Przeorganizowywałem pozycje przez cały tydzień — nic dramatycznego, po prostu zaostrzałem sprawy. W końcu miałem dużo wolnego czasu dzisiaj po południu i żadnego realnego powodu, żeby wpatrywać się w ekran, więc zacząłem czytać zamiast tego.
Wciągnęło mnie na rozmowę z deweloperem, który jest jednym z głównych contributorów w OpenLedger. $OPEN . To była głównie techniczna rozmowa i prawie ją odpuściłem, ale jedna linia uderzyła mnie inaczej, niż się spodziewałem. Opisywali system Proof of Attribution i powiedzieli coś w stylu: "Intensywne sesje treningowe odbywają się off-chain dla wydajności. Kluczowe kroki umieszczamy on-chain." Musiałem to przeczytać jeszcze raz.
Ponieważ sposób, w jaki większość ludzi mówi o OpenLedger — w tym samym projekcie — cała prezentacja to przejrzyste przepływy danych AI. Pełna widoczność on-chain. Każdy zestaw danych, każdy krok treningowy, każda inferencja śledzona. To narracja.
Ale to, co jest naprawdę on-chain, to paragon. Nie posiłek.
Rzeczywista praca obliczeniowa — trening modelu, przetwarzanie danych, to wszystko, co wykorzystuje rzeczywiste godziny GPU — odbywa się poza łańcuchem. To, co jest zapisywane w księdze, to metadane. ID współpracowników. Znaczniki czasowe. Parametry dostrajania. Hash tego, co się wydarzyło, a nie samego zdarzenia. Sam proces treningowy jest zaufany, podsumowany, a następnie zakotwiczony.
Myślałem, że to drobna uwaga techniczna. Ale w rzeczywistości to cały model przejrzystości.
I oto dlaczego to ma znaczenie: słowo "przejrzysty" w AI zazwyczaj oznacza, że możesz zobaczyć, co się wydarzyło. To, co OpenLedger naprawdę buduje, to coś nieco innego — możesz zweryfikować, że ktoś twierdzi, iż coś się wydarzyło, a to twierdzenie znajduje się na niezmiennej księdze. To audytowalność, a nie widoczność. Są ze sobą związane, ale naprawdę nie są tym samym.
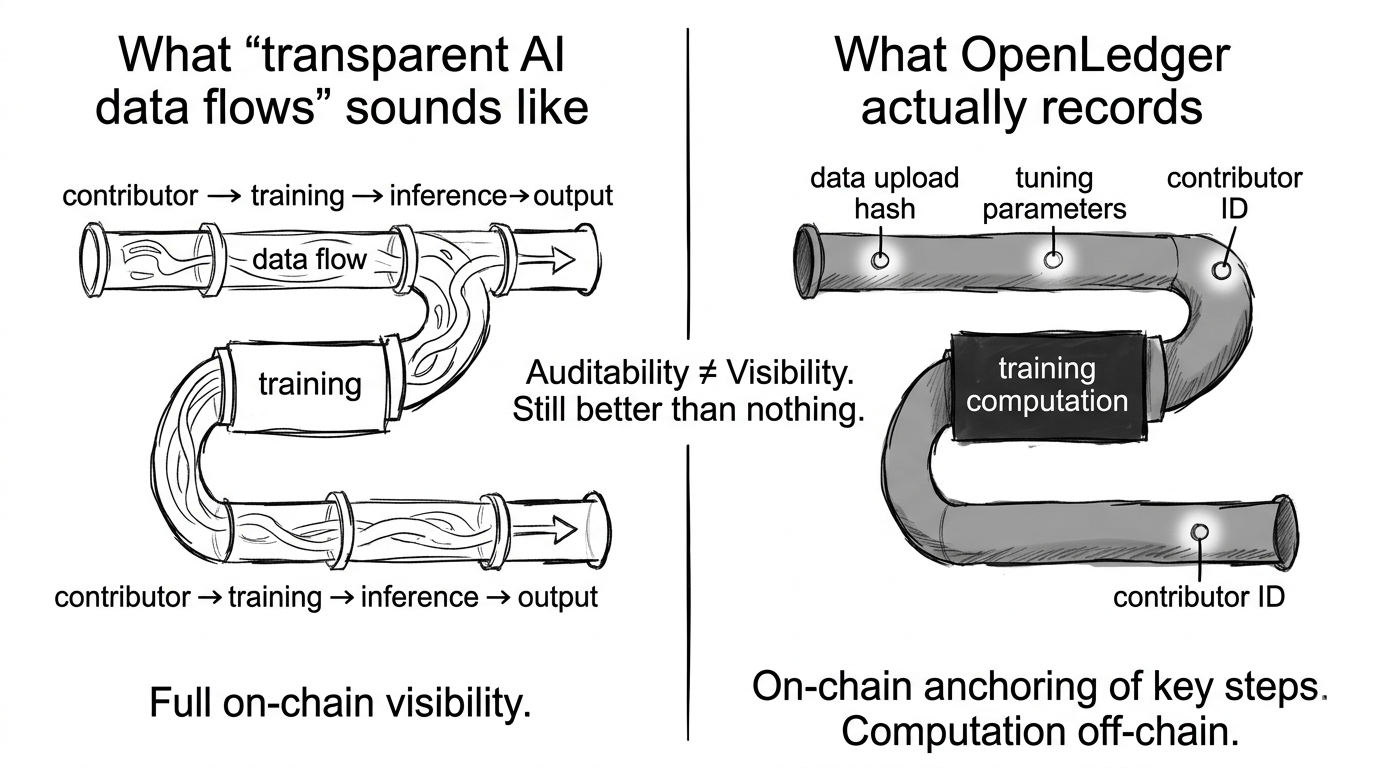
