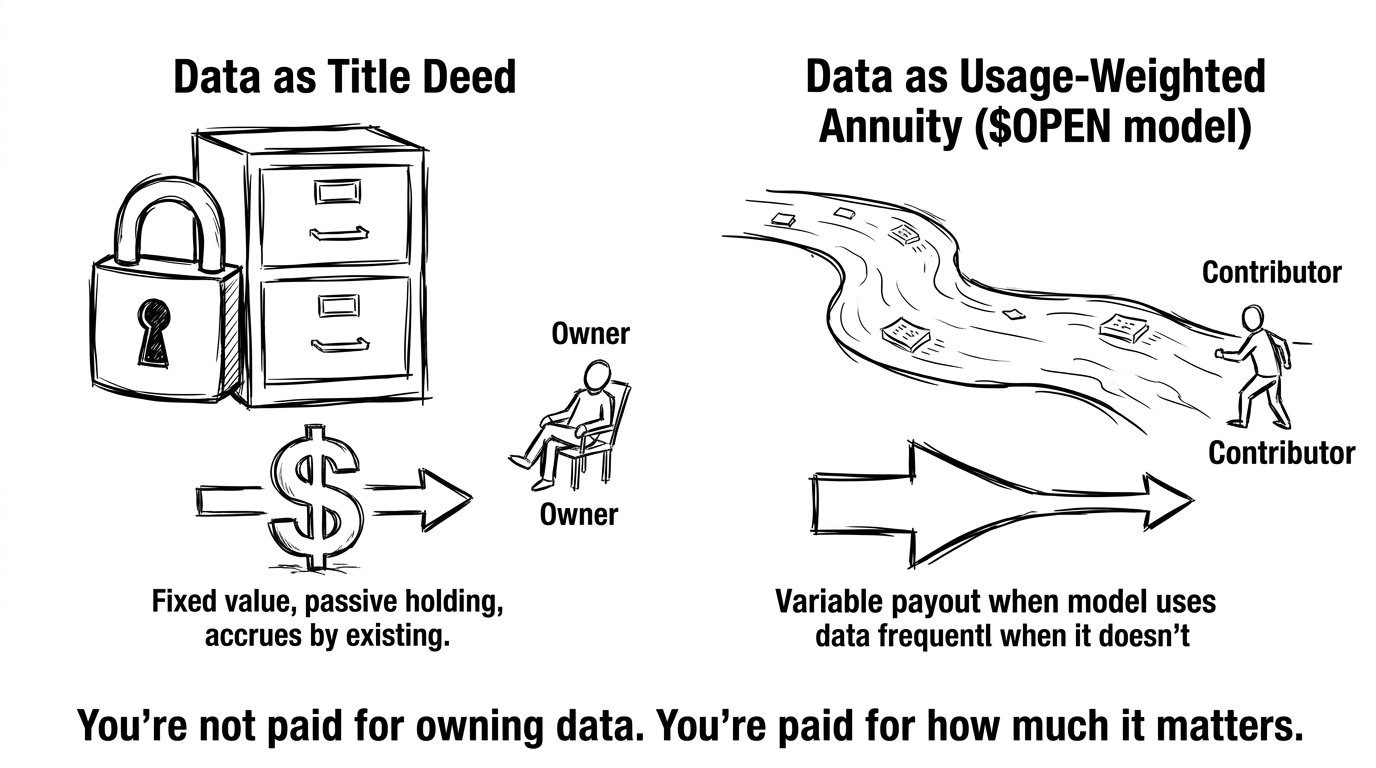
Założenie, które tkwi w prawie każdej rozmowie o "własności danych", jest takie, że dane są jak nieruchomości lub złoto — coś, co posiadasz, coś, co ma wartość, coś, co zyskuje na wartości tylko przez istnienie. I tak przyszłość własności danych, w tym ujęciu, jest zasadniczo: daj ludziom cyfrowy akt własności ich danych i pozwól im zbierać czynsz.
Ale to nie jest do końca tak, jak działa dane w AI. I myślę, że OpenLedger — cicho, może bez pełnego wyjawienia — buduje coś, co całkowicie łamie ten model.
Dane same w sobie nie mają wartości. Wartość danych jest proporcjonalna do tego, jak bardzo wpływają na to, co model produkuje. Zbiór danych w Datanet na OpenLedger, do którego nigdy nie zapytuje żaden model, jest wart zero, niezależnie od tego, jak dobre lub rzadkie są te dane. System Proof of Attribution nie płaci za istnienie danych. Płaci za wpływ danych — konkretnie, jak bardzo dany kawałek danych ukształtował wynik inferencji. To zupełnie inna klasa aktywów.
Pomyślałem o tym przez chwilę. W tradycyjnej własności danych miałbyś coś takiego jak patent lub licencję — stała wartość, przenośna, gromadząca pasywnie. To, co naprawdę buduje OpenLedger, jest bliższe zmiennej rencie powiązanej z użyciem modelu. Nie dostajesz zapłaty za trzymanie aktywa. Dostajesz zapłatę za to, jak często i jak znacząco aktywo jest konsumowane. Aktualizacja silnika atrybucji z stycznia 2026 — utrzymanie tych połączeń nagród w trakcie aktualizacji i dostrajania modeli — to nie tylko techniczna łatka. To utrzymanie mechanizmu wypłat, gdy wzorce konsumpcji aktywa się rozwijają.
To przekształcenie ma znaczenie, ponieważ zmienia, kto korzysta i kiedy.
Pod modelem "dane jako akt własności", największymi zwycięzcami są ci, którzy wcześniej zgromadzili najwięcej danych. Pod modelem "dane jako renta ważona użyciem", największymi zwycięzcami są ci, którzy wnieśli najbardziej wpływowe dane — co jest znacznie trudniejsze do przewidzenia z góry i znacznie bardziej specyficzne dla domeny. Rzadki zbiór danych medycznych o wąskim zastosowaniu jest wart mniej niż wysokiej jakości ogólny zbiór danych, który jest wywoływany miliony razy. To, co jest rzadkie, to nie dane. To wpływ.
Ale oto, co naprawdę budzi moją wątpliwość.
Nagrody oparte na wpływie brzmią elegancko, ale są niezwykle trudne do weryfikacji sprawiedliwie w skali, szczególnie gdy modele stają się większe i bardziej złożone. Matematyka atrybucji działa rozsądnie dla mniejszych, wyspecjalizowanych modeli. W przypadku dużych modeli językowych to wciąż przybliżenie — dopasowywanie tablic suffix, oszacowania wpływu oparte na gradientach. Obliczenia nagród są probabilistyczne, a nie dokładne. A jeśli kiedykolwiek zacznie się spór o wyniki wpływu uczestników, lub metodologia się zmieni, lub aktualizacja modelu subtelnie zmieni, które dane są uznawane — to już nie jest problem czystego tytułu własności. To trwający spór o wycenę, bez łatwego mechanizmu rozwiązania.
Przyszłość własności danych, którą buduje OpenLedger, jest realna i naprawdę interesująca. Czy "dane jako wpływ" to stabilna, audytowalna, skalowalna klasa aktywów, to pytanie, na które nie uzyskamy odpowiedzi, dopóki system nie będzie pod prawdziwym obciążeniem produkcyjnym.
W każdym razie. Jeszcze nie ma 15:00, a już zbyt mocno o tym myślałem. Zamykam zakładki.
@OpenLedger #OpenLedger