

Kiedy pierwszy raz spojrzałem na OpenLedger Token z tej perspektywy, nie myślałem o wiedzy jako czymś, co mogłoby ulec zużyciu.
Kiedyś traktowałem wiedzę jak czysty aktyw, wewnątrz systemów AI.
Wchodzi raz, często się go używa i w jakiś sposób pozostaje taki sam.
To jest powierzchowne założenie.
Ale im dłużej nad tym siedzę, tym bardziej ten pogląd wydaje się zbyt uporządkowany.
Wiedza nie tylko siedzi w modelu lub przepływie pracy.
Jest dotykana.
Zostaje skrócone.
Miesza się to z innym kontekstem.
Powtarza się to, aż pierwotny kształt staje się trudniejszy do zauważenia.
To tutaj pojawia się pomysł wyników stanu wiedzy, który zaczyna mieć znaczenie dla OpenLedger Token.
Na pierwszy rzut oka, to brzmi jak prosty problem z jakością danych.
Dobre dane są użyteczne, złe dane nie są.
Ale pod tym wszystkim, problem jest bardziej dziwny niż to.
Kawałek wiedzy może być na początku użyteczny, a potem stać się słabszy po zbyt wielu cyklach AI.
Staranna korekta może przekształcić się w ogólną zasadę.
Kulturowy detal może stać się płaskim wyjaśnieniem.
Silny wgląd ludzki może być wykorzystywany tak wiele razy, że teraz wydaje się jak szablon.
To nie jest normalne starzenie się.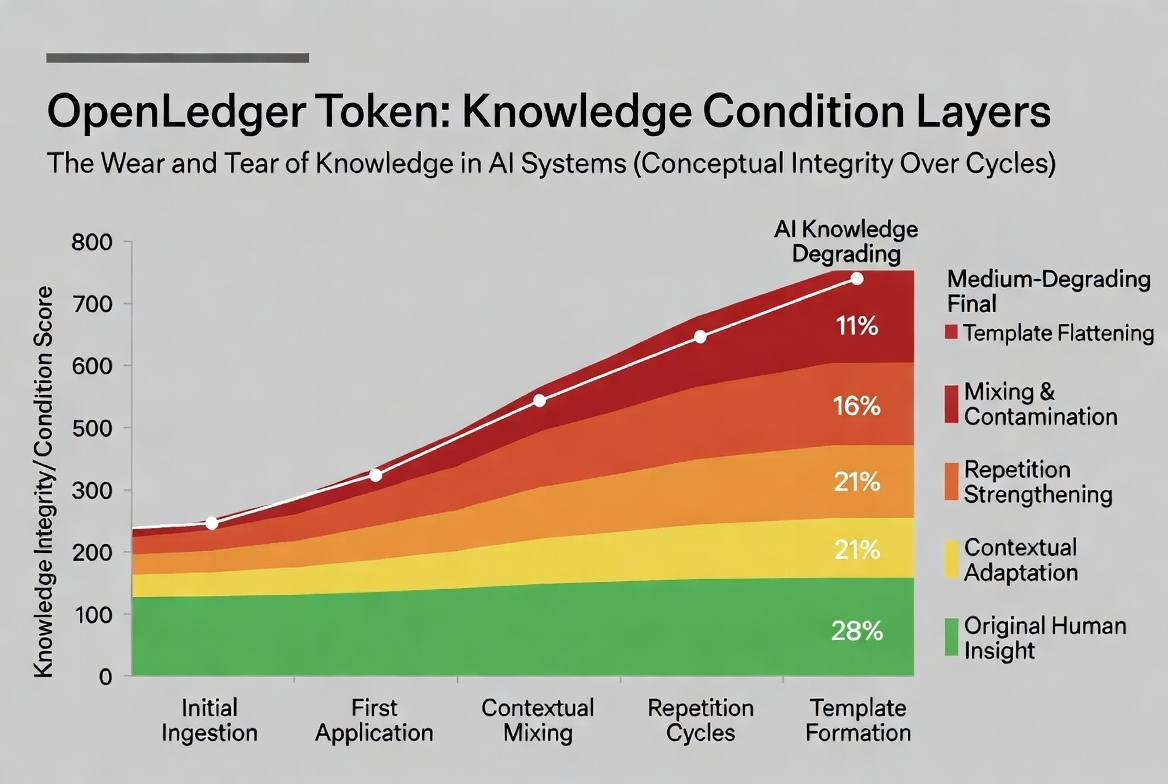
Starzenie się oznacza, że świat zmienił się wokół informacji.