Audytowalność jest wciąż niezwykle cenna. W tej chwili nie ma nic. Brak zapisu, brak śladu, brak sposobu, aby zweryfikować, czy model został wytrenowany na twoich danych czy cudzych, czy ID współpracownika jest dokładne, czy znacznik czasowy jest prawdziwy. Nawet zakotwiczony podsumowanie to ogromna poprawa w porównaniu do nieprzejrzystości. Aktualizacja silnika atrybucji w styczniu 2026 — utrzymanie tych on-chain powiązań z danymi jako modele ewoluują poprzez dostrajanie — to rozwiązuje prawdziwy problem, który inaczej cichutko zrujnowałby płatności dla współpracowników za każdym razem, gdy model byłby aktualizowany.
Ale tu zaczyna mnie to niepokoić.
Audytowalność zakłada, że ufasz procesowi poza łańcuchem, który jest zakotwiczony. Jeśli raport treningowy jest dokładny, zapis on-chain ma sens. Jeśli nie — jeśli ID współpracowników są błędne, jeśli przetwarzanie danych odbyło się inaczej niż opisano, jeśli hash reprezentuje proces, który został zmanipulowany przed zakotwiczeniem — wtedy przejrzysta księga to po prostu bardzo pewne kłamstwo. Blockchain sprawia, że zapisy są trwałe i niezmienne. Nie weryfikuje niezależnie, czy zapis jest dokładny.
To nie jest problem unikalny dla OpenLedger — to problem orakuli, z którym boryka się każdy system blockchain, gdy rzeczywiste dane, które rejestruje, są produkowane poza łańcuchem. Ale warto to jasno powiedzieć: przejrzystość jest tak dobra, jak uczciwość tego, kto wykonuje ciężką obliczeniową pracę poza łańcuchem.
Dla większości zastosowań — modele specyficzne dla dziedziny budowane przez deweloperów, którzy mają coś do stracenia, współpracownicy danych, którzy mogą zweryfikować, że ich własne zgłoszenia są odzwierciedlone — to prawdopodobnie działa dobrze w praktyce. Gdzie robi się trudniej, to jeśli system skalowałby się, aby zaangażować aktorów, którzy mają zachęty do fałszowania pracy poza łańcuchem. W tym momencie "zakotwiczone on-chain" przestaje być tym samym co "zweryfikowane."
Nie mówię, że to łamie projekt. Mówię, że obietnica przejrzystości jest bardziej złożona niż sugeruje to prezentacja.
W każdym razie. Pozycje wyglądają dobrze. Jutrzejszy dzień prawdopodobnie będzie kolejnym dniem bocznym.
@OpenLedger #OpenLedger