it was a beta program for a domain-specific model in the legal space.
they wanted expert feedback. i had the domain knowledge. seemed like a fair exchange -my time and expertise for the satisfaction of contributing to something that might actualy get better because of it 😂
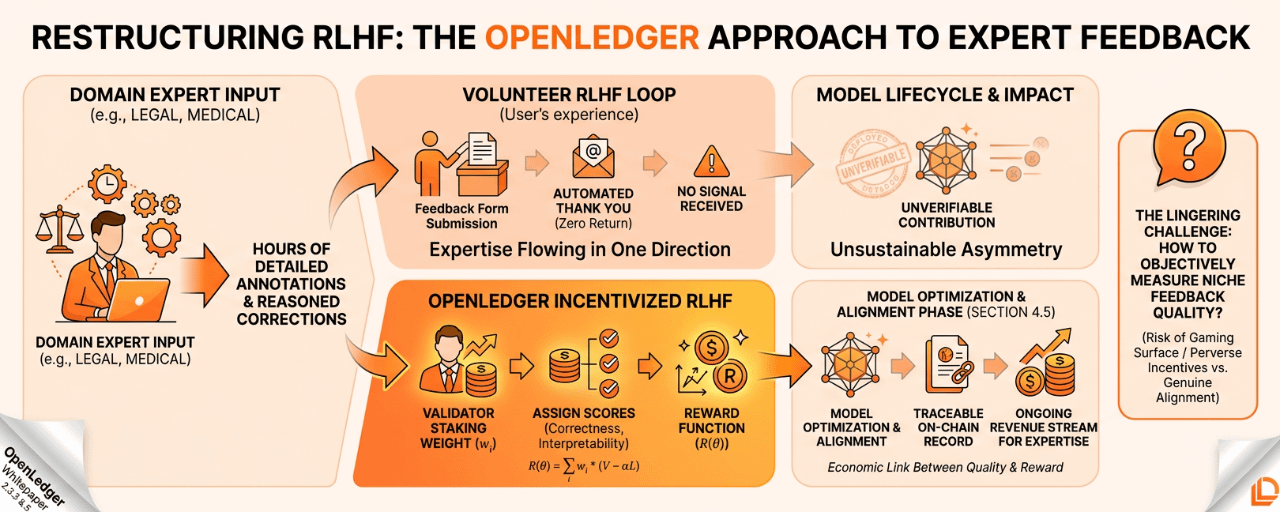
i spent about an hour on it. detailed annotations.carefully reasoned corrections. explanations of why certain outputs were wrong in ways that required genuine legal understanding to identify.i submitted everything through their feedback form.
then nothing.
no signal that the feedback was recieved meaningfully. no indication that any of my corrections influenced the next version.no reward. n0 acknowledgment beyond an automated thankyou email. the model improved in subsequent versions - i think - but i had no way to trace whether anything i'd contributed had anything to do with those improvments.
i stopped after two sessions . not because i stopped caring about model quality. because the asymmetry was unsustainable.my expertise flowing in one direction with nothing flowing back.
that dynamic is exactly what OpenLedger's RLHF integration is designed to restructure from the ground up...
Section 2.3.3 of the whitepaper introduces the reward function for model updates through reinforcement learning with human feedback.it isn't just a technical description of how models improve. it's an economic contract between the protocol and the people doing the improving.
here's how it actualy works. validators ,human participants who evaluate model outputs — assign scores based on correctness and interpretability. these scores feed into the reward function: R(theta) = sum of wi times (V(yi,f_theta(xi)) minus alpha times L(yi, f_theta(xi))).wi is the validator''s staking weight. V measures validator-assigned quality scores. L is the loss function with alpha as a regularisation parameter preventing overfitting.
the staking weight component is the piece that changes everything...
validators who provide high-quality feedback - feedback that genuinly improves model reasoning in verifyable ways - earn stake incentives.validators who attempt to manipulate the system or provide low-quality signal face stake slashing.the protocol creates a direct economic link between the quality of your feedback and the reward you recieve for providing it.
think about what this means for someone with genuine domain expertise in a niche field...
a specialist in ophthalmology, maritime law, semiconductor fabrication,, rare disease diagnosis -anyone whose knowledge is genuinly hard to acquire and genuinly valuable for model improvement -now has a mechanism to earn from that expertise not just once but continuosly. every RLHF session where their feedback measurabley improves model output generates stake rewards. their expertise becomes an ongoing revenue stream not a one-time donation.
and the alignment implications are significant beyond just the economics...
models trained with economicaly incentivised human feedback have a diferent quality of signal than m0dels trained with volunteer feedback or synthetic feedback.the validator has skin in the game.their stake depends on the accuracy and usefullness of their assessment. low-effort feedback gets punished financhially.genuine expertise gets rewarded financhially. the incentive structure and the alignment goal point in the same direction.
Section 4.5 of the whitepaper describes this as the model optimisation and alignment phase - a distinct step in the model lifecycle that happens after fine-tuning and before deployment. it isn't optional. it's structuraly required for a model to advance through the OpenLedger lifecycle.
i keep thinking about that hour i spent annotating legal model outputs with zero return...
if that had happened inside OpenLedger's RLHF system,my staking weIght as a domain validator would have increased with each high-quality session.my earnings would have compounded. and the model would have a verifyable record of which validators shaped its alignment - traceable,on-chain, permanent.
the thing i genuinly wonder about is the gaming surface though. stake slashing for low-quality feedback assumes the protocol can objectively evaluate feedback quality. but in niche domains, who decides whether a validator's correction was right? if the model itself is used to evaluate feedback quality, you have a circular dependency. if human reviewers evaluate validators, you need validators to evaluate the validators...
honestly dont know if RLHF with economic stakes produces genuinely better domain-specific model alignment than volunteer feedback, or if the stake-slashing mechanism creates perverse incentives where validators play it safe with obvious corrections and avoid the nuanced high-value feedback that would actually move model quality forward??