Zużycie oznacza, że system uszkodził ją przez wielokrotne przetwarzanie.
Wciąż wracam do tej różnicy.
Ponieważ gospodarki AI często nagradzają pierwszy moment wkładu.
Kto dodał dane.
Kto dał feedback.
Kto szkolił sygnał.
Kto stworzył użyteczny wkład.
Ta część ma znaczenie, oczywiście.
Ale może to nie wystarczyć dla systemu, który stale recyklinguje wiedzę na dużą skalę.
OpenLedger Token staje się bardziej interesujący, gdy pytanie zmienia się z własności na stan.
Nie tylko kto stworzył tę wiedzę, ale w jakim stanie jest ona po ponownym wykorzystaniu.
Wynik stanu nie byłby wynikiem popularności.
Popularność mówi nam, co podróżuje szeroko.
Stan mówi nam, czy rzecz nadal niesie jasność źródła, kontekst, atrybucję, świeżość i znaczenie.
Ta mała różnica zmienia całą warstwę zachęt.
Jeśli wiedza jest w dobrym stanie, może wspierać lepsze wyniki i czystsze koordynacje.
Jeśli jest w niskim stanie, może wciąż wyglądać na użyteczną z zewnątrz, ale pod spodem może tworzyć leniwe odpowiedzi, słabą weryfikację i cichą zniekształcenie.
Istnieje rozsądny przypadek dla przeciwnego punktu widzenia.
Niektórzy mogą powiedzieć, że AI już to obsługuje poprzez aktualizacje, ranking i feedback.
Może to częściowo prawda.
Ale nie traktowałbym tego jeszcze jako dowodu.
Feedback może poprawić system, ale może też ukryć, skąd pochodziła oryginalna wartość.
