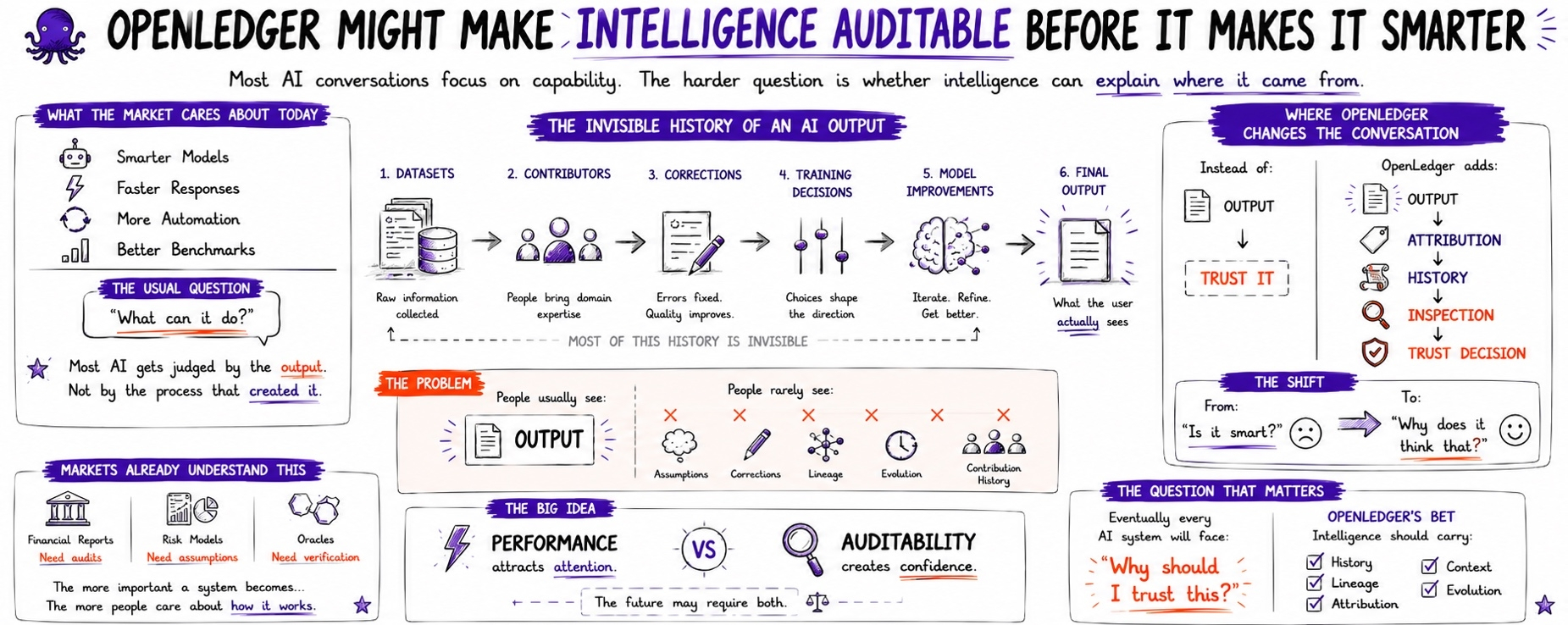
Jedna rzecz, którą zauważyłem na rynkach technologicznych, to że zazwyczaj obsesyjnie skupiają się na możliwościach jako pierwszym.
Czy może zrobić więcej?
Czy może działać szybciej?
Czy może automatyzować lepiej?
Czy może przewyższyć to, co było wcześniej?
To są pytania, które przyciągają uwagę.
Problem polega na tym, że możliwości stają się zaskakująco słabym wskaźnikiem, gdy systemy zaczynają wpływać na decyzje, które naprawdę mają znaczenie.
Nikt nie pyta, czy sprawozdanie finansowe jest inteligentne.
Pytają, czy można go audytować.
Nikt nie pyta, czy raport ryzyka brzmi przekonująco.
Pytają, czy założenia mogą być zbadane.
Nikt nie pyta, czy wróżbita wygląda mądrze.
Pytają, czy dane mogą być zaufane.
W pewnym momencie przejrzystość staje się cenniejsza niż wydajność.
To jest myśl, do której wciąż wracam, gdy patrzę na OpenLedger.
Większość rozmów o AI wciąż kręci się wokół wyników.
Model to wygenerował.
Agent to zakończył.
System osiągnął pewne benchmarki.
W porządku.
Ale wyniki to tylko jedna część historii.
Trudniejsze pytanie to zrozumienie, co stworzyło wynik w pierwszej kolejności.
Ponieważ inteligencja nie pojawia się znikąd.
Przechodzi to w spadku.
Zbiory danych.
Korekcje.
Decyzje contributorów.
Wybory w treningu.
Założenia domeny.
Pętle sprzężenia zwrotnego.
Gdy odpowiedź dociera do użytkownika, większość tej historii zazwyczaj znika.
Wynik pozostaje widoczny.
Ścieżka, która to stworzyła, nie.
To tam OpenLedger wydaje się inne.
Nie dlatego, że próbuje zbudować najmądrzejszy model.
Wiele projektów ściga ten wyścig.
Bardziej interesującą częścią jest to, że traktuje inteligencję jako coś, co powinno nosić zapis tego, jak się rozwijało.
Datanety organizują informacje.
Contribuciści to udoskonalają.
Dowód atrybucji zachowuje linię.
Udoskonalenia modelu stają się śledzone, a nie niewidoczne.
Wynik sprawia, że inteligencja zaczyna wyglądać mniej jak czarna skrzynka, a bardziej jak system z historią.
Ta różnica ma większe znaczenie, niż ludzie zdają sobie sprawę.
Rynki przez dekady uczyły się tej samej lekcji.
Wynik bez kontekstu jest trudny do oceny.
Wynik z kontekstem staje się łatwiejszy do zaufania, kwestionowania, poprawiania lub odrzucania.
To prawda w przypadku firm.
To prawda w systemach finansowych.
To prawda w przypadku infrastruktury.
AI może podążyć tą samą ścieżką.
Ponieważ przyszłym wyzwaniem prawdopodobnie nie jest produkcja inteligencji.
Przyszłym wyzwaniem jest zrozumienie, skąd ta inteligencja się wzięła i czy proces, który za tym stoi, zasługuje na zaufanie.
Ciekawe jest to, że nikt nie ekscytuje się audytowalnością.
To nie jest główna cecha.
To nie jest efektowna prezentacja.
To nie jest coś, o czym ludzie śpieszą się tweetować.
Jednak audytowalność cicho leży u podstaw większości systemów, które przetrwają wystarczająco długo, by miały znaczenie.
Zaufanie zazwyczaj kumuluje się wokół rzeczy, które można sprawdzić.
Nie rzeczy, które mogą tylko podziwiać.
Dlatego myślę, że długoterminowa szansa OpenLedger może nie polegać na uczynieniu inteligencji mądrzejszą.
Może to sprawia, że inteligencja staje się bardziej zrozumiała.
A jeśli AI stanie się coraz bardziej wbudowane w rynki, automatyzację, koordynację i podejmowanie decyzji, to może okazać się, że to jest bardziej wartościowy problem do rozwiązania.
Ponieważ w końcu ktoś zada pytanie, na które sama wydajność nie może odpowiedzieć:
„Dlaczego powinienem temu zaufać?”
Systemy, które potrafią się same wyjaśnić, mogą mieć przewagę nad systemami, które mogą tylko imponować.