Ranking może ujawniać, co działa, ale nie zawsze tłumaczy, co zostało spłaszczone po drodze.
Ta część pozostaje niejasna.
Dla OpenLedger Token, silniejsza narracja to nie głośna prędkość ani większa wydajność.
To cicha struktura wokół śledzenia.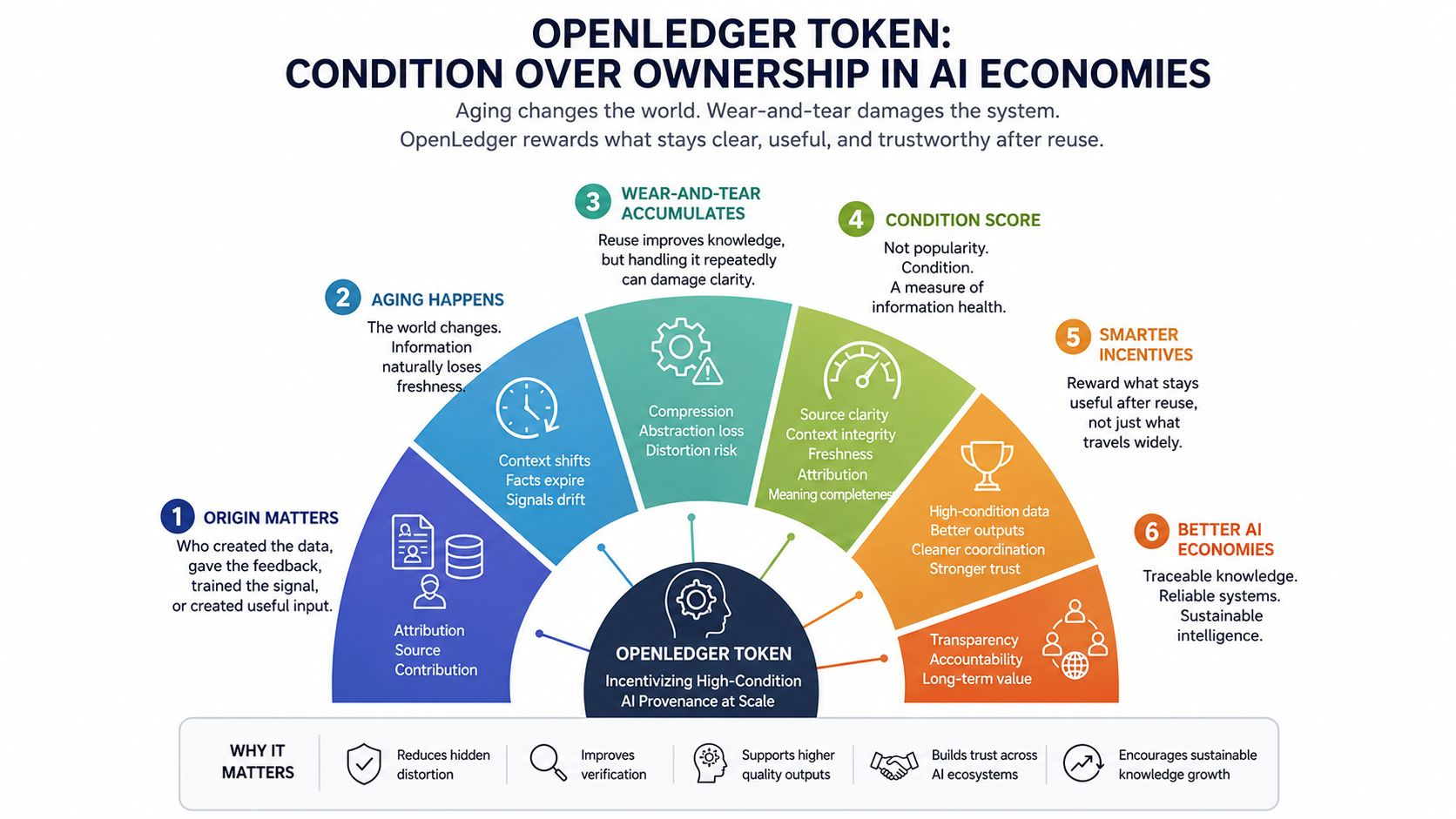
Śledzenie oznacza, że system może śledzić, jak wiedza się poruszała, kto ją dotknął, co się zmieniło i czy zmiana poprawiła lub osłabiła sygnał.
To proste w języku, ale trudne w praktyce.
Ponieważ gdy wiedza przemieszcza się przez zbiory danych, agentów, podpowiedzi, korekty i wyniki, granica staje się nieczytelna.
Ryzyko jest łatwe do przeoczenia.
Rynek może nagradzać wolumen, podczas gdy powoli traci precyzję.
Może wyglądać na produktywne, podczas gdy jego baza wiedzy staje się zmęczona.
Może tworzyć więcej odpowiedzi, ale mniej prawdziwego zrozumienia.
To może nadal zawieść w praktyce, jeśli ocena stanu stanie się kolejną niejasną etykietą.
Wyniki bez audytu stają się dekoracją.
Audyt tutaj po prostu oznacza sposób sprawdzenia, dlaczego wynik istnieje, a nie tylko akceptację, ponieważ system tak mówi.
Więc prawdziwa wartość leżałaby w ograniczeniu.
Kto może aktualizować wiedzę.
Kto może naprawić kontekst.
Kto może ponownie zweryfikować stare sygnały.
Kto jest uprawniony do zarabiania wartości, gdy wiedza pozostaje użyteczna po presji.
To tam OpenLedger Token wydaje się bardziej jak infrastruktura koordynacyjna niż tylko historia wkładu.
Rynek może powoli przechodzić od nagradzania nowych informacji do nagradzania utrzymywanych informacji.
Mniej hałasu.
Więcej stanu.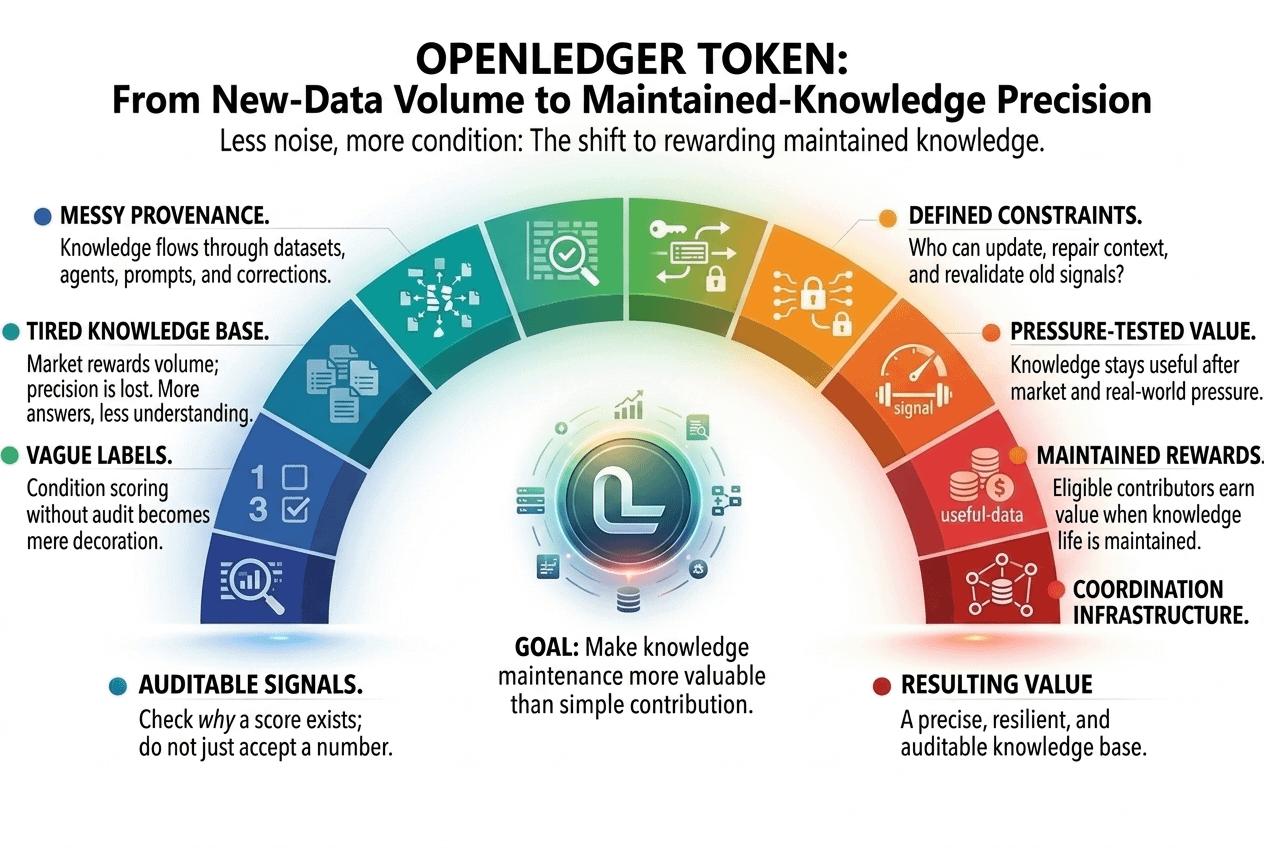
Wiedza ma okres przydatności tylko wtedy, gdy nikt jej nie naprawia.
\u003cm-77/\u003e\u003ct-78/\u003e
\u003cc-148/\u003e
\u003cc-205/\u003e

\u003cc-210/\u003e
